

Abstract
Wireless sensor networks are required in smart applications to provide accurate control, where the high density of sensors brings in a large quantity of redundant data. In order to reduce the waste of limited network resources, data aggregation is utilized to avoid redundancy forwarding. However, most of aggregation schemes reduce information accuracy and prolong end-to-end delay when eliminating transmission overhead. In this paper, we propose a data aggregation scheme based on overlapping rate of sensing area, namely AggOR, aiming for energy-efficient data collection in wireless sensor networks with high information accuracy. According to aggregation rules, gathering nodes are selected from candidate parent nodes and appropriate neighbor nodes considering a preset threshold of overlapping rate of sensing area. Therefore, the collected data in a gathering area are highly correlated, and a large amount of redundant data could be cleaned. Meanwhile, AggOR keeps the original entropy by only deleting the duplicated data. Experiment results show that compared with others, AggOR has a high data accuracy and a short end-to-end delay with a similar network lifetime.
Keywords: wireless sensor networks, data aggregation, overlapping rate of sensing area, data accuracy
1. Introduction
Wireless sensor networks (WSNs) consist of a large quantity of sensor nodes to offer a variety of services, such as environmental monitoring and security surveillance [1,2]. Nowadays, WSNs are considered as one of the most promising technologies for cyber manufacturing systems in Industrial Internet of Things (IIoT) [3]. In smart factories, WSNs serve for intelligent industrial control applications in harsh environments [4,5]. In order to provide highly reliable and realtime transmission, sensor nodes are often densely distributed in monitoring areas. However, the high density of node deployment causes lots of redundant data, and hence their forwarding brings in a large waste of the limited power and bandwidth, resulting in low energy efficiency and short network lifetime.
In order to avoid the transmissions of redundant information, data aggregation is required in WSNs. In most of aggregation schemes, the whole network is separated into several areas like grids according to the geographical coordinates, and then the data collected by sensors in each area are aggregated by a particular node [6]. Because of the possible random distribution of nodes as well as the fixed size and shape of the aggregation area, the similarity of data collected by different sensors in one area is not close, which affects the performance of aggregation. Additionally, since there may be multiple hops from an ordinary node to an aggregation node, the redundant data might be forwarded for several hops and hence lead to a high energy cost. Besides, an aggregation node has to wait for collecting all sensor data in its area before aggregation, which results in a long end-to-end delay [7,8].
In this paper, we propose a novel data aggregation scheme based on overlapping rate of sensing area in WSNs, named AggOR, to achieve energy-efficient data collection and keep high data accuracy. With respect to the sensing ranges, several nodes construct a gathering area if their overlapping rates of sensing area are no less than a preset threshold. In this way, the data in a gathering area have relatively high correlation and hence would be aggregated efficiently to eliminate redundancy. Moreover, there are only one or two levels of nodes in a gathering area. Usually a lower-level node transfers its sensing data to an upper-level node which aggregates and then delivers data to the sink. Therefore, redundant data are removed immediately after one-hop forwarding, which prohibits more energy consumption of redundancy relay. For further energy saving, an appropriate neighbor node at the same level could also be selected as the aggregation node if subject to particular conditions in the aggregation rules.
The main advantages of our scheme are listed below. (1) Construct gathering areas according to the overlapping rate of sensing area. It helps to remove a large quantity of duplicated data and keep almost all entropy of the original information; (2) Three aggregation rules take full advantage of data aggregation by selecting aggregating nodes from candidate parent nodes or appropriate neighbor nodes. They limit the hops of redundancy forwarding and decrease the transmission overhead as much as possible; (3) A large quantity of experiments show that AggOR scheme keeps a high accuracy of data, improves energy efficiency and achieves a quick data collection.
The rest of this paper is organized as follows. In Section 2, some related work on data aggregation in WSNs is discussed. Definitions and aggregation rules used in AggOR are introduced in Section 3, and Section 4 details the implementation of AggOR. Experimental results are analyzed in Section 5, and Section 6 concludes this paper.
2. Related Work
Data aggregation is utilized in WSNs to diminish the resource consumption of redundant data when delivering information from sensor nodes to the sink. In specific, data aggregation schemes could be classified into three kinds, i.e., tree-based aggregation [9,10,11,12], hybrid aggregation [13], and cluster-based aggregation [14,15,16,17,18,19,20,21,22].
