
Figure 7. Comparison of supervised learning error ratios to clustering identity of data.
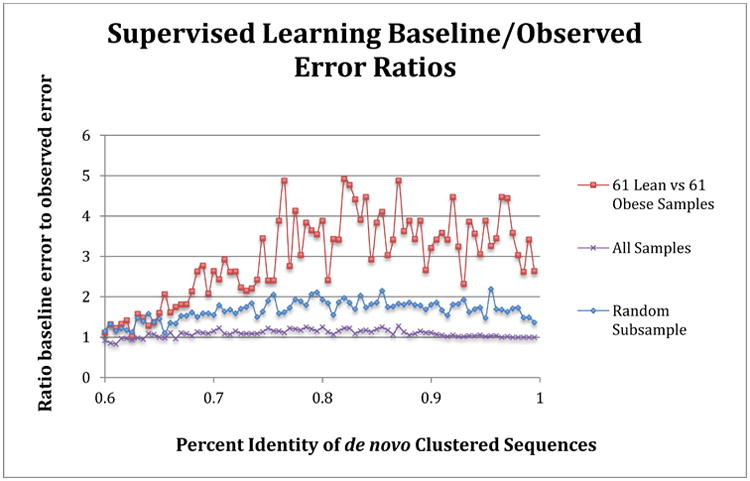
Samples matching those used in Knights et al [9] replicated the improved classifications relative to random guessing (value of 1) for lean and obese subjects in the Turnbaugh [8] study, and are shown as the red line. The average error ratio for a random subsample of 30 obese and lean samples (10× sample at each percent identity, average ratio is shown) is depicted in blue. The purple line shows the classification error ratio when all samples (61 lean versus 196 obese samples), which is essentially no better than random guess for any clustering identity. The sequences were clustered using a de novo approach for each percent identity listed.