
Figure 4.
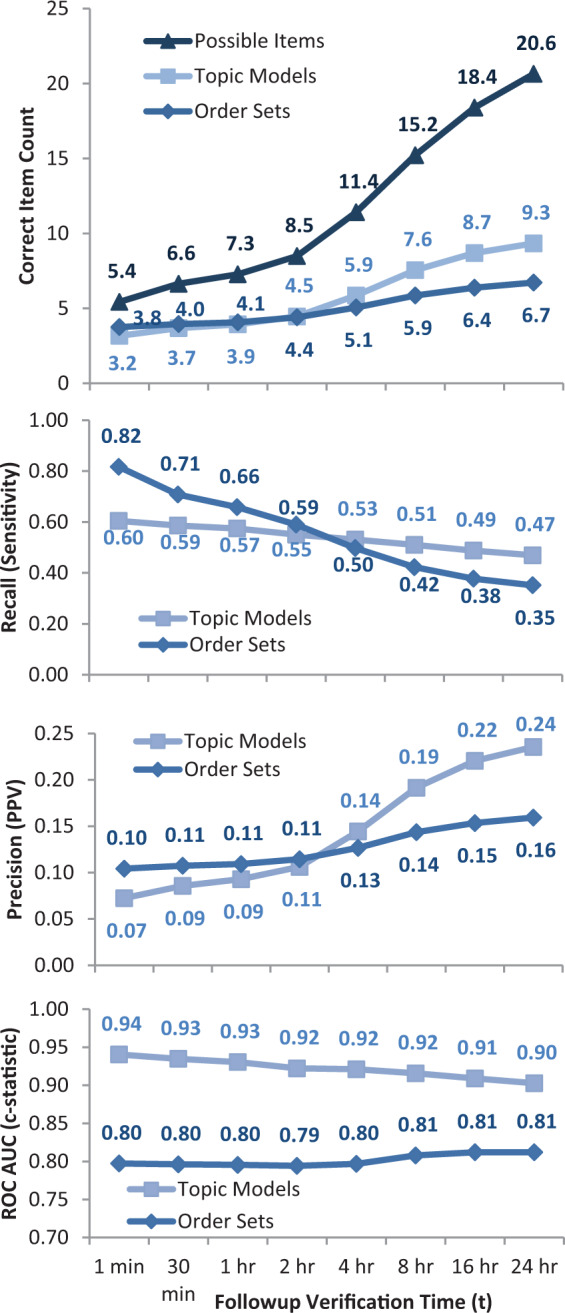
(A) Topic models vs order sets for different followup verification times. For each real use of a preauthored order set, either that order set or a topic model (with 32 trained topics) was used to suggest clinical orders. For longer followup times, the number of subsequent possible items considered correct increases from an average of 5.4–20.6. The average correct predictions in the immediate timeframe is similar for topic models (3.2) and order sets (3.8), but increases more for topic models (9.3) vs order sets (6.7) when forecasting up to 24 hours. At the time of order set usage, physicians choose an average of 3.8 orders out of 54.8 order set suggestions, as well as 1.6 = (5.4 – 3.8) a la carte orders. (B) Topic models vs order sets by recall at N. For longer followup verification times, more possible subsequent items are considered correct (see 4A). This results in an expected decline in recall (sensitivity). Order sets, of course, predict their own immediate use better, but lag behind topic model-based approaches when anticipating orders beyond 2 hours (P < 10−20 for all times). (C) Topic models vs order sets by precision at N. For longer followup verification times, more subsequent items are considered correct, resulting in an expected increase in precision (positive predictive value). Again, topic model-based approaches are better at anticipating clinical orders beyond the initial 2 hours after order set usage (P < 10−6 for all times). (D) Topic models vs order sets by ROC AUC (c-statistic), evaluating the full ranking of possible orders scored by topic models or included/excluded by order sets (P < 10−100 for all times).