
Figure 4.
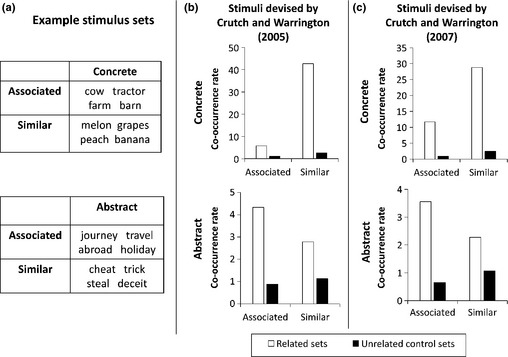
Lexical co‐occurrence rates for concrete and abstract words with different semantic relationships. (a) Examples of stimulus sets used by Crutch and colleagues to investigate similarity‐based and associative semantic relationships. (b, c) Lexical co‐occurrence rates in the British National Corpus for the stimulus sets used by Crutch and Warrington (2005, 2007). Co‐occurrence rates were calculated by computing how often each pair of words in each stimulus set co‐occurred in the corpus (within a 100‐word window) and dividing this by the expected co‐occurrence rate if co‐occurrences occurred by chance alone. This controls for the fact that higher frequency words are more likely to co‐occur by chance, even if their distributions are unrelated (Juteson & Katz, 1991).