In classical tree-based data aggregation schemes, a spanning tree rooted at the sink is constructed firstly, and then data are forwarded from leaves to root along the paths in the tree. In Tiny AGgregation (TAG) [10], after leaf nodes send their own data to their parent, the parent node aggregates data from its children and delivers the aggregated data to the root. Obviously, TAG is inefficient in case of dynamic topologies or link/device failures. In [11], Deligiannakis et al. propose an aggregation tree construction/reorganization algorithm to minimize energy cost. By calculating and sending a small set of intuitive statistics, a parent node may be substituted by one of its sibling nodes based on attachment cost. In [12], an adaptive spanning tree algorithm (AST) is proposed, which adaptively builds and adjusts an aggregation spanning tree. Owing to the strategies of random waiting times and alternative father nodes, AST establishes a relatively balanced spanning tree with flexible adjustments. Considering that a single packet, as the output of aggregation algorithm at a given level of the tree, may stand for all the data coming from a subtree, if it is lost, the entropy from this subtree might be lost as well.
As a typical hybrid data aggregation scheme, Tributary-Delta [13] combines the advantages of tree and multi-path by implementing them simultaneously in different regions of the network. It supports region adjustment in response to network condition changes, and determines the number of useful aggregates in the scenario. However, it may have a high overhead because of frequent update of the data gathering structure.
Compared with tree-based and hybrid schemes, cluster-based aggregation schemes usually have good scalability and high energy efficiency [14,15]. Considering that the cluster heads, which are close to the sink, relay data for others, in [16], Li et al. propose an energy-efficient unequal clustering scheme (EEUC). Cluster heads are elected by localized competition, and the competition range becomes small when it is near the base station. Therefore, those clusters closer to the sink have smaller sizes than others, and the energy consumption of cluster heads is balanced. Even though, the cluster maintenance is somewhat difficult.
In recent years, some cluster-based schemes analyze various factors to select a cluster head from several candidates. In DHCR [17], energy consumption, adjustment degree and exact distance from sensors to the base station are three main parameters for cluster head selection. Multi-hop routing and clustering are combined to decrease the number of control packets. In [18], Leu et al. propose REAC-IN to evenly distribute cluster heads based on the residual energy of each sensor and the average energy of sensors in the cluster. Together with isolated node checking considering power and distance, REAC-IN improves the cluster head selection process and avoids node isolation. To save energy for cluster reformation, Yi and Yang propose Hamilton energy-efficient routing protocol (HEER) [19]. Members in each cluster are linked on a Hamilton Path, and take turns to work as cluster head. In this way, no cluster reformation is required. However, the clusters are formed like LEACH in the first round, which may cause energy hole problem; the condition that all members in a cluster could communicate with each other is strict; the intra-cluster nodes in the Hamilton Path transmitting data in turn prolong the end-to-end delay.
Moreover, some existing studies exploit spatial correlation to set aggregation areas. In YEAST algorithm, those nodes detecting the same event are grouped in a cluster and the cluster head is the node closest to the sink [20]. The cluster is divided into spatially correlated cells, and only one node within each cell transfers its data to its cluster head, which stand for all the sensing data in this cell. Cells can be resized dynamically according to the application requirements. However, the bigger cells become, the less the entropy is. Since a representative node’s sensing area could not cover the whole cell, YEAST causes low accuracy to some extent. For several synchronous events, DRINA [21] tends to maximize the number of aggregation nodes and decrease the overhead of control packets. Nodes sensing the same event form a cluster, and a route for a new event is connected with an already established route which has the shortest path between them. Experiment results show that DRINA has a high aggregation rate, and reliable data aggregation and transmission. Nevertheless, it increases the overload of nodes in existing routes, and thus leads to unbalanced energy consumption and even the energy-hole problem.
In the above aggregation schemes, those nodes located in a particular area usually compose a cluster. If the area is too large, the similarity of data gathered by member nodes is small; if the area is too small, the advantage of data aggregation is degraded. In order to balance aggregation efficiency and data accuracy, we explore the relation of sensing areas of nodes to deal with redundant data, and utilize a threshold of overlapping sensing area to guarantee high accuracy after data aggregation.
