
Figure 7.
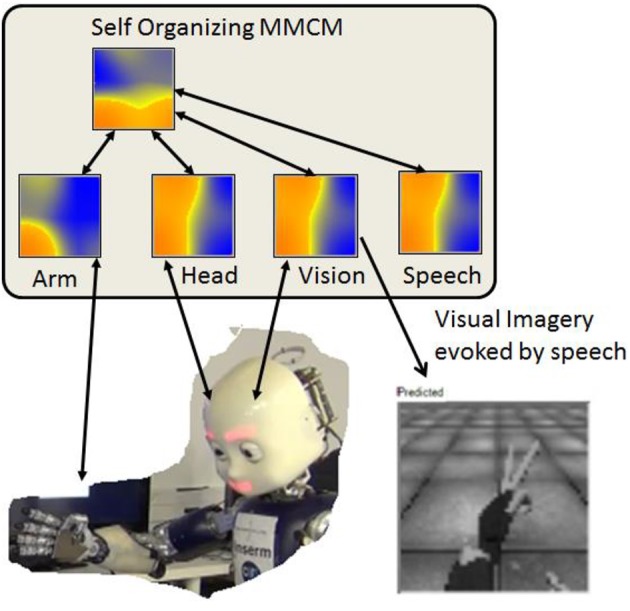
Body schema. Multi-modal convergence map model merging proprioception, vision, and language. Arm and Head are 50 × 50 maps taking as input the robot encoders (left\_arm = 16 degrees of freedom and head = 6); the speech is a 50 × 50 map fed by a string (converted to a vector of double). The vision is from the iCub left eye camera, gray scaled and cropped to a fovea area and rescaled to an experiment dependent resolution (from 15 × 15 to 320 × 240). These low level maps converge to the multi-modal convergence map. Then, activation of a single input map activates the MMCM which by divergence activates the other input maps. The image of the hand is actually reconstructed from input to the vision map from the stimulated MMCM. From Lallee and Dominey (2013).