

Abstract
The bulb-type lectins are proteins consist of three sequential beta-sheet subdomains that bind to specific carbohydrates to perform certain biological functions. The active states of most bulb-type lectins are dimeric and it is thus important to elucidate the short- and long-range recognition mechanism for this dimer formation. To do so, we perform comparative sequence analysis for the single- and double-domain bulb-type lectins abundant in plant genomes. In contrast to the dimer complex of two single-domain lectins formed via protein-protein interactions, the double-domain lectin fuses two single-domain proteins into one protein with a short linker and requires only short-range interactions because its two single domains are always in close proximity. Sequence analysis demonstrates that the highly variable but coevolving polar residues at the interface of dimeric bulb-type lectins are largely absent in the double-domain bulb-type lectins. Moreover, network analysis on bulb-type lectin proteins show that these same polar residues have high closeness scores and thus serve as hubs with strong connections to all other residues. Taken together, we propose a potential mechanism for this lectin complex formation where coevolving polar residues of high closeness are responsible for long-range recognition.
Introduction
Plant lectins are carbohydrate-binding proteins that are abundant in seeds, flowers, leaves, roots, and other vegetative non-storage tissues. These lectins are recognized as plant defense proteins because they can specifically target the surface glycan of the epithelial cells lining the intestinal tract of insects and some herbivores1–5. The harmful and toxic effects of glycan binding vary from slight discomfort to even death. As our understanding of lectin-carbohydrate interaction grows, the biological applications of lectins also become much more diverse6. Besides the anti-insect activity, the plant lectins were used as molecular tools to study host-pathogen interactions, cell development and signaling, and many others in biomedical applications7–15.
Plant lectins have been classified into 12 families based on their sequences, fold structures, and carbohydrate binding motifs16–19. The most general features of plant lectins are as follows. (1) The carbohydrate binding domains are evolutionarily related; and (2) lectins typically form dimer or oligomer for their biological activities. However, the recognition mechanism for lectin dimer or oligomer formation remains poorly understood and is the subject of our study.
Such study is becoming feasible given the rich data sources on plant lectin families. First, the known structures of most lectin complex deposited in Protein Data Bank (PDB) enable molecular dynamic simulations and the associated correlation network analysis16, 17. Graph theory concepts such as betweenness and closeness can be brought to bear in identifying critical residues for complex formation. Second, there happen to be abundant single-domain and double-domain lectins in plant genomes for us to distinguish these critical residues in terms of whether they are for short-range or long-range recognitions. In the crowded environment of a cell, one single-domain lectin may need to find the other single-domain interacting partner at a distance to form a dimer. However, such a long-range recognition is no longer required in double-domain lectin where two single-domain lectins are fused into one protein with a short linker and are always in close proximity. We thus perform statistical inference in terms of direct coupling analysis (DCA) on sequence evolution for single- and double-domain lectins to probe the conservation as well as coevolution of the putative critical residue pairs from multiple sequence alignments. These methods together allow us to uncover the protein-protein recognition mechanism.
In this article, we select the bulb-type lectins for detailed computational analysis to gain insights into lectin recognition mechanism18–28. The bulb-type mannose-binding lectin is a beta-prism type II structure. The single-domain or monomer protein contains antiparallel beta-strands with 3-fold symmetry. Two monomers can assemble into a dimer structure by inserting their C-terminal beta-strand tails into each other to form beta-sheets. This particular lectin can also form a double-domain fusion protein via a short linker between two single domains.
Here, we utilize the dynamical network analysis to investigate the structural characteristic of the bulb-type mannose binding protein29–34. The network analysis reveals that the polar residues on the surface with high closeness are responsible for the long-range recognition of dimer formation. This observation is further supported by the direct coupling analysis that shows coevolution of these polar residues in dimer complex but not in double-domain construct. Taken together, these results suggest a new scheme to identify critical residues for bulb-type lectin complex formation that may be reengineered for novel biomedical applications.
Methods
Molecular dynamics simulations
The MD simulations were carried out using the GROMACS software package35. The AMBER03 force field36 and TIP3P37 water solvation model were used for the simulations. A water solvent box of 12 Å was created between the outside of the protein and the edge of the box. All the structures were simulated at the room temperature (300 K). The initial structure was extracted from the PDB database (PDB code: 1KJ1)18 and solvated with water molecules in a periodic rectangular box with a normal saline condition. The SHAKE algorithm was used to constrain all bond lengths38. The long-range electrostatic interactions were treated with the Particle Mesh Ewald method39. The non-bonded (electrostatic and VDW) cutoff range was 8 Å. A time step of 2 fs was used for numerical integration. Before the MD simulation, the entire system was first minimized by steepest descent calculation for 1000 steps followed by 300 ps equilibration. For each state, three 30 ns trajectories were generated. The solvent accessible surface areas were calculated by GETAREA40. The interface area is defined as the accessible surface on each of the two partners that subsequently become inaccessible to solvent in their dimer formation. The structures were visualized and analyzed by VMD and PyMOL41.
Network construction
A dynamical network was constructed by Carma package from the final 20 ns portion of the entire 30 ns trajectories33, 42. A node in the network denotes a single amino acid residue. Two nonconsecutive residues in sequence are connected by an edge if they contain a pair of heavy atoms, one from each residue, less than 4.5 Å apart for at least 75% of the times during the MD simulation. The weight of the edge between two connected nodes i and j is defined as:
| 1 |
with C ij measuring the correlation of motions of nodes i and j:
| 2 |
where is the position vector of the C α atom of the i th amino acid and the brackets indicate the time average. The values of C ij vary from −1 to 1. Since we focused on the nodes moving together in the same direction, we removed the edges if their correlations were from −1 to 0.