3. Network Model and Aggregation Rules
3.1. Network Model
In this paper, we assume that all sensor nodes have the same sensing radius, denoted by , and the same communication radius, denoted by () [23]. The data collected by sensor networks may be periodic sensing information, such as the average temperature, or information triggered by specific events, such as fire alerts. Our scheme focuses on the periodic data collection, and assumes that the amount of information collected is the same for all the nodes, which is a common assumption about data collection [24]. The data collected by each node is denoted by d. Since the sink usually has sufficient power, we only consider the energy cost of sensor nodes in our scheme. Because data sending (the amount of data sent out from node is denoted by ) and receiving (the amount of data received by node is denoted by ) consume most of the energy, small energy consumptions such as the cost of data processing are ignored. Therefore we focus on the transmission overhead in AggOR. For simplicity, we assume that total energy consumption of node is , where and are the energy costs for sending and receiving per unit data, respectively. The primary symbols used in AggOR are listed in Table 1.
Table 1.
Symbols.
| Symbol | Description |
|---|---|
| Sensing radius of a sensor node. | |
| Communication radius of a sensor node. | |
| Consumed energy of sending per unit data. | |
| Consumed energy of receiving per unit data. | |
| d | The size of data collected by a sensor node. |
| Overlapping rate of sensing area of two nodes and . | |
| Threshold of overlapping rate of sensing area. | |
| Gathering area with as the gathering node. | |
| Gathering node, which aggregates the data collected in a gathering area. | |
| Candidate gathering node set of . | |
| Candidate parent node set of , including all the upper-level nodes that couldcommunicate with directly. | |
| Neighbor node set of , which consists of the nodes at the same level that couldcommunicate with directly. | |
| Level of , and . | |
| The total amount of data transferred from . | |
| The total amount of data received by . | |
| The energy consumed for delivering aggregated data from the gathering node . | |
| The total energy cost of the nodes in the gathering area . | |
| The total energy cost of transmitting data of node to the sink via another node . | |
| Free nodes at the level n. |
Before presenting the details of AggOR, several definitions are introduced as follows.
Definition 1.
Transmission hierarchy diagram: The diagram is a directed acyclic graph, including all the sensors, the possible communication paths, and the hierarchy levels (denoted by L). It is similar to a tree structure rooted at the sink, but the parent node is not unique.
For data collection in a dense network, we only care about those nodes which can communicate with the sink through one-hop or multi-hop transmissions. For two levels and in the diagram, is called upper-level and is called lower-level. In other words, the value of upper-level is smaller than that of lower-level. As shown in Figure 1, there are m sensor nodes in the network as well as as the sink. The edges show the communication chances between nodes. Specifically, the solid lines indicate the possible parent-child relations between lower-level and upper-level nodes, while dotted lines show the neighbor relations between nodes at the same level.
Figure 1.

Transmission hierarchy diagram.
Definition 2.
Overlapping rate of sensing area, : The ratio of the overlapping sensing area of two nodes and to a node’s entire sensing range ().
Furthermore, considering that the two nodes with a larger overlapped sensing area probably have a larger similarity of the collected data, we assume that the amount of duplicated data at two sensors is proportional to the overlapping rate of sensing area. Our aggregation only removes redundant data, and thus the entropy of the sensing data in the whole network is not lost. In other words, the aggregation works like a lossless compression approach whose compression ratio is the overlapping rate of sensing area.
In order to construct gathering areas, a threshold of overlapping rate of sensing area, denoted by , is utilized. The assignment of affects the aggregation efficiency. The smaller is, the larger the gathering area is, but the smaller the amount of duplicated data between nodes is. Further analysis of is in Section 5.3.2.
As shown in Figure 2, take the overlapping sensing area of and in Figure 1 as an example. Two dashed circles represent the sensing ranges of two nodes, respectively, and the hatched area is the overlapping sensing area, denoted by . Therefore the overlapping rate of sensing area of and is computed by . In order to calculate , we denote the distance between and by . According to geometric theory, the overlapping sensing area is . To remove the complicated calculation of inverse trigonometric functions, using curve fitting mechanism [25], could be computed as . Therefore, .
