
Figure 4.
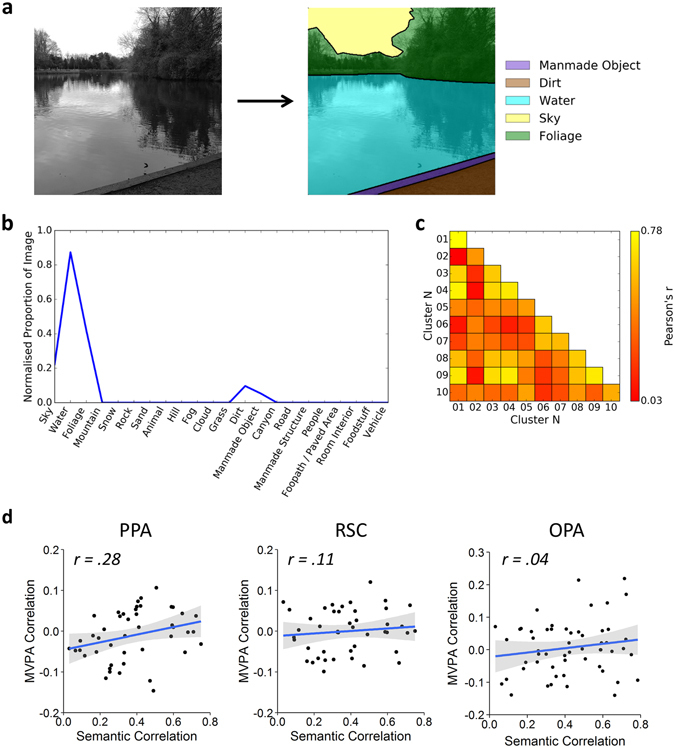
Local semantic concept model23. (a) Objects within each of the images in the stimulus set were segmented and labelled using the LabelMe toolbox53. Object labels were then reduced to a core set of 22 labels sufficient to describe the stimulus set. For copyright reasons, the scene image included here is an example only and is not part of the stimulus set. (b) For each image, a vector was constructed representing the proportion of pixels in the image occupied by each of the object labels. Vectors were normalised to have an overall magnitude of 1. (c) Group average similarity matrix calculated by correlating the vectors within and between clusters using a leave-one-image-out cross-validation scheme. (d) Results of representational similarity analyses between the off-diagonal elements of the MVPA and local semantic concept model similarity matrices; shaded regions represent 95% confidence intervals. (***p < 0.001, **p < 0.01, *p < 0.05).