

Abstract
Findings from an increasingly large number of studies have been used to argue that attentional capture can be dependent on the learned value of a stimulus, or value-driven. However, under certain circumstances attention can be biased to select stimuli that previously served as targets, independent of reward history. Value-driven attentional capture, as studied using the training phase-test phase design introduced by Anderson and colleagues, is widely presumed to reflect the combined influence of learned value and selection history. However, the degree to which attentional capture is at all dependent on value learning in this paradigm has recently been questioned. Support for value-dependence can be provided through one of two means: (1) greater attentional capture by prior targets following rewarded training than following unrewarded training, and (2) greater attentional capture by prior targets previously associated with high compared to low value. Using a variant of the original value-driven attentional capture paradigm, Sha and Jiang (2016) failed to find evidence of either, and raised criticisms regarding the adequacy of evidence provided by prior studies using this particular paradigm. To address this disparity, here we provided a stringent test of the value-dependence hypothesis using the traditional value-driven attentional capture paradigm. With a sufficiently large sample size, value-dependence was observed based on both criteria, with no evidence of attentional capture without rewards during training. Our findings support the validity of the traditional value-driven attentional capture paradigm in measuring what its name purports to measure.
Keywords: selective attention, attentional capture, reward learning, selection history
Decades of research firmly support the idea that the automatic capture of attention is influenced by both the current goals of the observer (i.e., (goal)-contingent attentional capture; e.g., Folk, Remington, & Johnston, 1992; Serences et al., 2005) and the physical salience of stimuli (e.g., Theeuwes, 1992, 2010). The idea that attentional capture can be uniquely driven by learned value (i.e., value-driven) is much more recent (Anderson, Laurent, & Yantis, 2011b). In order to study value-driven attention, Anderson and colleagues (2011b) developed what has come to be referred to as the value-driven attentional capture paradigm, which utilizes a training phase-test phase design. Specifically, in the training phase, participants are provided (often monetary) rewards for finding feature- (often color) defined targets; participants then complete an unrewarded test phase in which the prior target-defining feature(s) are explicitly task-irrelevant. Critically, in the test phase, a non-target is rendered in the color of a formerly reward-predictive target (referred to as a valuable distractor) on some trials. Slowing of response time (RT) when the valuable distractors are present compared to distractor-absent trials is taken as evidence of attentional capture by the distractors (see Anderson, 2013).
Value-driven attention has become a topic of great interest in the field, popularizing the use of the value-driven attentional capture paradigm (see Anderson, 2016b, for a recent review). However, the usefulness of this paradigm in measuring attentional capture that is value-driven, the very thing it purports to measure, has recently been questioned (Sha & Jiang, 2016). Given the widespread use of the paradigm in attention research and the claims that rest on its assumptions, this is a serious criticism that demands careful consideration. The criticism has two primary components, which will be addressed in turn:
Does the Presence of Reward During Training Actually Matter?
Without any explicit reward feedback, simply locating a target repeatedly over trials can give rise to attentional biases that mirror value-driven attention (e.g., Kyllingsbaek, Schneider, & Bundesen, 2001; Kyllingsbaek, Van Lommel, Sorensen, & Bundesen, 2014; Qu, Hillyard, & Ding, in press; Shiffrin & Schneider, 1977). It was traditionally thought that such selection history biases require substantial training to develop, typically thousands of trials over multiple days (Kyllingsbaek et al., 2001, 2014; Shiffrin & Schneider, 1977). However, statistically significant attentional biases for former targets have more recently been measured using much shorter single-session training, the length of which was more comparable to the length of training used in value-driven attentional capture studies (Lin, Lu, & He, 2016; Sha & Jiang, 2016; Wang et al., 2013). If significant attentional biases can be measured without reward feedback following a single session of training, the question arises as to whether the reward feedback actually modulates attentional capture in the value-driven attentional capture paradigm.
Earlier studies on value-driven attention were sensitive to this potential criticism (e.g., Anderson et al., 2011a, 2011b), although rigorous tests of value-dependence were often lacking. No significant attentional capture was observed using an unrewarded but otherwise identical version of the value-driven attentional capture paradigm in the original demonstration (Anderson et al., 2011b), although it has been suggested that this could be the due to the study's small sample size (Sha & Jiang 2016). Furthermore, a direct comparison between the (lack of) capture in the unrewarded version and the purportedly value-driven attentional capture in the rewarded version of the task was lacking (although see Reanalysis of Anderson et al. (2011b) section).
Other studies including an unrewarded version of the training phase were subsequently published, showing either no (Anderson, 2016c; Anderson et al., 2012, 2014a; Qi et al., 2013; see also Anderson, 2015b) or small but reliable (Wang et al., 2013) capture by former targets. In some studies, direct comparisons between rewarded and unrewarded training were shown to be significant (Anderson et al., 2011a; Roper & Vecera, 2016; Sali, Anderson, & Yantis, 2014; Wang et al., 2013). However, in these studies with direct comparisons, modifications to the original paradigm were used, leading some to question the degree to which such findings might generalize to the specific conditions frequently used in the traditional implementation of the paradigm (Sha & Jiang, 2016). Using a design similar to the original value-driven attentional capture paradigm (although, see General Discussion for some differences), Sha and Jiang (2016) showed significant attentional capture by former target colors following unrewarded training that did not differ in magnitude from capture following otherwise equivalent rewarded training, compounding this potential criticism.
Does the Magnitude of Reward During Training Actually Matter?
Perhaps the most clear-cut evidence that can be provided in favor of value-dependence should demonstrate a difference in the magnitude of attentional capture that parallels a difference in learned value between stimuli. If distractors previously associated with high reward capture attention to a greater degree than distractors previously associated with comparatively low reward, the difference between the two must be attributed to the difference in value. Both stimuli served as targets in the same context, such that target/selection history and even global motivational factors linked to the availability of reward (although see Sali et al., 2014) cannot explain any difference in capture.
