
Fig. 1.
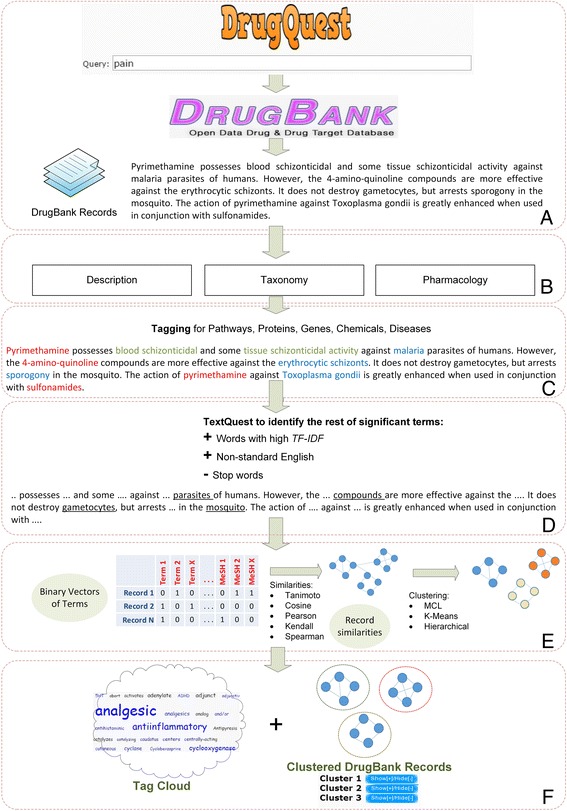
DrugQuest’s workflow. a Queries to DrugBank and retrieval of records related to the query. b DrugBank record mining based on textual information such as: description, toxicology and pharmacology. c Name Entity Recognition techniques to identify genes/proteins, chemicals, diseases, pathways. d TextQuest algorithm to identify non tagged Significant Terms. e Partitional clustering of DrugBank records using various clustering algorithms and similarity measures. f Visual representation of results: Left: Tag cloud example of highly representative terms per cluster. Right: DrugBank records assigned to clusters