
Figure 1.

Bayesian Markov model training automatically adapts the effective number of parameters to the amount of data. In the last line, if the context GCT is so frequent at position j in the motif that its number of occurrences outweighs the pseudocount strength, nj(GCT) ≫ α3, the third-order probabilities for this context will be roughly the maximum likelihood estimate, e.g. 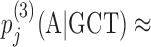 nj(GCTA)/nj − 1(GCT). However, if few GCT were observed in comparison with the pseudocounts, nj(GCT) ≪ α3, the third-order probabilities will fall back on the second-order estimate,
nj(GCTA)/nj − 1(GCT). However, if few GCT were observed in comparison with the pseudocounts, nj(GCT) ≪ α3, the third-order probabilities will fall back on the second-order estimate, 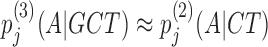 . If also nj(CT) ≪ α2, then likewise the second-order estimate will fall back on the first-order estimate, and hence
. If also nj(CT) ≪ α2, then likewise the second-order estimate will fall back on the first-order estimate, and hence 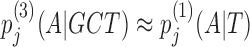 . In this way, higher-order dependencies are only learned for the fraction of k-mer contexts that occur sufficiently often at one position j in the motif's training instances to trump the pseudocounts. Throughout this work we set α0 = 1 and αk = 20 × 3k − 1.
. In this way, higher-order dependencies are only learned for the fraction of k-mer contexts that occur sufficiently often at one position j in the motif's training instances to trump the pseudocounts. Throughout this work we set α0 = 1 and αk = 20 × 3k − 1.