However, the difference in capture between distractors of different specific values during training is notoriously small, especially in the most common implementations of the value-driven attentional capture paradigm. Capture by the high-value distractor is often on the order of 10-20 ms, leaving little room for variation along this metric (see Anderson, 2013). The magnitude of the capture effect in general is perhaps unsurprising, as the value-driven attentional capture paradigm intentionally “stacks the deck” in favor of no capture by the distractor in order to make strong claims about automaticity. That is, the target is more physically salient than the distractor, whose defining feature is explicitly task-irrelevant and never (not even incidentally) coincides with the target (Anderson et al., 2011b). This powerful design is perhaps what gives the paradigm its widespread appeal, but, as Sha and Jiang (2016) indicate, it can also create ambiguity in the interpretation of capture, particularly when the former criterion for value-dependence has not been explicitly met.
The original demonstration of value-driven attentional capture (Anderson et al., 2011b) did not contain a direct comparison of distractors of relative value (although see Reanalysis of Anderson et al. (2011b) section), relying instead on the unrewarded control condition. In certain other experiments utilizing this paradigm, the comparison was explicitly not significant (e.g., Anderson & Yantis, 2012; Anderson et al., 2013b; Laurent, Hall, Anderson, & Yantis, 2015). However, many clear cases of value dependence have been observed using the training phase-test phase design along the lines of Anderson and colleagues (e.g., Anderson, 2015a, 2015b, 2016a, 2016b; Anderson & Yantis, 2013; Anderson et al., 2011a, 2012a, 2016b; Belopolsky & Theeuwes, 2012; Failing & Theeuwes, 2014; Hickey & Peelen, 2015; Jiao et al., 2015; Mine & Saiki, 2015; Moher, Anderson, & Song, 2015; Pool, Brosch, Delplanque, & Sander, 2014; Roper, Vecera, & Vaidya, 2014), demonstrating a difference in attentional capture that corresponds with a difference in the learned value of the distractor; at least three of these studies have involved a near-identical replication of the original paradigm (Anderson et al., 2016b; Jiao et al., 2015; Roper et al., 2014; see also Anderson et al., 2016c, for correlations between striatal dopamine and this measure of value-dependence). As Sha and Jiang (2016) point out, though, these compelling demonstrations use a variety of specific design features, dependent measures, reward manipulations, and study populations that differ from the original study of Anderson et al. (2011b).
So, although the concept of value-dependence in the control of attention is robustly supported as a theoretical principle, the utility of the traditional value-driven attentional capture paradigm in its assessment (at least of college-age participants) can, understandably, be questioned. Given the widespread use of this paradigm and the claims that have been made on its basis, such criticism should be seriously considered, especially in light of Sha and Jiang's (2016) recent study, which failed to observe an influence of the relative value of the distractors on the capture of attention.
Rationale for the Present Study
Given the large number of studies that have rested their conclusions concerning value-dependence on the assumptions of the traditional value-driven attentional capture paradigm (see Anderson, 2016b), we thought it necessary to firmly establish its ability to measure attentional capture that is truly value-dependent. To this end, we replicated the original value-driven attentional capture study (Anderson et al., 2011b; see also Anderson et al., 2014b) with a larger sample size in an effort to establish whether a critical difference in capture between high- and low-value distractors is present. Evidence affirming such a difference would support the theory that learned value indeed contributes to the magnitude of capture observed for high-value distractors.
Experiment 1
Experiment 1 was a direct replication of the paradigm introduced by Anderson et al. (2011b), with a larger sample size (n = 40). Given its substantially wider use in the field, we used the shorter version of the task (Experiment 3, 240 trials in each phase).
Methods
Participants
Forty participants were recruited from the Johns Hopkins University community. All reported normal or corrected-to-normal visual acuity and normal color vision.
Apparatus
A Mac Mini equipped with Matlab software and Psychophysics Toolbox extensions (Brainard, 1997) was used to present the stimuli on an Asus VE247 monitor. The participants viewed the monitor from a distance of approximately 50 cm in a dimly lit room. Manual responses were entered using a standard keyboard.
Training Phase
Stimuli
Each trial consisted of a fixation display, a search array, and a feedback display (Figure 1A). The fixation display contained a white fixation cross (.5° × .5° visual angle) presented in the center of the screen against a black background, and the search array consisted of the fixation cross surrounded by six colored circles (each 2.3° × 2.3°) placed at equal intervals on an imaginary circle with a radius of 5°. The target was defined as the red or green circle, exactly one of which was presented on each trial; the color of each non-target circle was drawn from the set {blue, cyan, pink, orange, yellow, white} without replacement. Inside the target circle, a white bar was oriented either vertically or horizontally, and inside each of the non-targets, a white bar was tilted at 45° to the left or to the right (randomly determined for each non-target). The feedback display indicated the amount of monetary reward earned on the current trial, as well as the total accumulated reward.
Figure 1.
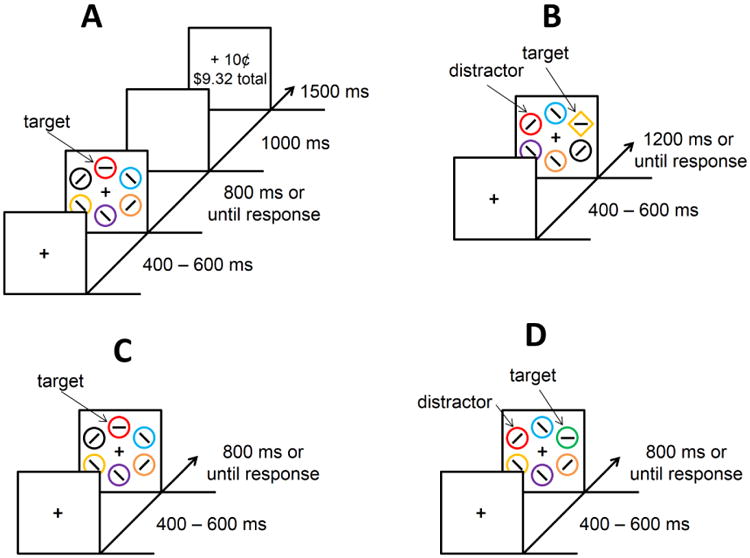
Sequence of events for a trial. (A) Example trial for the training phase of Experiment 1. Participants search for a target that is equally-often red or green, and report the orientation of the bar within the target with a button press. Correct responses are followed by feedback in which a small amount of money is added to a running bank total that participants are paid at the end of the experiment. One color target is more likely to yield a high reward (80% high, 20% low) than the other (20% high, 80% low). (B) Example trial for the test phase of Experiment 1 and 2a. Participants now search for a shape singleton target (diamond among circles or circle among diamonds), and the color of the shapes is irrelevant to the task. No monetary rewards are available. On a subset of trials, one of the non-targets (distractor) is rendered in the color of a former target. (C) Example trial for the training phase of Experiment 2a and 2b. Participants search for a color-defined target, and no monetary rewards are provided. (D) Example trial for the test phase of Experiment 2b. Participants search for a different color-defined target (red if they previously searched for green and vice versa). On a subset of trials, one of the non-targets (distractor) is rendered in the prior target color from training.
