
Figure 2.
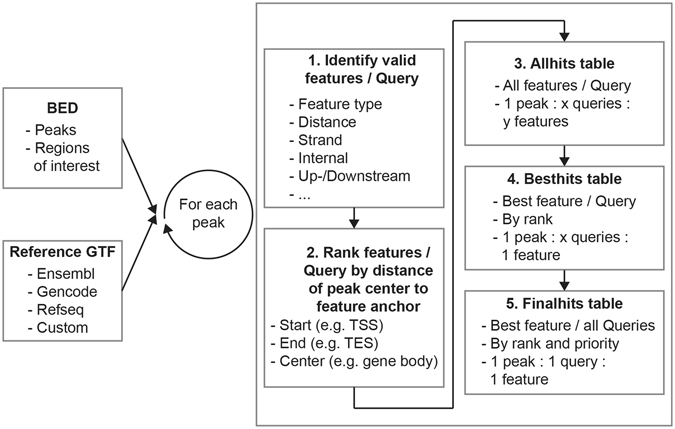
Outline of the UROPA algorithm. (1) For each peak all queries are consecutively checked for features satisfying various optional criteria. (2) The resulting candidate features are ranked for each query based on the distance of the peak center to the feature anchor(s) of interest (e.g. start, end, center of the feature). (3) All candidate features resulting from any query are stored in the”all hits” table. (4) The best candidate feature for each query is stored in the “best hits” table. (5) Only the one best feature among all queries is stored in the “final hits” table. This step can optionally include prioritization of queries to ensure a desired precedence (e.g. prefer protein_coding genes even if they are located farther away from the peak). These three output files cover various granularities considering the desired outcome.