
Figure 1.
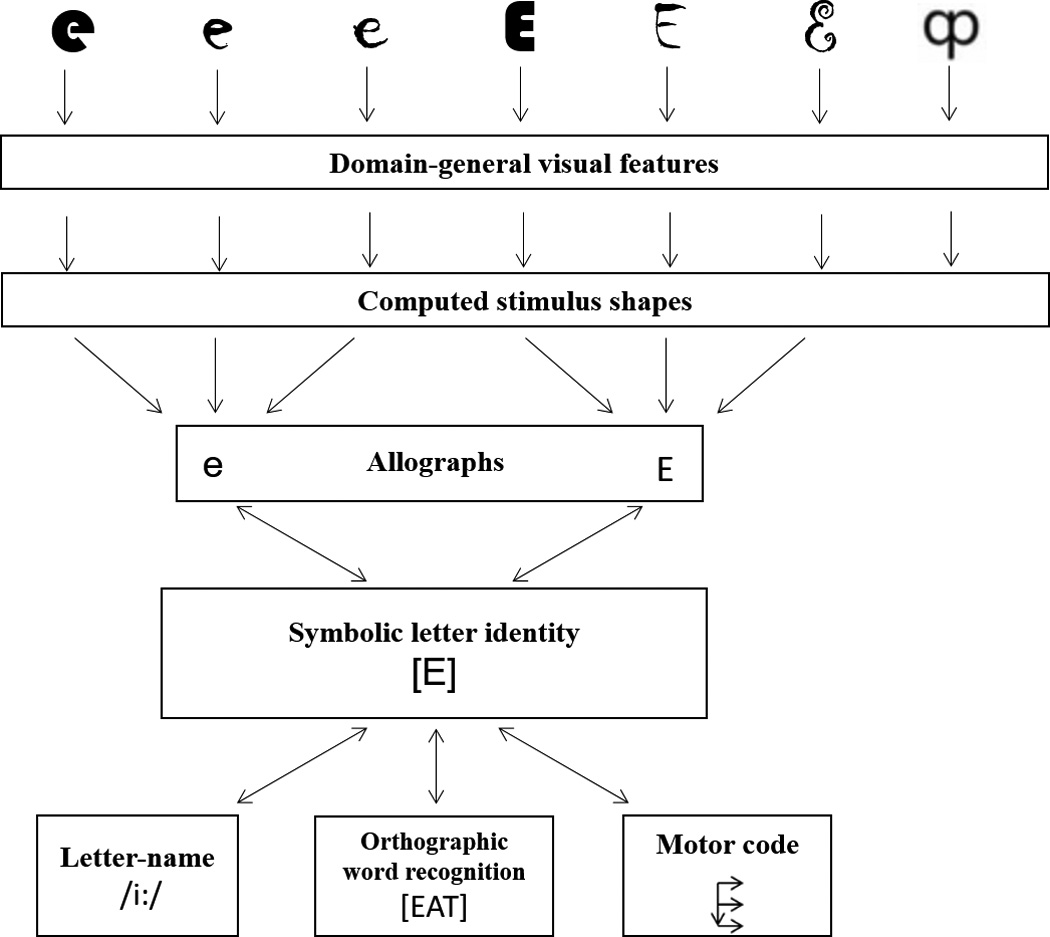
Proposed representational levels in the processing of different fonts of upper and lower-case E and one pseudoletter. In the initial processing stages, stimuli are represented in terms of domain-general visual features (e.g. simple and complex cells representing oriented bars). Many models also posit a font-specific computed stimulus shape representations of the shape of the stimulus independent of its identity. This level of representation would allow us to describe the shape of the letter E as well as the shape of any given pseudoletter. Computed stimulus shape representations do not encode letter identity information or even whether the shape is a letter or not. These computed stimulus shape representations go on to access stored font-invariant allograph representations that presumably encode letter shapes in a manner that abstracts away from certain differences in stimulus font. The allographs in turn activate abstract or symbolic letter identity (SLI) representations that are both font and case independent—abstracting away from visual information altogether. SLI representations serve as input to the lexical and sublexical reading processes that mediate orthographic word recognition. They also serve as a conduit to cross-modal letter representations like phonological letter names and motoric production codes for written letter production.