Design
One of the two color targets (counterbalanced across participants) was followed by a high reward of 10¢ on 80% of correct trials and a low reward of 2¢ on the remaining 20% (high-reward target); for the other color target, these percentages were reversed (low-reward target). Each color target appeared in each location equally-often, and trials were presented in a random order.
Procedure
The training phase consisted of 240 trials, which were preceded by 50 practice trials. Each trial began with the presentation of the fixation display for a randomly varying interval of 400, 500, or 600 ms. The search array then appeared and remained on screen until a response was made or 800 ms had elapsed, after which the trial timed out. The search array was followed by a blank screen for 1000 ms, the reward feedback display for 1500 ms, and a 1000 ms inter-trial interval (ITI).
Participants made a forced-choice target identification by pressing the “z” and the “m” keys for the vertically- and horizontally-orientated bars within the targets, respectively. Correct responses were followed by monetary reward feedback in which a small amount of money was added to the participant's total earnings. Incorrect responses or responses that were too slow were followed by feedback indicating 0¢ had been earned. If the trial timed out, the computer emitted a 500 ms 1000 Hz tone.
Test Phase
Stimuli
Each trial consisted of a fixation display, a search array, and a feedback display (Figure 1B). The six shapes now consisted of either a diamond among circles or a circle among diamonds, and the target was defined as the unique shape. On a subset of the trials, one of the non-target shapes was rendered in the color of a formerly reward-associated target from the training phase (referred to as the valuable distractor); the target was never red or green. The feedback display only informed participants if their prior response was correct or not.
Design
Target identity, target location, distractor identity, and distractor location were fully crossed and counterbalanced, and trials were presented in a random order. Valuable distractors were presented on 50% of the trials, half of which were high-value distractors and half of which were low-value distractors (high- and low-reward color from the training phase, respectively).
Procedure
Participants were instructed to ignore the color of the shapes and to focus on identifying the unique shape using the same orientation-to-response mapping. The test phase consisted of 240 trials, which were preceded by 20 practice (distractor absent) trials. The search array was followed immediately by non-reward feedback for 1000 ms in the event of an incorrect response (this display was omitted following a correct response) and then by a 500 ms ITI; no monetary rewards were given. Trials timed out after 1200 ms. As in the training phase, if the trial timed out, the computer emitted a 500 ms 1000 Hz tone. Upon completion of the experiment, participants were paid the cumulative reward they had earned in the training phase.
Data analysis
Only correct responses were included in the mean RT for each participant, and RTs exceeding 3 standard deviations of the mean for each condition for each participant were trimmed. The RT trimming procedure resulted in the exclusion of 0.4% of trials.
Results
Training phase
Mean RTs were 568 ms to high-value targets and 564 ms to low-value targets, which did not significantly differ, t(39) = –1.28, p = .207. Mean accuracy was 83.0% to high-value targets and 81.5% to low-value targets, which did not significantly differ, t(39) = 1.39, p = .171. Even when focusing analysis on the second half of trials, no reliable effects of reward were detected in either RT or accuracy (550 ms and 85.1% vs 548 ms and 83.9% for high- and low-value targets, respectively, ts < 0.87, ps > .38).
Test phase
Mean RT for the distractor-absent, low-value, and high-value conditions were 688, 689, and 698 ms, respectively (see Figure 2). An ANOVA revealed a main effect of distractor condition, F(2,78) = 4.48, p = .014, η2p = .103. RTs in the high-value distractor condition were significantly slower than RTs in both the distractor-absent, t(39) = 2.73, p = .009, d = .43, and critically, the low-value distractor conditions, t(39) = 2.30, p = .027, d = .36. Accuracy did not significantly differ by distractor condition (absent: 83.9%, low-value: 83.5%, high-value: 82.9%), F(2,78) = 0.67, p = .517 (see Figure 2).
Figure 2.
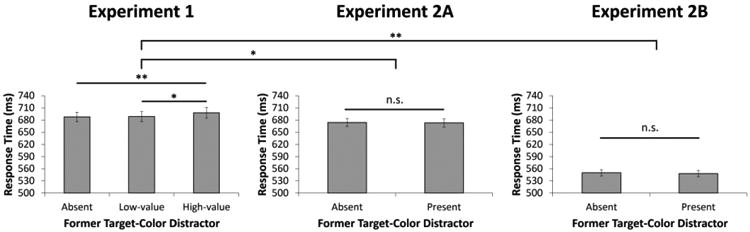
Response time by distractor condition in the test phase of the three experiments. Error bars reflect the standard error of the mean. *p<.05 **p<.01.
Discussion
In contrast to the results of Sha and Jiang (2016), but consistent with a large number of prior reports (e.g., Anderson, in press c, 2016a; Anderson et al., 2011a, 2012a, 2013a, 2013b, 2014b, 2016b; Miranda & Palmer, 2014; Roper et al., 2014), reward did not significantly modulate performance in the training phase. However, and most critically, performance was significantly affected by the distractors in the test phase. Unlike in Sha and Jiang (2016), clear value-dependence was observed in that a significant difference emerged between the high-value and low-value distractor conditions. The results provide direct support for the value-dependence of attentional capture as measured in the value-driven attentional capture paradigm.
Experiment 2a
Another means of establishing value-dependence is to demonstrate significantly weaker capture following training without reward feedback. Experiment 2a examined the role of selection history, divorced from prior reward, in biasing attention. Participants performed a task that was identical to that in Experiment 1, with the exception that no monetary reward feedback was provided (see Figure 1C).
