
FIGURE 8.
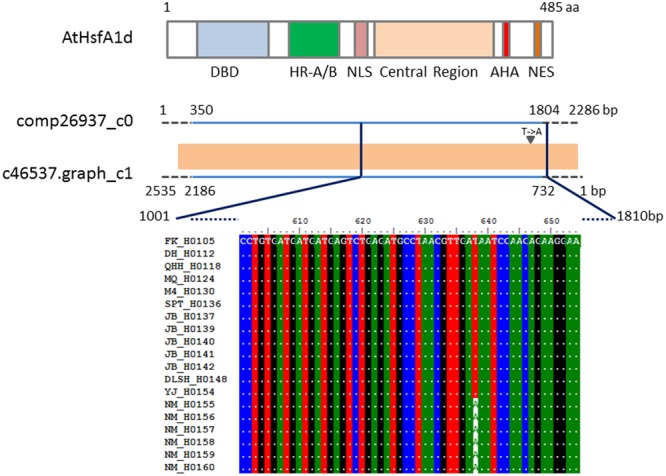
Schematic of Arabidopsis and sand rice HsfA1d protein structure and multiple sequence alignment results. The Arabidopsis HsfA1d protein (AtHsfA1d) structure is adapted from Ohama et al. (2015); the DNA-binding domain (DBD), oligomerization domain (HR-A/B), nuclear localization signal (NLS), transactivation domain (AHA), and nuclear export signal (NES) are indicated. Based on the RBH results, one previously assembled Unigene sequence (comp26937_c0, 2286 bp; Zhao et al., 2014) and one Unigene identified in this study (c46537.graph_c1, 2535 bp) are indicated by lines. The orange rectangle represents a region of identity between the two Unigenes. Sky-blue lines represent similar regions (350–1804 bp in comp26937_c0 and 2186–732 bp in c46537.graph_c1) between the AtHsfa1d protein and sand rice Unigenes. The vertical dark blue lines indicate the fragment (1001–1810 bp), that was amplified from sand rice samples from 10 natural populations. The multiple sequence alignment includes all of the successful sequencing results for the JB and NM populations, along with representative sequences from each of the eight other populations. The arrowhead indicates the T/A SNP.