
Figure 4.
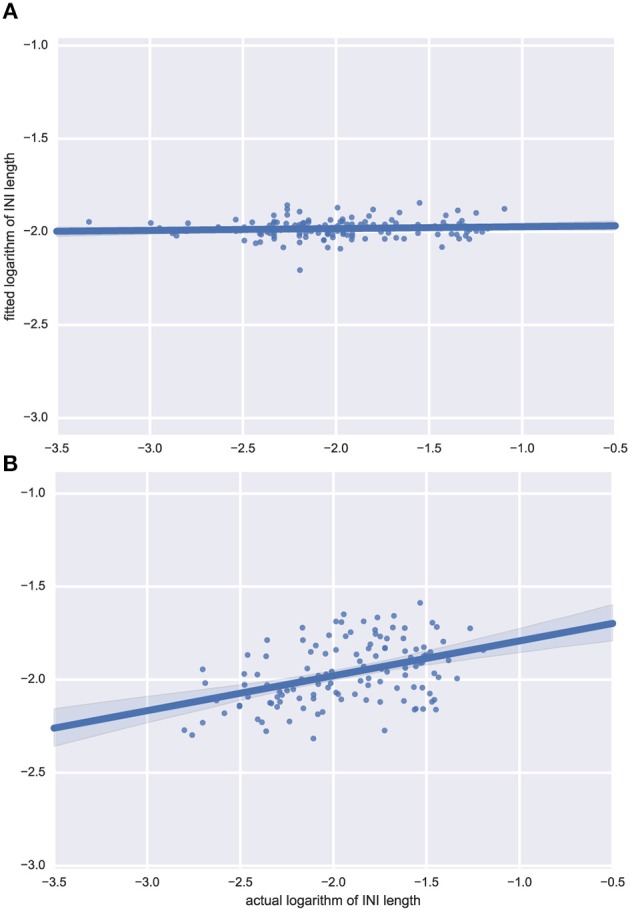
Examples of model predictions for two languages. Fitted model predictions for (A) Japanese and (B) Dutch, showing that even one of the best fits amongst all languages, Dutch, only captures a limited amount of temporal structure. For some other languages (such as Japanese) ARMA does not manage to make better predictions than values slightly varying around the mean INI. Actual data points (logarithms of INI durations) on the x-axis, vs. predictions of the fitted model on the y-axis; perfect predictions would correspond to a diagonal (45°) line.