Methods
Participants
Forty new participants were recruited from the Texas A&M University community. All reported normal or corrected-to-normal visual acuity and normal color vision.
Experimental task
The training phase was identical to that of Experiment 1, with the exception that the reward feedback display was removed. Instead, participants were only informed whether their prior response was incorrect or too slow. The test phase was exactly identical to that of Experiment 1.
Data analysis
The analysis parameters were identical to Experiment 1. The 3 SD RT cutoff resulted in the exclusion of 0.5% of trials.
Results
In the test phase, the mean RT was 674 ms in the distractor-absent condition and 673 ms in the distractor-present condition, which did not significantly differ, t(39) = –0.35, p = .731 (Figure 2). Furthermore, the magnitude of attentional capture by the high-value distractor in Experiment 1 was significantly greater than the magnitude of attentional capture by unrewarded former targets in the present experiment, t(78) = 2.29, p = .025, d = .51 (equal variances not assumed). Mean accuracy was 84.9% in the distractor-absent and 84.4% in the distractor-present conditions, which also did not significantly differ, t(39) = 0.75, p = .458.
One possibility is that reliable capture by prior target-color distractors did occur earlier in the test phase but had extinguished by its conclusion, masking a larger and more robust selection history effect. However, even when considering only the first half of trials, there was still no evidence of capture by former target-color distractors (674 vs 676 ms), t(39) = 0.45, p = .656.
Discussion
Unlike Sha and Jiang (2016), we did not find evidence of attentional capture by former target-colored distractors following unrewarded training. Also unlike Sha and Jiang (2016), a significant difference between the magnitude of attentional capture following rewarded compared to unrewarded training was observed. Our findings are further consistent with value-dependence in attentional capture (Anderson et al., 2011b).
Experiment 2b
Experiment 2b aimed to provide an even stronger test of the role of selection history in the guidance of attention, at least to the degree that this influence might reflect a residual consequence of task goals misguiding selection. Following unrewarded visual search for a single target color, participants performed a second version of the same color-search task in which they now searched for a different color (see Figure 1D). Thus, in this version of the test phase, the stimulus displays looked essentially identical to those of the training phase (all colored circles), such that the former target could be easily mistaken for the current target if participants do not efficiently update their goals, providing a robust opportunity for residual goal-directed influences to misguide the participant.
Methods
Participants
Forty new participants were recruited, twenty from the Johns Hopkins University community and twenty from the Texas A&M University community. All reported normal or corrected-to-normal visual acuity and normal color vision.
Experimental task
The training phase was identical to Experiment 2a, except that the target was always the same color (red or green, counterbalanced across participants) and training lasted for 300 trials. The test phase was identical to the training phase, with the exception that the color of the target changed from red to green or vice versa, and one of the non-targets was rendered in the color of the prior target from the training phase on half of the trials (distractor-present trials, see Figure 1D).
Data analysis
The analysis parameters were identical to Experiment 1. The 3 SD RT cutoff resulted in the exclusion of 1.5% of trials.
Results
Mean RT was 550 ms in the distractor-absent condition and 548 ms in the distractor-present condition of the test phase. As in Experiment 2a, this difference was not reliable, t(39) = –1.13, p = .266 (Figure 2), and was significantly smaller than the magnitude of attentional capture evident for high-value distractors in Experiment 1, t(78) = 2.95, p = .005, d = .66 (equal variances not assumed). Mean accuracy was 93% in the distractor-absent and 93.2% in the distractor-present conditions, which also did not significantly differ, t(39) = –0.30, p = .765. There was no evidence of capture by former target-color distractors even in the first half of trials (555 vs 556 ms), t(39) = 0.16, p = .871.
Discussion
Even when the search goals of the training phase and test phase were designed to be maximally confusable, potentially facilitating the residual influence of a top-down control setting (Folk et al., 1992), no evidence for perseverating attentional selection of the former target color was observed. Once again, Experiment 1 was found to have produced significantly greater distraction following training with rewards.
Reanalysis of Anderson et al. (2011b)
Combining across Experiments 1 and 3 of Anderson et al. (2011b), in which a rewarded training phase was used, the difference between the high- and low-value distractors, which was not previously reported, was in fact statistically significant, t(49) = 2.19, p = .034, d = .31. Mean RT for the distractor-absent, low-value, and high-value conditions were 666, 674, and 682 ms, respectively (Figure 3). Furthermore, the magnitude of attentional capture by the high-value distractor was significantly larger than the (non-significant) attentional capture by the former target-colored distractors in Experiment 2 of that study (unrewarded control), t(58) = 2.73, p = .016, d = .89 (equal variance not assumed). Thus, the original data provided by Anderson et al. (2011b) also meet the criteria for value-dependent attentional capture as outlined by Sha and Jiang (2016).
Figure 3.

Response time by distractor condition in the original data from Anderson et al. (2011b), combining across Experiments 1 and 3. Error bars reflect the standard error of the mean. *p<.05 **p<.01.
General Discussion
Across three experiments, we find clear statistical evidence for value-dependence using each of the two criteria advocated by Sha and Jiang (2016). This was further confirmed by a reanalysis of the original Anderson et al. (2011b) data. We therefore conclude that the traditional implementation of the value-driven attentional capture paradigm is indeed an appropriate means of assessing value-driven attentional processes, and that the reward manipulation in this paradigm plays an important role in determining subsequent behavioral performance. In the remainder of the General Discussion, we will explore considerations arising from the findings of Sha and Jiang (2016) that the present study speak to, along with broader considerations concerning the use of the value-driven attentional capture paradigm.
Lessons from Sha and Jiang (2016)
Although the evidence for value-dependence is now substantial, as described in the Introduction and further supported in the context of the original value-driven attentional capture paradigm in the present study, the negative findings of Sha and Jiang (2016) highlight a broader issue that demands consideration in the value-driven attention literature. Namely, purely value-dependent effects on attention are often subtle, at least under circumstances in which physically non-salient and completely task-irrelevant distractors are used (as is the case in the most popular implementation of the paradigm). While it is possible that the null findings of Sha and Jiang (2016) reflect Type II error, it would be disadvantageous not to examine differences between experiments that might have contributed to reduced sensitivity to value-dependent effects. We explore some of these possibilities here.
