
Figure 2.
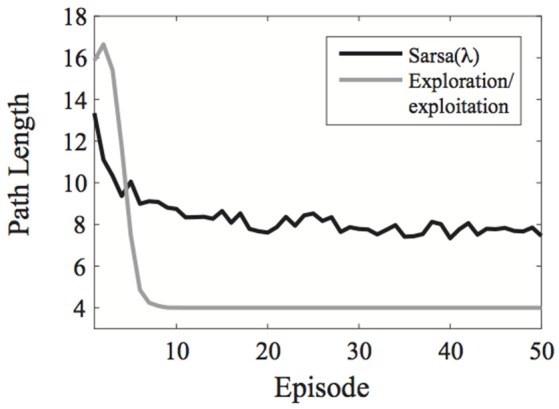
Comparison of the exploration/exploitation model with the Sarsa(λ) model for the learning environment used in Experiment 1. The exploration/exploitation algorithm quickly converges on the optimal path to the goal and continues exploiting it, while the Sarsa(λ) performs well initially, but takes much longer to converge on the optimal path to the goal, even when using an ε-greedy action selection rule. Here, each line represent averages over 500 simulated experiments. Plots show the best possible performance for each algorithm over the entire parameter space [three parameters for Sarsa(λ) and one for the exploration/exploitation algorithm].