Networks analysis
We analyzed the closeness, betweenness, characteristic path length (CPL), and delta path length (DPL) of the coarse-grained dynamical network where only C α atoms of amino acids are used to construct the network. The closeness of a node is defined as the inverse of the sum of its shortest distances to all other nodes as the following:
| 3 |
where d(x, y) is the distance of the shortest path between the node x and any other node y 43. The betweenness of a node x measures its contribution toward the network communication by counting the number of shortest paths between all pairs of nodes that also pass through the node x. The CPL is the average length of the shortest paths between all pairs of nodes. The DPL of a node x is the change of CPL induced by removing the node x. The shortest paths between all pairs of nodes are found using the Floyd-Warshall algorithm.
Sequence evolution analysis
The sequence evolution analysis measures the residue conservation by ConSurf program44. First, we obtained the alignment files (PDB code: 1KJ1, for chain A and chain D) from ConSurf-DB45. To focus on the plant lectins, we filtered the sequences by manually removing all non-plant entries. The final numbers of sequences were 79 for chain A (Table S1) and 82 for chain D (Table S2), respectively. Then, we used the program ClustalW2 to perform the sequence alignment on the filtered sequences46, 47. Lastly, we calculated the residue conservation scores by ConSurf44. The continuous conservation scores are divided into a discrete scale of 9 grades with grade 1–3 for the most variable positions and grade 7–9 for the most conserved positions. The 46 single-domain and 16 double-domain sequences were obtained from the annotations of the homology sequences in UniProt48.
Sequence coevolution analysis
The Direct Coupling Analysis (DCA) was performed to infer the interacting residues by using information on sequence coevolution across different species49–52. The single- and double-domain sequence alignments were listed in two files: Supplementary Info File 2 (SI 2) and Supplementary Info File 3 (SI 3). The MUSCLE53 program was used to perform the sequence alignment. The main steps of DCA are as follows.
Step 1: the columns in multiple sequence alignment (MSA) showing more than 50% gaps are removed.
Step 2: amino acid frequencies for single residue f i(A i) and a pair of residues f ij(A i, A j) are computed by reweighting the M sequences in MSA based on sequence identity as the following:
| 4 |
| 5 |
Here A i (A j) denotes what is at the i th (j th ) location of the sequence of length L, which can be one of the 21 possible choices including 20 actual amino acid types or a gap insertion in MSA. A pseudo-count λ = 0.5 is introduced to treat possible finite sample effect. is the effective number of sequences where m a counts the number of sequences with more than 80% sequence identity to the a th sequence in MSA.
Step 3: the model statistical probabilities of a single residue and a pair of residues in MSA are,
| 6 |
| 7 |
where P(A 1, …, A L) is the global probability of the sequence {A 1, … A L}. Using the maximum-entropy model, the global probability involves the residue-pair interaction energy (pairwise couplings) e ij(A i, A j) and local energy h i(A i),
| 8 |
the normalization factor was defined as Applying the mean-field approximation, the residue-pair interaction energy can be estimated by the inverse of the covariance matrix,
| 9 |
where the covariance matrix is C ij(A i, A j) = P ij(A i, A j)−P i(A i)P j(A j). Since we want to fit the one-site and two-site marginal of P(A 1, …, A L) to the empirical reweighted counting frequency f i(A i) and f ij(A i, A j), we substitute C ij(A i, A j) in the above equation with .
Step 4: the direct couplings are defined as
| 10 |
with the help of an isolated two-site model
| 11 |
and are defined by the empirical single-residue frequency and .
Results
Interface and mannose binding residues are more conserved than other surface residues
The tertiary structure of the garlic bulb-type lectin protein was extracted from PDB database with a resolution of 2.2 Å (PDB code: 1KJ1)18. To understand the structural characteristic, we divide the protein into surface sites, interface sites, mannose-binding sites, and interior sites. A residue is defined as interface if it is solvent exposed in monomer but not solvent exposed in dimer complex. The surface residues are the solvent exposed residues both in monomer and dimer complex (Fig. 1A, Table S3). The solvent accessible surface area of a residue was calculated using the solvent accessible surface recognition program GETAREA (Table S5)40. The mannose binding sites were identified by protein-ligand interaction recognition program LIGPLOT54 (Fig. 1B, Table S4, Figure S2). We then performed sequence evolution analysis to investigate the sequence conservation of surface, interface, and mannose-binding residues in the dimer complex, respectively (see Materials and Methods for details). As shown in Fig. 1C, interface sites (average conservation score = 6.72, standard deviation = 2.46) and mannose binding sites (average conservation score = 6.18, standard deviation = 2.35) are significantly more conserved than the surface sites (average conservation score = 2.84, standard deviation = 1.90). It is believed that the interface residues tend to be more conserved across lectins for the stability of dimer formation while the slightly more varied mannose binding sites are for different mannose-binding specificity.
Figure 1.