Reward manipulation
The overall amount of reward offered in the experiments of Sha and Jiang (2016) was noticeably reduced compared to typical methods employed in the value-driven attention literature. The magnitude of cumulative reward in their study amounted to a 2-4 USD bonus that was spread out over a greater number of trials than the approximately 13 USD earned by participants in the present study. Participants in Sha and Jiang (2016) also included those recruited for experiment credit compensation, meaning that some of these participants may have been less concerned about the magnitude of their earnings compared to individuals for whom monetary compensation was the only incentive, as in the present study. Although it is clear that the magnitude of value-driven attentional capture does not scale with the raw magnitude of rewards and instead appears to be more sensitive to relative value (i.e., high vs low; see Anderson, 2016b), it may be the case that rewards need to reach a certain minimal threshold before reliable consequences on the development of attentional bias can be measured. This may be especially the case when converting points to money, as was done in Sha and Jiang (2016), which adds a layer of abstraction.
Unrewarded control condition
Attentional capture by previously unrewarded target features was substantially larger in Sha and Jiang (2016) than in the present study and in several other studies using a similar paradigm (Anderson, in press a; Anderson et al., 2011a, 2011b, 2014a; Qi et al., 2013; Roper & Vecera, 2016; Wang et al., 2013 see also Anderson, 2015b; Sali et al., 2014). There are a few differences in the experimental protocol that might explain the unusually high sensitivity to attentional capture based entirely on selection history in Sha and Jiang (2016) that are worth noting. First, training lasted 768 trials in the unrewarded version of their training, more than three times greater than the typical implementation of the value-driven attentional capture paradigm (240 trials; see Sali et al., 2014 for even fewer). Such an increase in the length of training may have strengthened reward-independent habit learning to levels not typically seen in the value-driven attention literature (although see Experiment 2 of Anderson et al., 2011b). To maximize the robustness of value-dependent effects across rewarded and unrewarded training, it might be advisable to limit unrewarded training to levels sufficient to produce significant attentional capture by high-value distractors, which is no more than 240 trials (the number used in the most common implementation of the paradigm). Additionally, in considering a comparison between rewarded and unrewarded attentional capture, it is certainly advisable not to use longer training for the unrewarded compared to the rewarded version of the task, as was the case in one pair of experiments that were compared in Sha and Jiang (2016).
Another potential factor contributing to enhanced attentional capture following unrewarded training in Sha and Jiang (2016) was the nature of the performance feedback. In typical implementations of the paradigm, participants are simply informed via text feedback if their response was incorrect. In Sha and Jiang (2016), a voice recording additionally told participants their response was wrong and that they should try to be accurate. The increased salience of this feedback may have accentuated the association of target color with internal reward (negative reinforcement) and/or punishment signals evoked in response to the feedback, producing capture that was not a pure reflection of selection history per se.
Finally, in the unrewarded experiment of Sha and Jiang (2016), the test phase was performed the day following training. This was not the case in prior unrewarded control experiments performed in the value-driven attention literature. The consequences of this spacing are not known, but it could facilitate memory for former targets via consolidation with sleep.
Time pressure
The present study utilized a stringent time-out criterion (1200 ms in the test phase) that encouraged fast responses. The reduced overall accuracy and faster RTs in the present study compared to Sha and Jiang (2016) attests to the added difficulty associated with this design feature, which was employed in the original demonstration of value-driven attentional capture (Anderson et al., 2011b) and has been subsequently adopted in many other implementations of the paradigm. In the oculomotor capture literature, attentional capture is most prominent on fast response trials (e.g., van Zoest, Donk, & Theeuwes, 2004), including in the case of value-driven attentional capture (Pearson et al., 2016). For studies looking to measure value-dependence, implementing this design feature may be advantageous.
Other Design Considerations
Since the study was originally reported, many variations on the value-driven attentional capture paradigm have been explored. Several of these may be useful in improving sensitivity to value-dependent effects on attention. Here, we briefly draw reference to a few of these variations.
Low-value or unrewarded targets
Robust value-dependent effects have been observed when a high-reward target is paired with a target that never yields reward during the same training phase (e.g., Failing & Theeuwes, 2014; Pool et al., 2014). This previously unrewarded target is still experienced in the context of visual search in which rewards are available, equating broad contextual effects of reward-related motivation. Swapping an unrewarded target for the low-value target in the design employed by the present study might produce more robust value-dependence (i.e., comparison of high-value vs previously unrewarded former target color in the same experiment).
Eye movements as a dependent measure
Although most studies of value-driven attention have employed performance-related measures of attentional capture as in the present study and Sha and Jiang (2016), several have included eye tracking measures as well (e.g., Anderson & Yantis, 2012; Failing et al., 2015; Le Pelley et al., 2015; Theeuwes & Belopolsky, 2012). Reflecting ballistic responses that provide a direct window into spatial selection, the probability of a saccade landing on or near a distractor has proven a highly reliable measure of value dependence that may have advantages over performance measures such as response time and accuracy. A similar argument regarding sensitivity to spatial selection can be made concerning studies that adopt a spatial cuing approach in which the cues can be rendered in a previously reward-associated feature (e.g., Failing & Theeuwes, 2014; Pool et al., 2014); however, this approach has a disadvantage in that the previously reward-associated stimulus sometimes predicts the target location, reducing the strength of claims that can be made concerning the automaticity of selection.
Study sample considerations
Value-driven attentional capture has been shown to be more robust in individuals who are more impulsive (Anderson et al., 2011b, 2016b; see also Anderson et al., 2013a; Qi et al., 2013), including individuals with substance abuse issues (see Anderson, 2016d, for a review), and much less robust in individuals who are depressed (Anderson et al., 2014b). It might be useful for studies of value-driven attention to measure and account for such variability, potentially as a covariate.
