
Fig. 4.
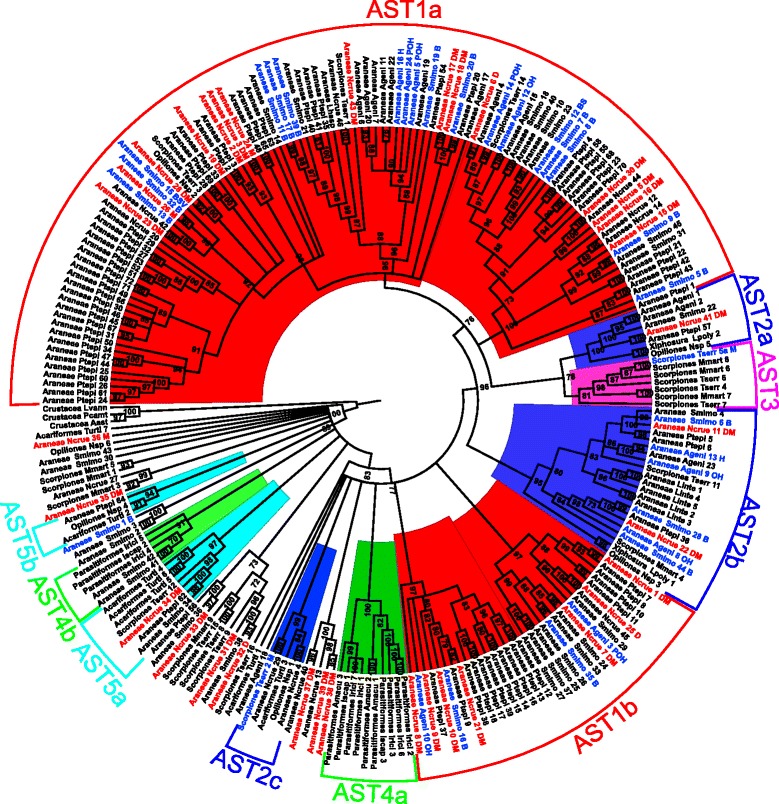
Phylogenetic analysis of arachnid astacin DNA sequences using Maximum Likelihood algorithm. UFBoot values (1000 pseudoreplicates) are shown for each node. Colored proteins in red or blue were identified by mass spectrometry in the present work or by other authors [5, 16], respectively. Letters after sequence names indicate tissue location by mass spectrometry, B, whole body; V, venom; S, silk glands; D, digestive fluid; M, midgut diverticula; O, opisthosoma; P, prosoma; H, hemolymph. Sequences were named with a number after an abbreviation used for each species as follows: Smimo, Stegodyphus mimosarum; Ptepi, Parasteatoda tepidariorum; Ncrue, Nephilingis cruentata; Ageni, Acanthoscurria geniculata; Lhesp; Latrodectus hesperus; Tserr, Tityus serrulatus; Mmart, Mesobuthus martensii; Iscap, Ixodes scapularis; Irici, Ixodes ricinus; Amacu, Amblyomma maculatum; Turti, Tetranychus urticae; Lpoly, Limulus polyphemus; Aast, Astacus astacus; Lvann, Litopenaeus vannamei; Pcamt, Paralithodes camtschaticus. Additional file 11 shows the accession number or contig IDs to all sequences used