Figure 2.

Overlapping rate of sensing area.
Definition 3.
Gathering area, : A gathering area is composed of a gathering node and several member nodes, and the overlapping rate of sensing area between the gathering node and each member node equals or is larger than .
The gathering node is responsible for collecting and aggregating all the sensor data in the gathering area and then sending the result toward the sink, while the member node transfers its data to the gathering node. A gathering area with node as its gathering node and ,…, as its member nodes is expressed by . One node belongs to at most one gathering area. If a node does not find a gathering node, turns into an independent node and forms a gathering area by itself as . If a node is not a gathering node, it is called non-gathering node; if a node does not join in a gathering area, it is called free node.
Definition 4.
Candidate parent nodes of , : A set consists of the nodes at level and in the communication range of .
Definition 5.
Neighbor nodes of , : A set includes the nodes at level which can communicate with .
Definition 6.
Candidate gathering nodes of , : A set includes all the nodes which might be the gathering node of . In AggOR, .
As an instance, Figure 3 shows a transmission hierarchy diagram having three gathering areas, i.e., , , and . The arrows indicate the directions of data transfers. Therefore, , and send their data to which aggregates these data with its own data, and then sends the results to the sink; transfers its data to , and aggregates these data; sends its data to the sink directly.
Figure 3.

An instance of wireless sensor network (WSN) with three gathering areas.
3.2. Aggregation Rules
We have three aggregation rules for the gathering area construction. Although in general, is slightly smaller than which is relevant with the transmission distance, to simplify the explanations of these rules, we assume and .
Rule 1. In gathering areas, the upper-level nodes have priorities over the lower-level nodes to be selected as gathering nodes.
We evaluate the validity of Rule 1 in an instance gathering area with a upper-level node and a lower-level node . Apparently, .
Case 1: is the gathering node. After joins the gathering area , as the member node sends d data to . Thus , and . After data aggregation, transmits additional data as well as its own data d. Hence, . Since these data need to be forwarded to the sink through hops. The energy consumed for delivering aggregated data from the gathering node is . Therefore, the total energy consumption of those nodes in the gathering area is computed by
| (1) |
Case 2: is the gathering node. Similarly, the total energy cost of data delivery from those nodes in to the sink is
| (2) |
Obviously . Because only replicated data are cleaned in aggregation, no matter which node is the gathering node, the quantities of information after aggregation are the same. As a result of a higher level of the gathering node, Case 1 has more energy consumed than Case 2. Thus selecting the gathering nodes from the upper-level nodes is better than from the lower-level nodes.
Rule 2. After the lower-level nodes complete the construction of gathering areas, the free nodes at the upper level firstly select their gathering nodes from the candidate parent nodes. If no suitable candidate parent node exists, then select from the neighbor nodes.
Assume that (the current node) is selecting a gathering node. is its candidate parent node, while is a neighbor node of . Hence .
Case 1: and . In this case, select or to be its gathering node. If is the gathering node of , receives data of size d from and transfers additional data as well as its own data after aggregation. The total energy cost of transmitting data from to the sink via is
| (3) |
Otherwise, if chooses as its gathering node, the total energy cost for data delivery from to the sink via is
| (4) |
where .
Comparing and , we know that if (in other words, ), then , and is larger than by at least . When , considering , we obtain that if , then . Accordingly, if , might be smaller than . Note that to guarantee a relatively high data correlation, is often larger than 0.4 (as discussed in Section 5.3.2), and thus . If (), then has some probability to be smaller than . In our experiments, it is rare to achieve this strict condition in networks. Therefore, in general, . The gathering node selection from the candidate parent node is more energy-efficient than from the neighbor node.
For instance, we discuss about how (the current node) selects its gathering node from and . In Figure 4, , , . The total energy cost of transmitting data of to the sink via is , while that of selecting as the gathering node of is . Therefore, , which is consistent with above analysis.
Figure 4.

Gathering node selection for .
Case 2: and . chooses as its gathering node, according to Rule 1. From Case 1 and Case 2, when gets , selects its gathering node from the candidate parent nodes, and does not need to calculate the overlapping rates of sensing area with its neighbor nodes.
