
Fig. 1.
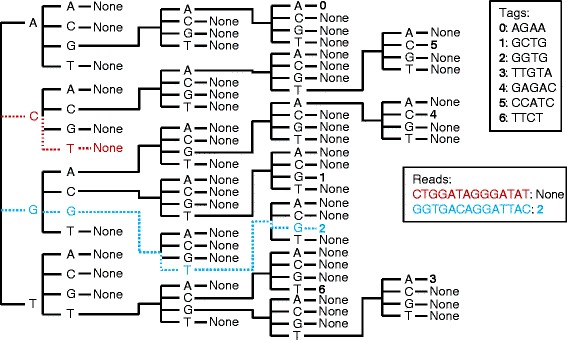
Graphical representation of a sequence indexing tree generated by TagDigger. Use of the tree to match sequencing reads to known tags is illustrated. The red read does not match any known tags, and it takes two steps (looking at the first two nucleotides of the read) to make this determination. The blue read matches one of the expected tags, and it takes four steps to make the match. In comparison, if every read were compared to every tag, seven steps (one for each possible tag) would be required for every read. The maximum number of steps required to match a read will always be the length of the longest tag, which is advantageous when there are thousands of possible tags that are each 40–80 nucleotides long