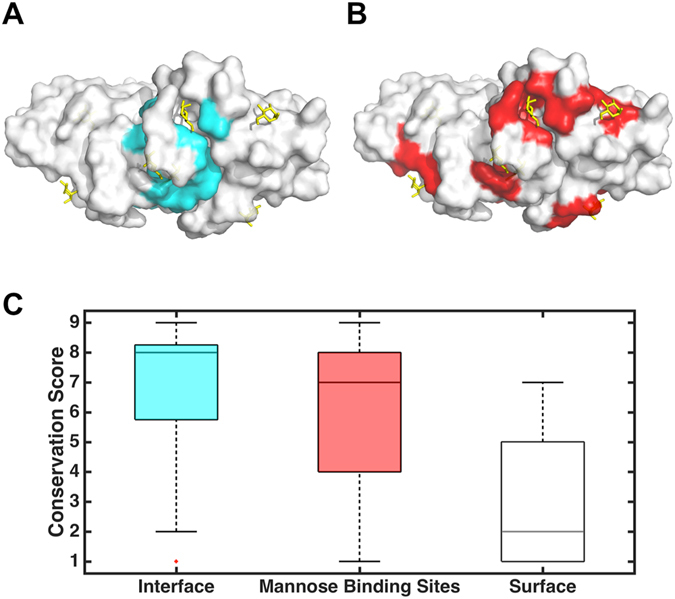
Classification of interface, mannose binding, and surface residues of the garlic mannose-binding lectin protein and their sequence conservation scores. (A) and (B) represent typical mapping of interface and mannose binding residues on a 3D structure, colored in cyan and red, respectively. (C) Distributions of average conservation scores of interface, mannose binding, and surface residues.
Table 1 lists all interacting pairs of the interface. A pair of amino acids across the interface is defined as interacting if the distance of any two heavy atoms, one from each amino acid, is less than 4 Å. As shown in Table 1, most interacting pairs are fairly conserved to maintain the interface stability. However, there is a highly variable pair of polar residues (A:GLU91-D:MET5). Ref. 53 already observed similar phenomena and suggested that such charged pairs should be for long-range steering effect in dimer formation. As discussed further below, a closeness score may provide a quantitative and practical measure to identify this polar pair. Moreover, our finding shows that this polar pair is largely absent in the double-domain fusion proteins. This offers the clearest evidence yet so far in support of this long-range recognition conjecture.
Table 1.
Tertiary interactions within 4 Å at the interface. The interactions were calculated from the garlic mannose-binding lectin crystal structure (PDB code: 1KJ1).
| Chain A | Chain D | Distance (Å) | ||
|---|---|---|---|---|
| Residue | Conservation | Residue | Conservation | |
| GLU91 | 2 | MET5 | 1 | 2.97 |
| ASN94 | 7 | THR105 | 9 | 3.34 |
| ASN94 | 7 | THR107 | 9 | 2.87 |
| TYR98 | 8 | TYR98 | 9 | 3.74 |
| TYR98 | 8 | ASP101 | 6 | 3.49 |
| GLY99 | 7 | GLY99 | 7 | 2.93 |
| GLY99 | 7 | ILE102 | 5 | 3.57 |
| ASP101 | 6 | TYR98 | 9 | 3.96 |
| ILE102 | 5 | GLY99 | 7 | 3.55 |
| SER104 | 8 | ASN94 | 8 | 3.99 |
| THR105 | 9 | ASN94 | 8 | 3.17 |
| THR107 | 9 | ASP92 | 8 | 3.80 |
| THR107 | 9 | ASN94 | 8 | 2.96 |
Network analysis reveals the critical residues for intermolecular communication
The interface residues listed in Table 1 were obtained from the static structure of the dimer complex. It is necessary, however, to go beyond the static configuration to probe the importance of these residues in coordinating the dynamical motion of the entire complex. To this end, we performed the MD simulations and used the simulation trajectories of the complex to construct the dynamical network (see Materials and Methods for details). Given the network, graph theory concepts such as betweeness and delta path length (DPL) can be used to quantify the relative importance of each residue for the network communication between two monomers including some subtle allosteric effect.
First, we performed the betweenness calculation of the dynamic network. To probe the communication in this dynamical network, we identified the shortest path between each and every pair of nodes in the network and defined the betweenness of a node as the number of such shortest paths going through the node. Figure 2 shows the betweenness values in the entire dynamical network of the dimer complex with a Z-score value larger than 1.5. Most of the residues of high betweenness, especially TYR98, are located near interface indicating the importance of these residues in maintaining the correlated dynamics of the dimer complex. As such, it is no surprise that these residues are very conserved with conservation scores higher than 6.
Figure 2.
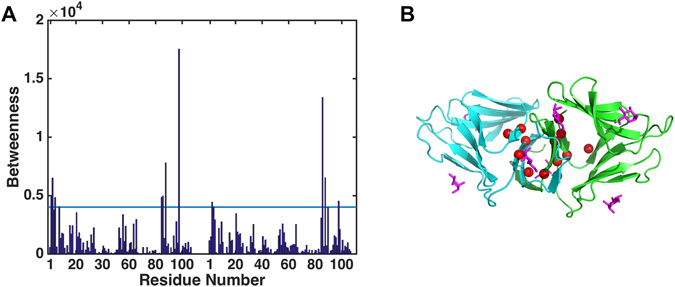
Betweenness centrality of residues in dynamical network. (A) ASN2, LEU3, THR5, GLU8, TYR85, VAL86, VAL88, TYR98 of chain A, and ILE3, LEU4, VAL86, VAL88, TYR98 of chain D have large betweenness with a Z-score greater than a cutoff value of 1.5 (light blue line). (B) The locations of the significant betweenness residues (red spheres). The chain A, chain D, and mannoses are colored in green, cyan, and magenta, respectively. The TYR98 with highest betweenness is the critical residue for intermolecular network communication.
