
| Box 3 | Clustering |
Clustering is the unsupervised learning process of identifying distinct groups of objects (clusters) in a dataset (Duda et al. 2000). There are two main types of clustering: hierarchical and partitional. Hierarchical clustering algorithms start by calculating all the pair-wise similarities between samples and then building a dendrogram by iteratively grouping the most similar sample pairs. By cutting the tree at an appropriate height, the samples are grouped into clusters. On the other hand, partitional clustering optimizes the number of simple models to fit the data. Examples of partitional clustering include k-means, Gaussian mixture models (GMMs), density-based clustering, and graph-based methods.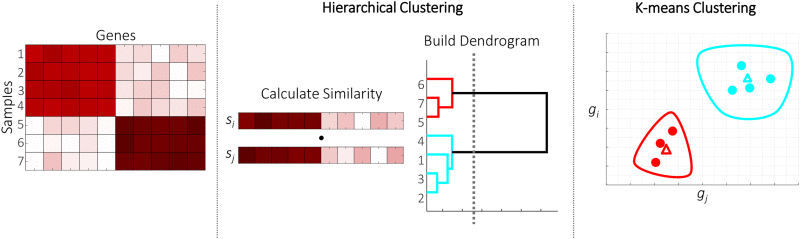
|
| In order to cluster the samples hierarchically, all the pair-wise similarities between sample Si and Sj are calculated. Samples are then grouped iteratively based on the calculated similarities (grouping the most similar first). Once the full dendrogram is built, a cut-off (dashed line) is used to group samples into groups. For k-means we set the number of clusters based on the data heatmap. K-means groups samples by minimizing the within-cluster sum of square distances between each point in the cluster and the cluster center. |
Official websites use .gov
A
.gov website belongs to an official
government organization in the United States.
Secure .gov websites use HTTPS
A lock (
) or https:// means you've safely
connected to the .gov website. Share sensitive
information only on official, secure websites.