Considerations regarding the use of a separate training and test phase
Although the results of the present study support the validity of the traditional value-driven attentional capture paradigm, it is not the only paradigm available for studying value-dependent attention. Another paradigm has recently been developed that measures value-dependent effects on attention while circumventing selection history effects altogether (Le Pelley et al., 2015). In this paradigm, task-irrelevant distractors predict the reward outcome for correctly identifying the target. These distractors similarly come to capture attention, even though participants have never been explicitly rewarded for selecting them. If attentional capture in the value-driven attentional capture paradigm reflects some combination of value-dependent effects and selection history effects, and is perhaps particular to their interaction, why not just avoid the complexity entirely in favor of a purer measure of value-dependence?
There are at least three salient reasons why the training phase-test phase design should remain a powerful tool in the study of value-driven attention. The first involves its translational appeal. In everyday life, reward and goals are intricately linked: we pursue that which we find rewarding. Most reward learning happens in the context of goal-directed behavior. Value-driven attention, as measured using the training phase-test phase model, speaks to such broadly applicable learning processes. This can be prominently seen in the case of drug addiction, in which drug use is initially a voluntary and goal-directed behavioral process. Attentional biases for drug cues mirror value-driven attentional biases following non-drug reward learning very closely (Anderson, 2016d).
The second reason involves the pure and compelling test of automaticity provided by the test phase. The previously reward-associated distractor is in every way task-irrelevant and decoupled from current reward considerations, and can also be made to be otherwise intrinsically non-salient (i.e., physically inconspicuous) aside from its training history (Anderson et al., 2011b). This contrasts with a single-phase approach involving task-irrelevant but reward-predictive distractors (Le Pelley et al., 2015), which by their predictive nature possess some degree of relevance, pertinence, or informational value. In the typical implementation of the single-phase paradigm, the distractors are also physically salient, pairing reward with a corresponding automatic orienting response and confounding salience-dependent effects with value-dependent effects (e.g., Bucker, Belopolsky, & Theeuwes, 2015; Le Pelley et al., 2015; Pearson et al., 2015, 2016); when the distractors are non-salient, it appears that participants need to be explicitly informed of the relationship between reward and color, further suggesting that actively monitoring for reward-predictive information may play a role (Failing, Nissens, Pearson, Le Pelley, & Theeuwes, 2015; see also Munneke, Belopolsky, & Theeuwes, 2016).
The third reason why the training phase-test phase model provides a powerful tool in the study of value-driven attention concerns its flexibility in measuring a range of automatic biases. Because the distractors are entirely task-irrelevant, they can be implemented in basically any task, including tasks that examine response biases (Anderson et al., 2012, 2016a; see also Krebs, Boehler, Egner, & Woldorff, 2011; Krebs, Boehler, & Woldorff, 2010; Anderson, in press b, for a review). This allows for a broader assessment of the impact of value-driven attention on information processing, and also allows for assessment of generalizability across contexts and situations (Anderson et al., 2012; Anderson, 2015a, 2015b) as well as the enduring nature of the learning (which is only possible under conditions of extinction; Anderson & Yantis, 2013).
We would conclude that each of these two paradigms provides a unique and valuable window into value-dependent attention, and that the choice of which paradigm to use should depend on the specific hypothesis under investigation. If the hypothesis is specifically concerned with separating value-dependent influences from broader consequences of selection history, or examining the consequences of reward learning on attention as the learning process unfolds, then the single-phase model introduced by Le Pelley and colleagues (2015) is the best choice. If the hypothesis involves making strong claims about automaticity, about purely history-related priority (independent of physical salience), or involves questions concerning broader consequences of learning (e.g., robustness to extinction, generalizability, extension to biases in other information processing domains), the training phase-test phase model offers distinct advantages. The training phase-test phase model may also have broader translational potential, for example, to our understanding of addiction-related processes (Anderson, 2016d), although the translational utility of the single-phase model has not yet been thoroughly examined as the paradigm is newer. To the degree that performance in these two paradigms offers similar insights into psychopathology and other real-world behaviors, this would further argue that they are predominantly measuring the same (value-dependent) attentional process. A hybrid approach, involving training as in the single-phase model and a test phase as in the present study, combines certain strengths of each of these paradigms (see Mine & Saiki, 2015).
Power Considerations
Using the effect size measures from the present study (pooling across Experiment 1 and the reanalysis of Anderson et al., 2011), a sample size of forty yields power of β = .55 to detect a difference between the high- and low-value distractor conditions using a two-tailed test at α = .05, and β = .85 to detect a difference in the magnitude of capture following rewarded and otherwise equivalent unrewarded training as in Experiment 2A. The effect size for the at times elusive high- vs low-value distractor comparison is in the medium-to-small range, which contrasts with the highly robust measures of contingent attentional capture (Folk et al., 1992) and stimulus-driven attentional capture (Theeuwes, 1992, 2010) that attention researchers may be more familiar with, and as a result many value-driven attention studies have been underpowered to detect this measure of value-dependence. The more ambiguous but more robust comparison between the high-value distractor present and distractor absent conditions yields substantially greater power, β = .98; the power difference between the high-value vs absent and high- vs low-value distractor conditions might contribute to several of the ambiguities in the literature raised by Sha and Jiang (2016). Power to detect uniquely value-dependent effects might be enhanced by implementing some of the design features described in the Other Design Considerations section above.
Conclusions
In conclusion, the value-driven attentional capture paradigm provides a useful tool for measuring the effects of reward learning on involuntary attentional capture. Attentional capture, as measured in this paradigm, is not reducible to target history effects divorced from reward feedback and related learning. The training phase-test phase model used by this paradigm provides a unique window into value-based attention that should continue to be leveraged to further our understanding of reward-related attentional processes. Experimental design and statistical power considerations should be taken into account in order to maximize the ability to detect unequivocally value-dependent effects.
Contributor Information
Brian A. Anderson, Texas A&M University
Madeline Halpern, Johns Hopkins University.
