
Figure 2.
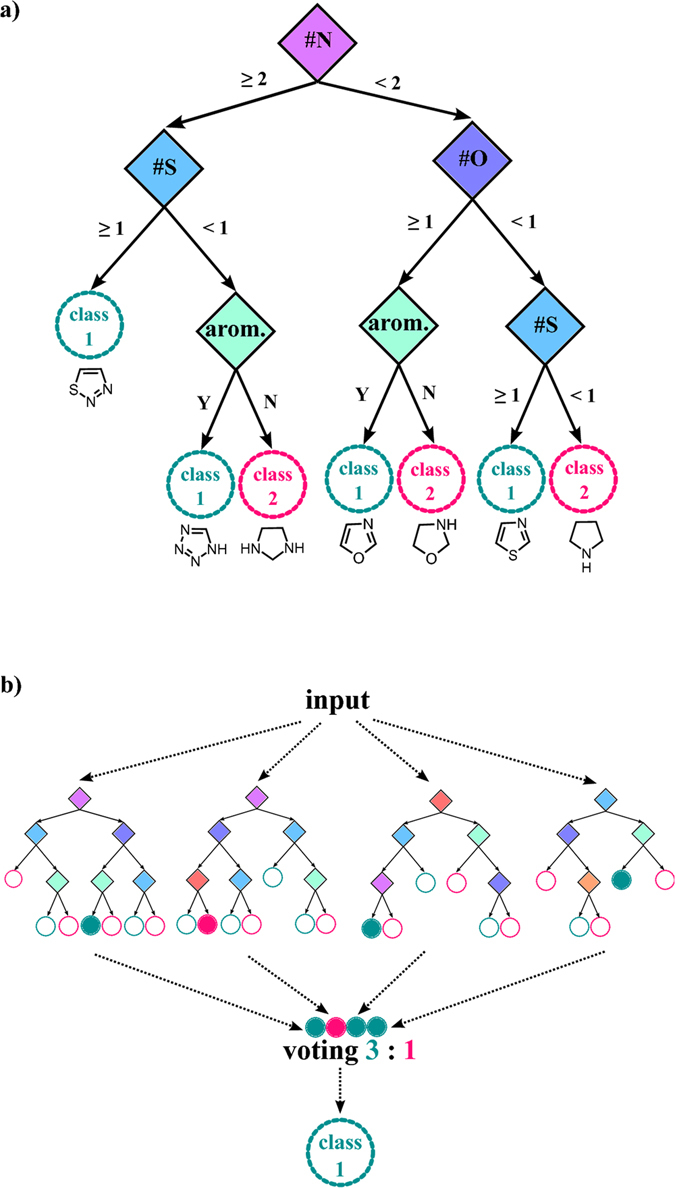
Decision trees and random-forest classifiers. (a) An example of a decision tree with simple chemical features classifying input molecules. Traversing the tree top-down, each diamond-shaped node assigns a molecule to a branch depending on its particular chemical feature of interest. For example, oxazole molecule is first classified as having less than two nitrogen atoms (criterion at the purple decision node), then as having at least one oxygen atom (criterion at the dark-blue node), and then as having an aromatic ring (criterion at the light-green node). When sets of molecules are analyzed by such a tree, they are ultimately categorized into two classes – ‘class 1’ corresponding to azoles, and ‘class 2’ corresponding to azolidines. (b) Since the trees are relatively small (i.e., have only few decision nodes/layers) classification accuracy for each individual tree can be poor. However, when large numbers of small trees with different features (the so-called Random Forest) are constructed, and each provides its own classification/“vote,” majority vote across all trees enhances classification accuracy. For details of this algorithm please see ref. 18.