Case 3: and . Node has two ways to send its data. One option is that becomes an independent node while is its relay node, and the total energy consumption of transmitting data of to the sink via is
| (5) |
The other option is taking as ’s gathering node, and the total energy cost is shown in Equation (3). Hence . If , then , and chooses as its gathering node. In one word, if there is no candidate parent node subject to , a neighbor node with and is selected as the gathering node of . Furthermore, if no such neighbor node exists, becomes an independent node.
Case 4: and . Considering the weak similarity, it is not necessary to aggregate the data from these nodes. Therefore, becomes an independent node, delivering its data to the sink without aggregation.
In conclusion, for free nodes, their candidate parent nodes have high priorities to be the gathering nodes. If all the candidate parent nodes have lower overlapping rates of sensing area than the threshold, then the neighbor nodes are considered to aggregate data.
Rule 3. Data from every node is aggregated at most once, and in relay node selection, the non-gathering nodes take priorities over the candidate parent node with the most residual energy.
Since data similarity is small between different gathering areas, data aggregation inter gathering areas probably has no significant advantages. Additionally, the data collection and processing for further aggregations may prolong the end-to-end delay. Consequently, in AggOR, taking into account the original data from each node, the aggregation executes at most once.
Obviously, the gathering nodes consume more power than the member nodes and the independent nodes, and thus are not suitable as relay nodes which need to contribute extra energy for data forwarding. Selecting non-gathering nodes as relays helps to balance the energy consumption in the entire network and prolong the network lifetime. If no non-gathering node exists, take the candidate parent node with the most remaining energy as the forwarder.
4. Implementation of AggOR Scheme
The transmission hierarchy diagram of WSN is constructed based on hello messages exchange between sensor nodes. Hello message includes the sender’s ID, coordinates, residual energy and the level. At the beginning, all sensor nodes initialize their levels as infinity, and the sink floods hello message including its level 0. Then other nodes update their levels after receiving hello messages. In specific, after receiving a hello message, checks if the difference of its stored level and the level in the hello message is larger than 1. If it is true, updates with the level in hello message plus 1, and then disseminates its hello message with the updated level; otherwise, if the level in the message is , adds the ID in the message to its candidate parent node set ; if the levels are the same, inserts the ID to its neighbor node set .
A topology under construction is illustrated in Figure 5 where the numbers are levels of nodes. Take node as an example; its and are illustrated.
Figure 5.

An instance topology under construction.
4.1. Gathering Area Construction
After transmission hierarchy diagram is completed, sensor nodes start to form the gathering area in a distributed manner. Gathering area construction begins from the lower-level free nodes to the upper-level layer by layer and follows the three aggregation rules in Section 3.2. In the construction process, a free node may be chosen as a gathering node in a new gathering area, or join in an existing gathering area as a member node, or become an independent node. Take as an instance; its gathering area construction algorithm is shown in Algorithm 1, a core of which is finding the candidate gathering node set as shown in Algorithm 2.
| Algorithm 1: Gathering Area Construction. |
 |
The network is initialized that all the sensor nodes are free nodes and there are levels in the transmission hierarchy diagram. Levels are numbered as 0, 1, 2, …, n. Then the nodes at level n start constructing gathering areas firstly. For a node whose level is larger than 1, it calculates the overlapping rates of sensing area and obtains its candidate gathering node set through Algorithm 2. If is empty, becomes an independent node; otherwise, chooses the node in which has the most residual energy as its gathering node, and sends the request to be a member node in the gathering area . For the free nodes at level 1, it is unnecessary to select the sink as gathering node, and their overlapping rates of sensing area with their neighbor nodes cannot be larger than 2 (Rule 2). Therefore each free node at level 1 turns into an independent node.
| Algorithm 2: Finding Candidate Gathering Node Set. |
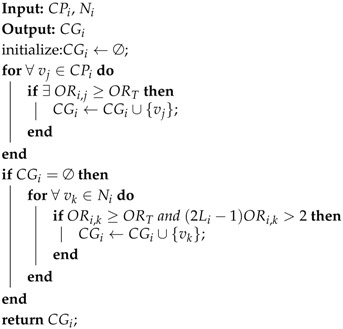 |
Algorithm 2 returns , as the set of candidate gathering nodes of . For every candidate parent node , if , is included in . If there is no candidate gathering node selected from the candidate parent nodes, calculates the overlapping rates of sensing area with its neighbor nodes. If a neighbor node satisfies and , is included in .