Second, we performed the delta path length (DPL) calculation of the dynamical network. Since betweenness only considers the shortest path, it may overestimate the importance of a node in the network communication where there exist other paths of comparable length such as a very close but distinctive second shortest path. To overcome this potential pitfall, we also computed DPL of a node as the change of the average path length upon removal of the node (see Materials and Method). Figure 3 shows that most residues increase the path length upon their removal from the dynamic network. The values of betweenness and DPL share a high correlation of 0.845. The combined results of both metrics of betweenness and DPL suggest that the highly-conserved residue TYR98 is the critical residue for intermolecular network communication and dimer stability.
Figure 3.
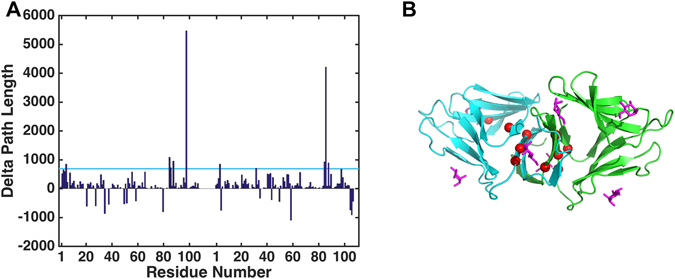
Delta path length of residues in dynamical network. (A) THR5, TYR85, VAL86, VAL88, TYR98 of chain A, and LEU4, VAL32, TYR85, VAL86, VAL88 of chain D have large delta path length with a Z-score greater than a cutoff value of 1.0 (light blue line). (B) The locations of the significant delta path length residues (red spheres). The chain A, chain D, and mannoses are colored in green, cyan, and magentas, respectively. The TYR98 with highest DPL is the critical residue for intermolecular network communication.
Closeness analysis reveals the critical residues for long-range recognition
In a connected graph, a node with small total distance to all other nodes acts as a hub for inter-network communication. To be precise, the closeness of a node is defined as the inverse of the sum of its shortest distances to all other nodes. It was proposed that the residues of high closeness are functional sites since, as network hubs, they can interact effectively with all other residues either directly or through a few intermediates. Indeed, previous benchmark tests showed that closeness scores successfully identified 70% of the protein active sites43.
We further hypothesize that a pair of charged surface residues of high individual closeness value could best exert the long-range steering effect for dimer formation. Since each such residue forms a tighter connection with its own monomer, an attractive interaction for the pair can bring the two monomers together more effectively. To check this, we constructed the dynamic network from the MD simulations of the lectin monomer, and then computed the closeness values of all surface residues and classified them into three categories: (1) most likely recognition sites (high closeness values), (2) likely recognition sites (intermediate closeness values), and (3) unlikely recognition sites (small closeness values). Our results suggested that some residues (THR5, ASP17, and GLU19, colored in red) might be considered as the most likely recognition sites (Fig. 4). The crystal structure of garlic lectin showed that THR5 is responsible for dimer formation18, and the crystal structure of snowdrop lectin indicated that ASP17/GLU19 might be responsible for tetramer formation55. Therefore, structural information on both monomer and complex and their associated network analysis supported our hypothesis that high closeness polar residues on surface might be responsible for long-range protein-protein recognition.
Figure 4.
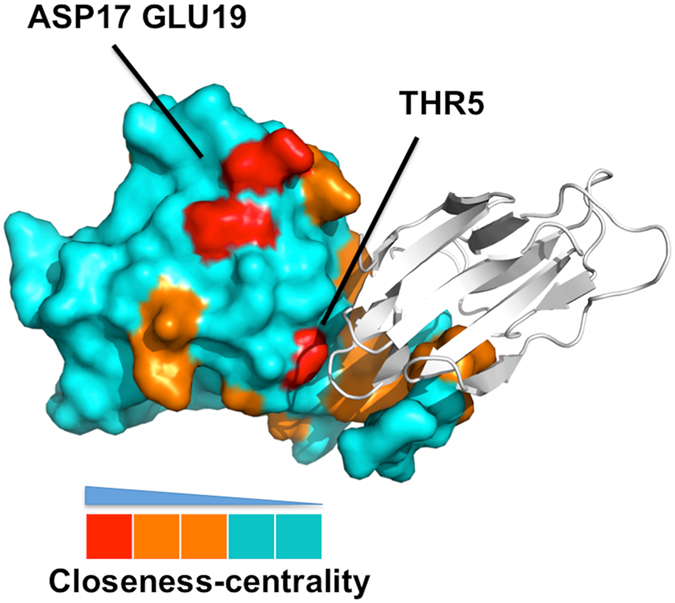
Surface representation of the garlic mannose-binding lectin protein (monomer, chain A). The residues are colored by closeness values with red, orange and cyan corresponding to the high (top 20%), intermediate (20~60%) and low (below than 60%) closeness values. The crystal structure of garlic lectin showed that THR5 is responsible for dimer formation and snowdrop lectin indicated that ASP17/GLU19 might be responsible for tetramer formation.
We analyzed additional representative plant homology sequences in both single- and double-domains of this specific kind of lectin (Supplementary Info 2 and 3). There are four such lectins with known crystal structures (Table S7)56–58. We compared the differences between single- and double-domain lectin proteins: (1) both single-domain lectin protein structures (PDB code: 1MSA and 3A0C) are similar to garlic lectin (PDB code: 1KJ1) with RMSDs around 1.5 Å, while double-domain protein structures (PDB code: 3MEZ and 3R0E) are different with RMSDs larger than 3 Å; (2) the residue-residue interaction of position 5 and position 91 is polar-polar interaction in single-domain lectin proteins but not in double-domain proteins; (3) the residues of position 5 and position 91 are surface residues in single-domain lectin proteins but not in double-domain lectin proteins; and (4) the residue closeness of position 5 is significantly high in single-domain but not in double-domain. These results supported our hypothesis that high closeness polar residues on surface of complex may responsible for long-range protein-protein recognition.