References
- Anderson BA. A value-driven mechanism of attentional selection. Journal of Vision. 2013;13(3:7):1–16. doi: 10.1167/13.3.7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Anderson BA. Value-driven attentional capture is modulated by spatial context. Visual Cognition. 2015a;23:67–81. doi: 10.1080/13506285.2014.956851. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Anderson BA. Value-driven attentional priority is context specific. Psychonomic Bulletin and Review. 2015b;22:750–756. doi: 10.3758/s13423-014-0724-0. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Anderson BA. Social reward shapes attentional biases. Cognitive Neuroscience. 2016a;7:30–36. doi: 10.1080/17588928.2015.1047823. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Anderson BA. The attention habit: How reward learning shapes attentional selection. Annals of the New York Academy of Sciences. 2016b;1369:24–39. doi: 10.1111/nyas.12957. [DOI] [PubMed] [Google Scholar]
- Anderson BA. Value-driven attentional capture in the auditory domain. Attention, Perception, and Psychophysics. 2016c;78:242–250. doi: 10.3758/s13414-015-1001-7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Anderson BA. What is abnormal about addiction-related attentional biases? Drug and Alcohol Dependence. 2016d;167:8–14. doi: 10.1016/j.drugalcdep.2016.08.002. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Anderson BA. Counterintuitive effects of negative social feedback on attention. Cognition and Emotion. doi: 10.1080/02699931.2015.1122576. in press a. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Anderson BA. Going for it: the economics of automaticity in perception and action. Current Directions in Psychological Science in press b. [Google Scholar]
- Anderson BA. Reward processing in the value-driven attention network: Reward signals tracking cue identity and location. Social, Cognitive, and Affective Neuroscience. doi: 10.1093/scan/nsw141. in press c. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Anderson BA, Faulkner ML, Rilee JJ, Yantis S, Marvel CL. Attentional bias for non-drug reward is magnified in addiction. Experimental and Clinical Psychopharmacology. 2013a;21:499–506. doi: 10.1037/a0034575. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Anderson BA, Folk CL, Garrison R, Rogers L. Mechanisms of habitual approach: Failure to suppress irrelevant responses evoked by previously reward-associated stimuli. Journal of Experimental Psychology: General. 2016a;145:796–805. doi: 10.1037/xge0000169. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Anderson BA, Kronemer SI, Rilee JJ, Sacktor N, Marvel CL. Reward, attention, and HIV-related risk in HIV+ individuals. Neurobiology of Disease. 2016b;92:157–165. doi: 10.1016/j.nbd.2015.10.018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Anderson BA, Kuwabara H, Wong DF, Gean EG, Rahmim A, Brasic JR, George N, Frolov B, Courtney SM, Yantis S. The role of dopamine in value-based attentional orienting. Current Biology. 2016c;26:550–555. doi: 10.1016/j.cub.2015.12.062. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Anderson BA, Laurent PA, Yantis S. Learned value magnifies salience-based attentional capture. PLoS ONE. 2011a;6:e27926. doi: 10.1371/journal.pone.0027926. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Anderson BA, Laurent PA, Yantis S. Value-driven attentional capture. Proceedings of the National Academy of Sciences, USA. 2011b;108:10367–10371. doi: 10.1073/pnas.1104047108. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Anderson BA, Laurent PA, Yantis S. Generalization of value-based attentional priority. Visual Cognition. 2012;20:647–658. doi: 10.1080/13506285.2012.679711. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Anderson BA, Laurent PA, Yantis S. Reward predictions bias attentional selection. Frontiers in Human Neuroscience. 2013b;7(262):1–6. doi: 10.3389/fnhum.2013.00262. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Anderson BA, Laurent PA, Yantis S. Value-driven attentional priority signals in human basal ganglia and visual cortex. Brain Research. 2014a;1587:88–96. doi: 10.1016/j.brainres.2014.08.062. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Anderson BA, Leal SL, Hall MG, Yassa MA, Yantis S. The attribution of value-based attentional priority in individuals with depressive symptoms. Cognitive, Affective, and Behavioral Neuroscience. 2014b;14:1221–1227. doi: 10.3758/s13415-014-0301-z. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Anderson BA, Yantis S. Value-driven attentional and oculomotor capture during goal-directed, unconstrained viewing. Attention, Perception, and Psychophysics. 2012;74:1644–1653. doi: 10.3758/s13414-012-0348-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Anderson BA, Yantis S. Persistence of value-driven attentional capture. Journal of Experimental Psychology: Human Perception and Performance. 2013;39:6–9. doi: 10.1037/a0030860. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Brainard DH. The psychophysics toolbox. Spatial Vision. 1997;10:433–436. [PubMed] [Google Scholar]
- Bucker B, Belopolsky AV, Theeuwes J. Distractors that signal reward attract the eyes. Visual Cognition. 2015;23:1–24. [Google Scholar]
- Failing M, Nissens T, Pearson D, Le Pelley M, Theeuwes J. Oculomotor capture by stimuli that signal the availability of reward. Journal of Neurophysiology. 2015;114:2316–2327. doi: 10.1152/jn.00441.2015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Failing MF, Theeuwes J. Exogenous visual orienting by reward. Journal of Vision. 2014;14(5:6):1–9. doi: 10.1167/14.5.6. [DOI] [PubMed] [Google Scholar]
- Folk CL, Remington RW, Johnston JC. Involuntary covert orienting is contingent on attentional control settings. Journal of Experimental Psychology: Human Perception and Performance. 1992;18:1030–1044. [PubMed] [Google Scholar]
- Hickey C, Peelen MV. Neural mechanisms of incentive salience in naturalistic human vision. Neuron. 2015;85:512–518. doi: 10.1016/j.neuron.2014.12.049. [DOI] [PubMed] [Google Scholar]
- Jiao J, Du F, He X, Zhang K. Social comparison modulates reward-driven attentional capture. Psychonomic Bulletin and Review. 2015;22:1278–1284. doi: 10.3758/s13423-015-0812-9. [DOI] [PubMed] [Google Scholar]
