
Fig. 2. Predictions of individual perception.
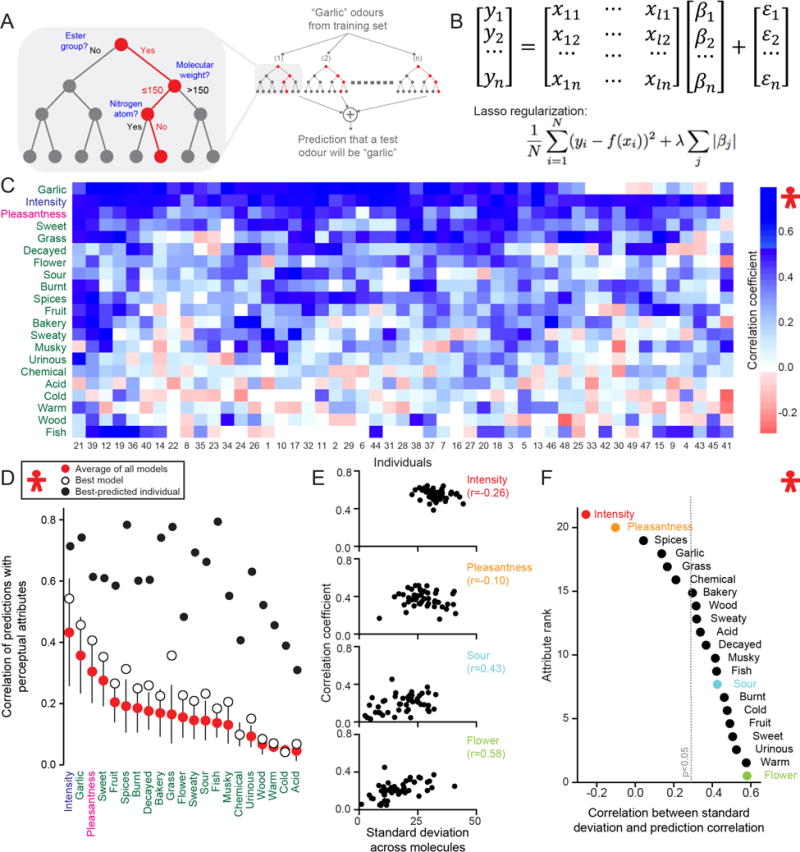
(A) Example of a random-forest algorithm that utilizes a subset of molecules from the training set to match a semantic descriptor (e.g “garlic”) to a subset of molecular features. (B) Example of a regularized linear model. For each perceptual attribute yi a linear model utilizes molecular features xij weighted by βi to predict the psychophysical data of 69 hidden test set molecules, with sparsity enforced by the magnitude of λ. (C) Correlation values of best-performer model across 69 hidden test set molecules, sorted by Euclidean distance across 21 perceptual attributes and 49 individuals. (D) Correlation values for the average of all models (red dots, mean ± s.d.), best-performing model (white dots), and best-predicted individual (black dots), sorted by the average of all models. (E) Prediction correlation of the best-performing random-forest model plotted against measured standard deviation of each subject’s perception across 69 hidden test set molecules for the four indicated attributes. Each dot represents one of 49 individuals. (F) Correlation values between prediction correlation and measured standard deviation for 21 perceptual attributes across 49 individuals, color coded as in E. The dotted line represents the p < 0.05 significance threshold obtained from shuffling individuals.