Direct coupling analysis reveals that the polar pair is coevolving
While it is possible to verify the importance of some residues toward the dimer formation via site mutagenesis, it is not clear how to measure if they are for short-range or long-range effect. Fortunately, the abundance of single- and double-domain lectins in plant genomes offers a unique opportunity to verify our hypothesis on long-range recognition mechanism. Unlike the dimeric lectin complex formed via protein-protein interaction of two single-domain lectins, the double-domain lectin is formed by fusing two single-domain lectins into one protein with a short linker and its two single domains are always in close proximity and thus do not require long-range recognition for its formation. Therefore, sequence features present in the single domain but absent in the double domain may be attributed to long-range effect. Specifically, we performed hydrophobic-polar pattern analysis and sequence coevolution analysis for both single- and double-domain lectins at position 91 and 5 to probe GLU91-MET5 pair.
For the hydrophobic-polar pattern analysis, we count the number of different types of interactions. In order to analyze the interaction pattern statistically, we randomly select 31 out of 46 single-domain sequences and 11 out of 16 double-domain sequences to compare the interaction patterns for single- and double-domain lectins, respectively. This calculation is repeated five times. The results indicate that the residues at position 5 and 91 prefer to form polar-polar interaction pairs in single-domain lectins but hydrophobic-hydrophobic interaction pairs in double-domain lectins. Figure 5 shows that dimer complex prefers polar interactions while such charged pair of GLU91-MET5 is largely absent in the double-domain lectins. This is strong evidence that GLU91-MET5 is indeed for long-range steering effect.
Figure 5.
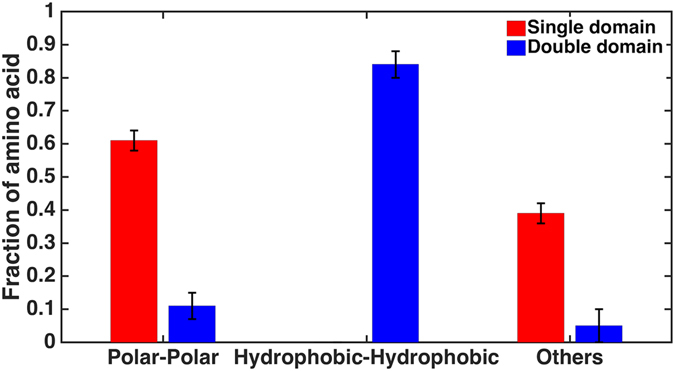
The analysis of interaction pattern between position 5 and 91 for single-domain and double-domain lectins in plant genomes. The red and blue colors are for the single-domain and double-domain lectins, respectively. We randomly select about 31 out of 46 single-domain sequences and 11 out of 16 double-domain sequences and analyze their interaction pattern, respectively. This is repeated five times. The residues at position 5 and 91 prefer to form polar-polar interaction pairs in single-domain lectins but hydrophobic-hydrophobic interaction pairs in double-domain lectins.
Direct Coupling Analysis (DCA) uses a global statistical model of multiple sequence alignments to infer direct interaction from coevolution of residue pairs51, 59, 60. We performed DCA for both single and double domains to identify the coevolving patterns for those residue pairs as displayed in Table 1. In previous coevolution analysis, the number of sequences used was typically comparable to the length of the target protein, and it was found that a DI score of 0.8 indicates a significant co-evolutionary signal61, 62. Therefore, we focused on the 18 residues at interface to perform the coevolution calculation due to the limited sequence information. The results indicate that less conserved residue pairs (with conservation scores less than 8 for both residues in the pair, Table S6) are coevolving in single-domain (with DI score greater than 0.8) but not in double-domain (with DI score less than 0.8). Specifically, the DI scores for GLU91-MET5 pair shows that there is strong correlation between GLU91 and MET5. The GLU91-MET5 pair is coevolved to maintain the interaction for long-range recognition in single-domain.
Discussion and Conclusion
Protein-protein interactions are essential for carrying out various biological functions. Previous large-scale analysis of protein-protein interface of known complexes discovered a surprising pattern of highly variable and charged residue pairs at the interface. It was suggested that these pairs might provide the long-range steering force to bring together interacting proteins for dimer formation. Indeed, some mutagenesis experiments confirmed the importance of these charged pairs on protein surface for dimer formation and binding specificity63–65.
The results from our case study on mannose-binding lectin complex are also consistent with this hypothesis. But beyond the qualitative description, we further proposed three practical and quantitative metrics to pinpoint such charged pairs for long-range recognition among a multitude of charged residues on protein surface without the complete structure of the dimer complex. Specifically, these charged pairs have the following unique features: (1) high closeness in the dynamical network of the monomer; (2) strong direct coupling indicating coevolution in the multiple sequence alignment; and (3) its absence in the double-domain construct. The last two measures above require sequence analysis only.
The identification of critical residue pairs for complex formation has many benefits. These pairs can serve as distance constraints to guide the structure modeling for much better accuracy. They can also facilitate drug design or protein engineering in order to regulate the complex formation for biological or medical applications.
In summary, we developed a hybrid approach of structure modeling, network analysis, and sequence statistical inference to identify critical residues for protein complex formation. Our results suggest that the coevolving polar residue pairs of high closeness initiate the long-range recognition of the bulb-type lectin complex formation that is further stabilized by short-range complementary interactions.