4.2. Data Routing
In the process of data routing, member nodes send data to their gathering nodes through one hop transmission, while gathering nodes aggregate data collected in their gathering areas and then send them to the sink through the energy-efficient paths. Additionally, independent nodes send their own data to the sink without aggregation. The energy-efficient paths are established according to Rule 3, in which the non-gathering nodes are the first choice for relay nodes and then the candidate parent nodes with the most residual energy are selected as forwarders.
An instance of the construction of gathering areas and the data routing is depicted in Figure 6, which is the part in dotted circle of Figure 5. We suppose that has more residual energy than , and . All the nodes in the network are initialized as free nodes, i.e., , and . At the beginning, and , at the highest level 3, calculate the overlapping rates of sensing area with their candidate parent nodes. We get and . Thus and . Due to more residual energy, is selected by and as their gathering node, . Then and . Next the free nodes and at level 2 construct their gathering areas. Similarly, regarding the candidate parent nodes, , and . Therefore, and . Node chooses as it gathering node, . Since , further calculates overlapping rate of sensing area with its neighbor node , and gets . Because there is no other neighbor node, , and chooses as its gathering node, . After that, and . at the level 1 becomes an independent node, and . For the data transmission, , and send their data to , aggregates data in and then chooses (non-gathering node) to relay its data to the sink. Node sends data to which aggregates and forwards data to the sink, while sends its data to the sink directly.
Figure 6.

An example of AggOR implementation.
4.3. Complexity Analysis
In order to testify the validity and efficiency of AggOR, we analyze its complexity in terms of computation, message and storage complexity. The computation complexity of Algorithm 2 (finding candidate gathering node set) is , where m is the number of sensor nodes in the network. It means in the worst case, a node visits all its candidate parent nodes and its neighbor nodes to find its candidate gathering nodes . Accordingly the computation complexity of Algorithm 1 (gathering area construction) is . Since the number of elements in , and are all less than m, the complexity of our algorithms is .
In the process of transmission hierarchy diagram construction, sink starts flooding hello message and other nodes broadcast it after reception. Thus the control message cost is m. When constructing gathering areas, node sends join message to its potential gathering node, and after receiving acceptance message from it, sends acknowledgement message to join the gathering area. Hence in this process the message cost is . Overall, the message complexity of AggOR is .
For the control information, since each node stores its overlapping rates of sensing area with nearby nodes, candidate parent node set, neighbor node set, level and remaining energies of its candidate gathering nodes, the storage complexity is . In addition, for the data packets, every member node only carries its own data, while each gathering node caches the data from its member nodes. Considering that data aggregation is implemented at one-hop distance, the number of data packets collected by a gathering node is usually far less than m, with the storage complexity .
To sum up, compared with EEUC, whose message complexity is , and HEER, whose message complexity is and computation complexity is exponential, our distributed scheme AggOR has relatively low complexities of computation, message and storage.
5. Performance Evaluation
5.1. Network Configurations
We evaluate the performance of AggOR scheme on OPNET Modeler [26] network simulation platform. The network configurations are listed in Table 2. Note that sensor nodes are evenly distributed in the monitoring field.
Table 2.
Simulation parameters.
| Parameter | Value |
|---|---|
| Scenario (m) | |
| Number of sink node | 1 |
| Number of sensor nodes, N | 40, 80, 120, 160 and 200 |
| Sensing radius (m) | 25 |
| Communication radius (m) | 52 |
| Data collection cycle (s) | 60 |
| 0.5 |
We select a typical scheme EEUC and a newly proposed scheme HEER to be our comparisons. EEUC is a distributed cluster mechanism where cluster heads are elected by localized competition. Through a function of the competition range which is decided by the distance to the base station, several tentative cluster heads are elected to compete for final cluster heads. After the cluster head selection, other nodes join in their closest cluster heads. HEER, as a chain-based protocol, constructs clusters like LEACH, and establishes a Hamilton Path in each cluster to set an order for sensors to transmit data. In order to evaluate different gathering node selection methods, we take a variation of AggOR as comparison, in which the gathering nodes are only selected from candidate parent nodes (not considering the neighbor nodes), named AggOR-CP.