- Krebs RM, Boehler CN, Egner T, Woldorff MG. The neural underpinnings of how reward associations can both guide and misguide attention. Journal of Neuroscience. 2011;31:9752–9759. doi: 10.1523/JNEUROSCI.0732-11.2011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Krebs RM, Boehler CN, Woldorff MG. The influence of reward associations on conflict processing in the Stroop task. Cognition. 2010;117:341–347. doi: 10.1016/j.cognition.2010.08.018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kyllingsbaek S, Schneider WX, Bundesen C. Automatic attraction of attention to former targets in visual displays of letters. Perception and Psychophysics. 2001;63:85–98. doi: 10.3758/bf03200505. [DOI] [PubMed] [Google Scholar]
- Kyllingsbaek S, Van Lommel S, Sorensen TA, Bundesen C. Automatic attraction of visual attention by supraletter features of former target strings. Frontiers in Psychology. 2014;5:1383:1–7. doi: 10.3389/fpsyg.2014.01383. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Laurent PA, Hall MG, Anderson BA, Yantis S. Valuable orientations capture attention. Visual Cognition. 2015;23:133–146. doi: 10.1080/13506285.2014.965242. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Le Pelley ME, Pearson D, Griffiths O, Beesley T. When goals conflict with values: Counterproductive attentional and oculomotor capture by reward-related stimuli. Journal of Experimental Psychology: General. 2015;144:158–171. doi: 10.1037/xge0000037. [DOI] [PubMed] [Google Scholar]
- Pearson D, Donkin C, Tran SC, Most SB, Le Pelley ME. Cognitive control and counterproductive oculomotor capture by reward-related stimuli. Visual Cognition. 2015;23:41–66. [Google Scholar]
- Pearson D, Osborn R, Whitford TJ, Failing M, Theeuwes J, Le Pelley ME. Value-modulated oculomotor capture by task-irrelevant stimuli is a consequence of early competition on the saccade map. Attention, Perception, and Psychophysics. 2016;78:2226–2240. doi: 10.3758/s13414-016-1135-2. [DOI] [PubMed] [Google Scholar]
- Lin Z, Lu ZH, He S. Decomposing experience-driven attention: opposite attentional effects of previously predictive cues. Attention, Perception, and Psychophysics. 2016;78:2185–2198. doi: 10.3758/s13414-016-1101-z. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mine C, Saiki J. Task-irrelevant stimulus-reward association induces value-driven attentional capture. Attention, Perception, and Psychophysics. 2015;77:1896–1907. doi: 10.3758/s13414-015-0894-5. [DOI] [PubMed] [Google Scholar]
- Miranda AT, Palmer EM. Intrinsic motivation and attentional capture from gamelike features in a visual search task. Behavioral Research Methods. 2014;46:159–172. doi: 10.3758/s13428-013-0357-7. [DOI] [PubMed] [Google Scholar]
- Moher J, Anderson BA, Song JH. Dissociable effects of salience on attention and goal-directed action. Current Biology. 2015;25:2040–2046. doi: 10.1016/j.cub.2015.06.029. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Munneke J, Belopolsky AV, Theeuwes J. Distractors associate with reward break through the focus of attention. Attention, Perception, and Psychophysics. 2016;78:2213–2225. doi: 10.3758/s13414-016-1075-x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pool E, Brosch T, Delplanque S, Sander D. Where is the chocolate? Rapid spatial orienting toward stimuli associated with primary reward. Cognition. 2014;130:348–359. doi: 10.1016/j.cognition.2013.12.002. [DOI] [PubMed] [Google Scholar]
- Qi S, Zeng Q, Ding C, Li H. Neural correlates of reward-driven attentional capture in visual search. Brain Research. 2013;1532:32–43. doi: 10.1016/j.brainres.2013.07.044. [DOI] [PubMed] [Google Scholar]
- Qu Z, Hillyard SA, Ding Y. Perceptual learning induces persistent attentional capture by nonsalient shapes. Cerebral Cortex. doi: 10.1093/cercor/bhv342. in press. [DOI] [PubMed] [Google Scholar]
- Roper ZJJ, Vecera SP. Funny money: The attentional role of monetary feedback detached from expected value. Attention, Perception, and Psychophysics. 2016;78:2199–2212. doi: 10.3758/s13414-016-1147-y. [DOI] [PubMed] [Google Scholar]
- Roper ZJJ, Vecera SP, Vaidya JG. Value-driven attentional capture in adolescents. Psychological Science. 2014;25:1987–1993. doi: 10.1177/0956797614545654. [DOI] [PubMed] [Google Scholar]
- Sali AW, Anderson BA, Yantis S. The role of reward prediction in the control of attention. Journal of Experimental Psychology: Human Perception and Performance. 2014;40:1654–1664. doi: 10.1037/a0037267. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Serences JT, Shomstein S, Leber AB, Golay X, Egeth HE, Yantis S. Coordination of voluntary and stimulus-driven attentional control in human cortex. Psychological Science. 2005;16:114–122. doi: 10.1111/j.0956-7976.2005.00791.x. [DOI] [PubMed] [Google Scholar]
- Sha LZ, Jiang YV. Components of reward-driven attentional capture. Attention, Perception, and Psychophysics. 2016;78:403–414. doi: 10.3758/s13414-015-1038-7. [DOI] [PubMed] [Google Scholar]
- Shiffrin RM, Schneider W. Controlled and automatic human information processing II: Perceptual learning, automatic attending, and general theory. Psychological Review. 1977;84:127–190. [Google Scholar]
- Theeuwes J. Perceptual selectivity for color and form. Perception and Psychophysics. 1992;51:599–606. doi: 10.3758/bf03211656. [DOI] [PubMed] [Google Scholar]
- Theeuwes J. Top-down and bottom-up control of visual selection. Acta Psychologica. 2010;135:77–99. doi: 10.1016/j.actpsy.2010.02.006. [DOI] [PubMed] [Google Scholar]
- Theeuwes J, Belopolsky AV. Reward grabs the eye: oculomotor capture by rewarding stimuli. Vision Research. 2012;74:80–85. doi: 10.1016/j.visres.2012.07.024. [DOI] [PubMed] [Google Scholar]
- van Zoest W, Donk M, Theeuwes J. The role of stimulus-driven and goal-driven control in saccadic visual selection. Journal of Experimental Psychology: Human Perception and Performance. 2004;30:746–759. doi: 10.1037/0096-1523.30.4.749. [DOI] [PubMed] [Google Scholar]
- Wang L, Yu H, Zhou X. Interaction between value and perceptual salience in value-driven attentional capture. Journal of Vision. 2013;13(3:5):1–13. doi: 10.1167/13.3.5. [DOI] [PubMed] [Google Scholar]