Electronic supplementary material
Acknowledgements
This work was partially supported by National Science Foundation (NSF) grant 0941228 (C.Z.), CAREER 1350766, grant 1618706 (H.H.) and Scientific Research Foundation of Central China Normal University 20205170045 (Y.Z.).
Author Contributions
Y.Z. performed most computational analysis; Y.J. Z.L. performed network analysis with the help pf H.L. and H.H.; Q.L. C.C. Z.L. and L.W. helped with mannose-binding lectins sequences; Y.Z. and C.Z. supervised the overall study, analyzed the data and wrote the paper. All authors edited the manuscript.
Competing Interests
The authors declare that they have no competing interests.
Footnotes
Yunjie Zhao and Yiren Jian contributed equally to this work.
Electronic supplementary material
Supplementary information accompanies this paper at doi:10.1038/s41598-017-03003-5
Publisher's note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
References
- 1.Sharon N, Lis H. History of lectins: from hemagglutinins to biological recognition molecules. Glycobiology. 2004;14:53R–62R. doi: 10.1093/glycob/cwh122. [DOI] [PubMed] [Google Scholar]
- 2.Kery V. Lectin-carbohydrate interactions in immunoregulation. Int J Biochem. 1991;23:631–640. doi: 10.1016/0020-711X(91)90031-H. [DOI] [PubMed] [Google Scholar]
- 3.Peumans WJ, Van Damme EJ. Lectins as plant defense proteins. Plant Physiol. 1995;109:347–352. doi: 10.1104/pp.109.2.347. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Chrispeels MJ, Raikhel NV. Lectins, lectin genes, and their role in plant defense. The Plant Cell. 1991;3:1–9. doi: 10.1105/tpc.3.1.1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Vandenborre G, Smagghe G, Van Damme EJ. Plant lectins as defense proteins against phytophagous insects. Phytochemistry. 2011;72:1538–1550. doi: 10.1016/j.phytochem.2011.02.024. [DOI] [PubMed] [Google Scholar]
- 6.Lam SK, Ng TB. Lectins: production and practical applications. Appl Microbiol Biotechnol. 2011;89:45–55. doi: 10.1007/s00253-010-2892-9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Hirabayashi J. Lectin-based structural glycomics: glycoproteomics and glycan profiling. Glycoconj J. 2004;21:35–40. doi: 10.1023/B:GLYC.0000043745.18988.a1. [DOI] [PubMed] [Google Scholar]
- 8.Paulson JC, Blixt O, Collins BE. Sweet spots in functional glycomics. Nat Chem Biol. 2006;2:238–248. doi: 10.1038/nchembio785. [DOI] [PubMed] [Google Scholar]
- 9.Fry S, Afrough B, Leathem A, Dwek M. Lectin array-based strategies for identifying metastasis-associated changes in glycosylation. Methods Mol Biol. 2012;878:267–272. doi: 10.1007/978-1-61779-854-2_18. [DOI] [PubMed] [Google Scholar]
- 10.Swanson MD, Winter HC, Goldstein IJ, Markovitz DM. A lectin isolated from bananas is a potent inhibitor of HIV replication. J Biol Chem. 2010;285:8646–8655. doi: 10.1074/jbc.M109.034926. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Lam SK, Ng TB. First report of a haemagglutinin-induced apoptotic pathway in breast cancer cells. Biosci Rep. 2010;30:307–317. doi: 10.1042/BSR20090059. [DOI] [PubMed] [Google Scholar]
- 12.Souza MA, Carvalho FC, Ruas LP, Ricci-Azevedo R, Roque-Barreira MC. The immunomodulatory effect of plant lectins: a review with emphasis on ArtinM properties. Glycoconj J. 2013;30:641–657. doi: 10.1007/s10719-012-9464-4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Liu B, Bian HJ, Bao JK. Plant lectins: potential antineoplastic drugs from bench to clinic. Cancer Lett. 2010;287:1–12. doi: 10.1016/j.canlet.2009.05.013. [DOI] [PubMed] [Google Scholar]
- 14.Jiang QL, et al. Plant lectins, from ancient sugar-binding proteins to emerging anti-cancer drugs in apoptosis and autophagy. Cell Prolif. 2015;48:17–28. doi: 10.1111/cpr.12155. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Bies C, Lehr CM, Woodley JF. Lectin-mediated drug targeting: history and applications. Adv Drug Deliv Rev. 2004;56:425–435. doi: 10.1016/j.addr.2003.10.030. [DOI] [PubMed] [Google Scholar]
- 16.Berman HM, et al. The Protein Data Bank. Nucleic Acids Res. 2000;28:235–242. doi: 10.1093/nar/28.1.235. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Rose PW, et al. The RCSB Protein Data Bank: views of structural biology for basic and applied research and education. Nucleic Acids Res. 2015;43:D345–356. doi: 10.1093/nar/gku1214. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Ramachandraiah G, Chandra NR, Surolia A, Vijayan M. Re-refinement using reprocessed data to improve the quality of the structure: a case study involving garlic lectin. Acta Crystallogr D. 2002;58:414–420. doi: 10.1107/S0907444901021497. [DOI] [PubMed] [Google Scholar]
- 19.Van Damme EJ, et al. Phylogenetic and specificity studies of two-domain GNA-related lectins: generation of multispecificity through domain duplication and divergent evolution. Biochem J. 2007;404:51–61. doi: 10.1042/BJ20061819. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Ghequire MG, Loris R, De Mot R. MMBL proteins: from lectin to bacteriocin. Biochem Soc Trans. 2012;40:1553–1559. doi: 10.1042/BST20120170. [DOI] [PubMed] [Google Scholar]
