
Fig. 3.
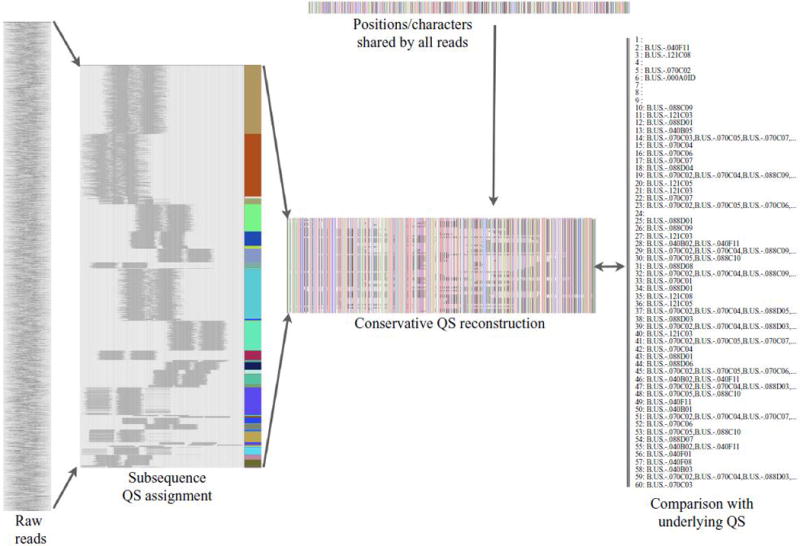
The QS reconstruction pipeline can be seen as a data reduction which aims to limit false explanatory sequences. The process starts with raw reads (left). These are aggregated into tractable quasispecies subsequences supported by read conflicts and overlap, as discussed in the methods. Using the mapped reads, sequence positions which are perfectly conserved across reads (top) are also incorporated to construct an explanatory set of quasispecies subsequences (center, labeled “conservative quasispecies reconstruction”, each row corresponds to the sequence obtained from a set of non-conflicting reads, columns correspond to sequence positions, and colors correspond to sequence characters – A = red, C = green, G = blue, T = white, undetermined = gray). Reconstruction is conservative in that the majority of these subsequences match at least one true underlying sequence (54/60 for P00005, shown in this figure). 36 of these quasispecies sequences contain sufficient information to map uniquely to an underlying quasispecies sequence.