
Fig. 3.
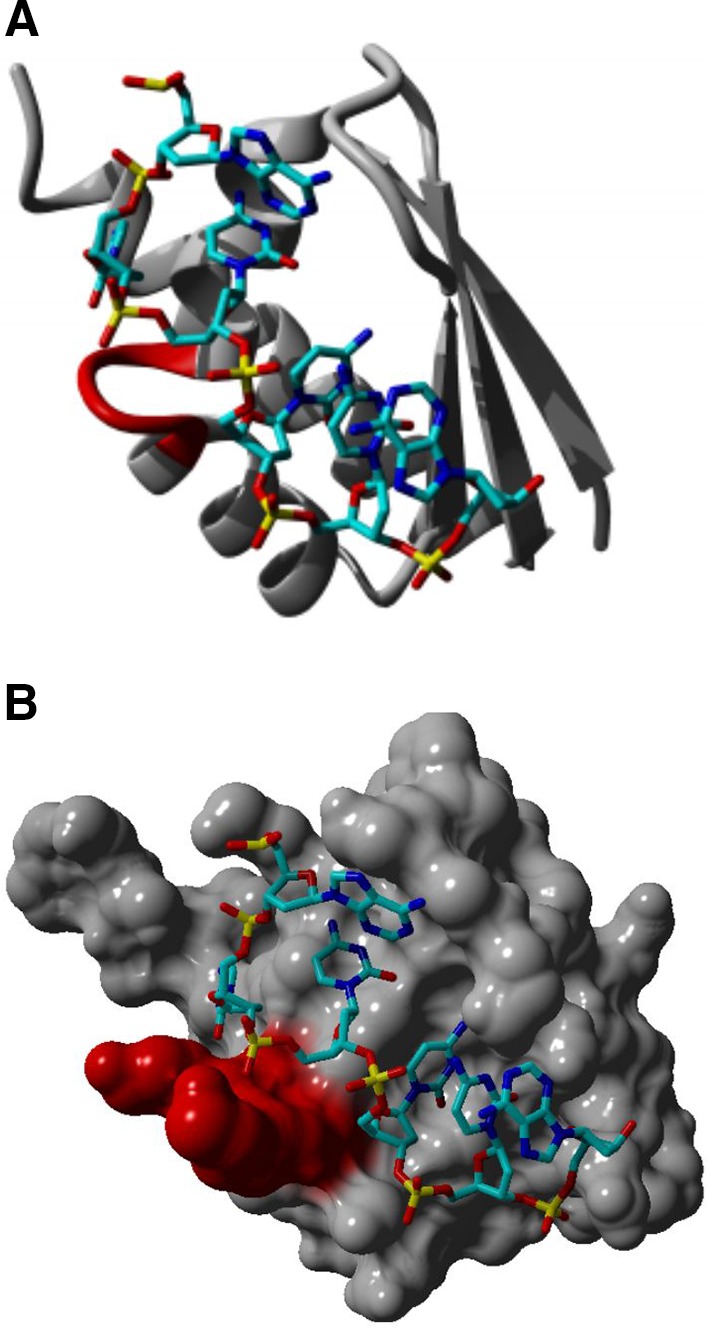
KH–RNA interaction. The KH domain was identified in multiple RNA-binding proteins and characterized by a 45 amino acid repeat that can be split into two groups. The Type I KH domains have a βα extension in their C-terminus, whereas the Type II KH domains have an αβ extension in their N-terminus. The core region of the KH domain is characterized by three-stranded antiparallel β-sheets together with three α-helices (βααββα). It is believed that the nucleotide recognition of the KH domain is determined by a conserved GxxG loop (highlighted in red) in the nucleotide stretch that links two α-helices in the KH core (a). This leads to the orientation of four nucleotides toward the groove in the protein structure where the nucleotide (backbone colored in light and dark blue) recognition is mainly determined by hydrophobic interactions and hydrogen bonds. Besides sequence-specific recognition, the overall shape of the KH hydrophobic groove, which is determined by the conformation of multiple side chains, is equally important in KH–RNA recognition (b). It was shown by using surface plasmon resonance that the KH domain shows a high affinity for poly(C) repeats, more specifically, the affinity was higher for C-tetrads than for C-triplets. Protein modeling was performed based on the crystal structure of a KH domain bound to a TCCCT DNA sequence, pdb file, 3VKE, and by using the Yasara software (http://www.yasara.org)