- 21.Milner JA. Garlic: its anticarcinogenic and antitumorigenic properties. Nutr Rev. 1996;54:S82–86. doi: 10.1111/j.1753-4887.1996.tb03823.x. [DOI] [PubMed] [Google Scholar]
- 22.Raskin I, et al. Plants and human health in the twenty-first century. Trends Biotechnol. 2002;20:522–531. doi: 10.1016/S0167-7799(02)02080-2. [DOI] [PubMed] [Google Scholar]
- 23.Banerjee N, et al. Functional alteration of a dimeric insecticidal lectin to a monomeric antifungal protein correlated to its oligomeric status. PloS one. 2011;6:e18593. doi: 10.1371/journal.pone.0018593. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Clement F, Venkatesh YP. Dietary garlic (Allium sativum) lectins, ASA I and ASA II, are highly stable and immunogenic. Int Immunopharmacol. 2010;10:1161–1169. doi: 10.1016/j.intimp.2010.06.022. [DOI] [PubMed] [Google Scholar]
- 25.Clement F, Pramod SN, Venkatesh YP. Identity of the immunomodulatory proteins from garlic (Allium sativum) with the major garlic lectins or agglutinins. Int Immunopharmacol. 2010;10:316–324. doi: 10.1016/j.intimp.2009.12.002. [DOI] [PubMed] [Google Scholar]
- 26.Schafer G, Kaschula CH. The immunomodulation and anti-inflammatory effects of garlic organosulfur compounds in cancer chemoprevention. Anticancer Agents Med Chem. 2014;14:233–240. doi: 10.2174/18715206113136660370. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Arreola R, et al. Immunomodulation and anti-inflammatory effects of garlic compounds. J Immunol Res. 2015;2015:401630. doi: 10.1155/2015/401630. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Karasaki Y, Tsukamoto S, Mizusaki K, Sugiura T, Gotoh S. A garlic lectin exerted an antitumor activity and induced apoptosis in human tumor cells. Food Res Int. 2001;34:7–13. doi: 10.1016/S0963-9969(00)00122-8. [DOI] [Google Scholar]
- 29.Zhao Y, et al. Automated and fast building of three-dimensional RNA structures. Sci Rep. 2012;2:734. doi: 10.1038/srep00734. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Wang J, Zhao Y, Zhu C, Xiao Y. 3dRNAscore: a distance and torsion angle dependent evaluation function of 3D RNA structures. Nucleic Acids Res. 2015;43:e63. doi: 10.1093/nar/gkv141. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Zhao Y, Zeng C, Massiah MA. Molecular dynamics simulation reveals insights into the mechanism of unfolding by the A130T/V mutations within the MID1 zinc-binding Bbox1 domain. PloS one. 2015;10:e0124377. doi: 10.1371/journal.pone.0124377. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Zhao Y, et al. A new role for STAT3 as a regulator of chromatin topology. Transcription. 2013;4:227–231. doi: 10.4161/trns.27368. [DOI] [PubMed] [Google Scholar]
- 33.Sethi A, Eargle J, Black AA, Luthey-Schulten Z. Dynamical networks in tRNA:protein complexes. Proc Natl Acad Sci USA. 2009;106:6620–6625. doi: 10.1073/pnas.0810961106. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Chen H, et al. Break CDK2/Cyclin E1 interface allosterically with small peptides. PLoS One. 2014;9:e109154. doi: 10.1371/journal.pone.0109154. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35.Van Der Spoel D, et al. GROMACS: fast, flexible, and free. Journal of computational chemistry. 2005;26:1701–1718. doi: 10.1002/jcc.20291. [DOI] [PubMed] [Google Scholar]
- 36.Duan Y, et al. A point-charge force field for molecular mechanics simulations of proteins based on condensed-phase quantum mechanical calculations. J Comput Chem. 2003;24:1999–2012. doi: 10.1002/jcc.10349. [DOI] [PubMed] [Google Scholar]
- 37.Mahoney MW, Jorgensen WL. A five-site model for liquid water and the reproduction of the density anomaly by rigid, nonpolarizable potential functions. J Chem Phys. 2000;112:8910–8922. doi: 10.1063/1.481505. [DOI] [Google Scholar]
- 38.Jean-Paul Ryckaert GC, Herman JCB. Numerical integration of the cartesian equations of motion of a system with constraints: molecular dynamics of n-alkanes. J. Chem. Phys. 1977;23:327–341. [Google Scholar]
- 39.Darden T, York D, Pedersen L. Particle mesh Ewald: An N⋅log(N) method for Ewald sums in large systems. J. Chem. Phys. 1993;98:10089–10092. doi: 10.1063/1.464397. [DOI] [Google Scholar]
- 40.Fraczkiewicz R, Braun W. Exact and efficient analytical calculation of the accessible surface areas and their gradients for macromolecules. Journal of Computational Chemistry. 1998;19:319–333. doi: 10.1002/(SICI)1096-987X(199802)19:3<319::AID-JCC6>3.0.CO;2-W. [DOI] [Google Scholar]
- 41.Humphrey, W., Dalke, A. & Schulten, K. VMD: visual molecular dynamics. Journal of molecular graphics14, 33–38, 27–38 (1996). [DOI] [PubMed]
- 42.Glykos NM. Software news and updates. Carma: a molecular dynamics analysis program. Journal of computational chemistry. 2006;27:1765–1768. doi: 10.1002/jcc.20482. [DOI] [PubMed] [Google Scholar]
- 43.Amitai G, et al. Network analysis of protein structures identifies functional residues. J Mol Biol. 2004;344:1135–1146. doi: 10.1016/j.jmb.2004.10.055. [DOI] [PubMed] [Google Scholar]
