
Figure 3. Grid of algorithm hyper-parameters γ and λ versus Root Mean Square Error (RMSE) scores for the V dataset for the C-diamond case study.
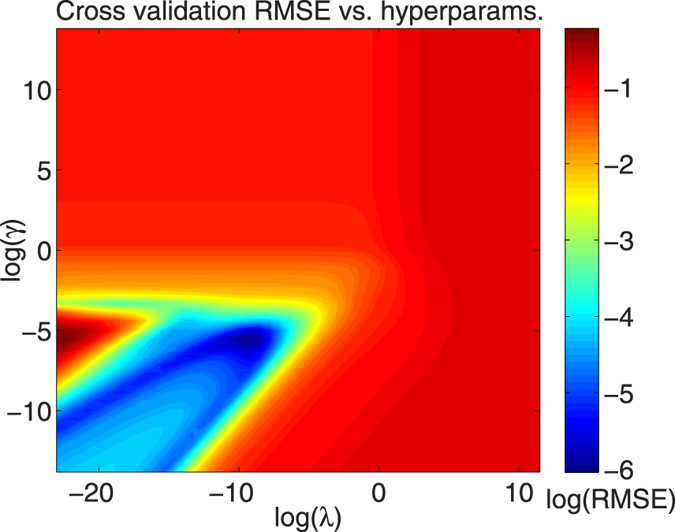
A large number of possible combinations of hyper-parameters result in a similar range of RMSE and can be used for training weight α. We used the combination that provided the lowest RMSE across both case studies.