- 44.Ashkenazy H, Erez E, Martz E, Pupko T, Ben-Tal N. ConSurf 2010: calculating evolutionary conservation in sequence and structure of proteins and nucleic acids. Nucleic acids research. 2010;38:W529–533. doi: 10.1093/nar/gkq399. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45.Goldenberg O, Erez E, Nimrod G, Ben-Tal N. The ConSurf-DB: pre-calculated evolutionary conservation profiles of protein structures. Nucleic acids research. 2009;37:D323–327. doi: 10.1093/nar/gkn822. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46.Larkin MA, et al. Clustal W and Clustal X version 2.0. Bioinformatics. 2007;23:2947–2948. doi: 10.1093/bioinformatics/btm404. [DOI] [PubMed] [Google Scholar]
- 47.McWilliam H, et al. Analysis Tool Web Services from the EMBL-EBI. Nucleic acids research. 2013;41:W597–600. doi: 10.1093/nar/gkt376. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 48.UniProt C. UniProt: a hub for protein information. Nucleic acids research. 2015;43:D204–212. doi: 10.1093/nar/gku989. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 49.Caleb Weinreb AJR, John BI, Torsten G, Chris Sander DSM. 3D RNA and Functional Interactions from Evolutionary Couplings. Cell. 2016;165:963–975. doi: 10.1016/j.cell.2016.03.030. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50.De Leonardis E, et al. Direct-Coupling Analysis of nucleotide coevolution facilitates RNA secondary and tertiary structure prediction. Nucleic Acids Res. 2015;43:10444–10455. doi: 10.1093/nar/gkv932. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 51.Morcos F, et al. Direct-coupling analysis of residue coevolution captures native contacts across many protein families. Proc Natl Acad Sci USA. 2011;108:E1293–1301. doi: 10.1073/pnas.1111471108. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 52.Morcos F, Hwa T, Onuchic JN, Weigt M. Direct coupling analysis for protein contact prediction. Methods in molecular biology. 2014;1137:55–70. doi: 10.1007/978-1-4939-0366-5_5. [DOI] [PubMed] [Google Scholar]
- 53.Edgar RC. MUSCLE: multiple sequence alignment with high accuracy and high throughput. Nucleic acids research. 2004;32:1792–1797. doi: 10.1093/nar/gkh340. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 54.Wallace AC, Laskowski RA, Thornton JM. LIGPLOT: a program to generate schematic diagrams of protein-ligand interactions. Protein Eng. 1995;8:127–134. doi: 10.1093/protein/8.2.127. [DOI] [PubMed] [Google Scholar]
- 55.Hester G, Kaku H, Goldstein IJ, Wright CS. Structure of mannose-specific snowdrop (Galanthus nivalis) lectin is representative of a new plant lectin family. Nat Struct Biol. 1995;2:472–479. doi: 10.1038/nsb0695-472. [DOI] [PubMed] [Google Scholar]
- 56.Wright CS, Kaku H, Goldstein IJ. Crystallization and preliminary X-ray diffraction results of snowdrop (Galanthus nivalis) lectin. J Biol Chem. 1990;265:1676–1677. [PubMed] [Google Scholar]
- 57.Ding J, Bao J, Zhu D, Zhang Y, Wang DC. Crystal structures of a novel anti-HIV mannose-binding lectin from Polygonatum cyrtonema Hua with unique ligand-binding property and super-structure. J Struct Biol. 2010;171:309–317. doi: 10.1016/j.jsb.2010.05.009. [DOI] [PubMed] [Google Scholar]
- 58.Shetty KN, Bhat GG, Inamdar SR, Swamy BM, Suguna K. Crystal structure of a beta-prism II lectin from Remusatia vivipara. Glycobiology. 2012;22:56–69. doi: 10.1093/glycob/cwr100. [DOI] [PubMed] [Google Scholar]
- 59.Weigt M, White RA, Szurmant H, Hoch JA, Hwa T. Identification of direct residue contacts in protein-protein interaction by message passing. Proc Natl Acad Sci USA. 2009;106:67–72. doi: 10.1073/pnas.0805923106. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 60.Ovchinnikov S, Kamisetty H, Baker D. Robust and accurate prediction of residue-residue interactions across protein interfaces using evolutionary information. Elife. 2014;3:e02030. doi: 10.7554/eLife.02030. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 61.Marks DS, Hopf TA, Sander C. Protein structure prediction from sequence variation. Nat Biotechnol. 2012;30:1072–1080. doi: 10.1038/nbt.2419. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 62.Hopf, T. A. et al. Sequence co-evolution gives 3D contacts and structures of protein complexes. Elife3 (2014). [DOI] [PMC free article] [PubMed]
- 63.Zhang Q, Zmasek CM, Godzik A. Domain architecture evolution of pattern-recognition receptors. Immunogenetics. 2010;62:263–272. doi: 10.1007/s00251-010-0428-1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 64.Wu W, Ahlsen G, Baker D, Shapiro L, Zipursky SL. Complementary chimeric isoforms reveal Dscam1 binding specificity in vivo. Neuron. 2012;74:261–268. doi: 10.1016/j.neuron.2012.02.029. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 65.Li, S. A., Cheng, L. N., Yu, Y. M. & Chen, Q. Structural basis of Dscam1 homodimerization: Insights into context constraint for protein recognition. Sci Adv2 (2016). [DOI] [PMC free article] [PubMed]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.