Note that the data sizes after aggregation are not the same in different schemes. In AggOR, after a gathering node aggregates x data packets, the amount of output data is , which is decided by the overlapping rates of sensing area in this gathering area. Since the data aggregation function only removes duplicated data relevant with the overlapping sensing area, the whole data obtained by the sink are complete and accurate. However, in EEUC and HEER, a packet with a fixed amount of data is output by aggregating several data packets.
The following metrics are used for the performance evaluation.
-
(1)
Network lifetime: the time interval from the beginning of the network to the death of the first node.
-
(2)
Transmission overhead: the total amount of data transmitted in one data transmission round. It indicates the energy consumption of data sending and receiving in the whole network.
-
(3)
Maximum number of hops to the sink: the maximum number of hops from sensor nodes to the sink in the network. More hops mean a longer time for which the sink has to wait to collect all the data in the scenario. Hence it implies the data delivery delay.
-
(4)
Information accuracy: the ratio of the amount of information collected by the sink to the amount of information in all raw data.
Considering that sensor density may influence the performance of data aggregation, we will discuss about this issue in Section 5.3.1. In addition, the threshold of overlapping rate of sensing area is a significant factor affecting the size of gathering area and the energy efficiency of AggOR scheme. Therefore, we will analyze the influences of this threshold in Section 5.3.2. Moreover, we consider three scenarios corresponding to different shapes of monitoring field and different locations of the sink in the network. In Scenario SP, the nodes are deployed in a pyramid field, of which the top is the sink. In Scenario SC, the sink is placed at the center of a circular field. Scenario SS has a square field with the sink in the top-left corner. Note that in all the scenarios, sensor nodes are uniformly deployed. We will analyze the sources of gathering nodes in AggOR and AggOR-CP with different , in Section 5.3.3.
5.2. Experiment Results
We evaluate the performances of four schemes, i.e., HEER, EEUC, AggOR-CP and AggOR, and the results are illustrated in Figure 7. Note that the experiments are conducted in Scenario SP. With the number of sensors increasing, the density of nodes does not change. In other words, the results are obtained under different network scales with the same density. Specifically, the networks with 40, 80, 120, 160 and 200 nodes cover approximately 20%, 40%, 60%, 80% and 100% of the whole m scenario, respectively.
Figure 7.

Experiment results. (a) network lifetime; (b) transmission overhead; (c) maximum hops to the sink; (d) information accuracy.
As Figure 7a shows, when there are 40 nodes in the network, EEUC has the longest lifetime of the network, and AggOR tightly follows. However, with the number of nodes increasing, the lifetime of AggOR which is longer than AggOR-CP, gradually exceeds EEUC from the scale of 120 nodes, and the lifetime of HEER is the shortest. Even though in EEUC scheme, the clusters output a single length-fixed packet after aggregation, which is smaller than the output of gathering nodes in AggOR, the main reasons of the result lie in two aspects. (1) The redundant data is forwarded for several hops in EEUC while redundancy is only relayed once in AggOR; (2) Compared with EEUC in which the cluster heads may be at lower levels, in AggOR, the gathering nodes are mainly the upper-level nodes, and thus sensor data are always forwarded up avoiding the back and forth relay.
Note that there are different ways to define the dead time of the network. If the sensing range of the first dead node is covered by others, the network might continue to work. Therefore, beside the death of the first node, we analyze the network lifetime, which takes the time when some area cannot be sensed any longer or some data cannot be delivered to the sink as the dead time. The results are shown in Figure 8. The network lifetimes of all the four schemes in Figure 8 are a little longer than or the same as those in Figure 7a, because the sensing areas of some first dead nodes are covered by others and some first dead nodes are the gathering nodes or the forwarders for others. However, the trends of the results in these two figures are similar, both showing that our scheme AggOR achieves a similar network lifetime to EEUC and a little longer lifetime than HEER.
Figure 8.

Another definition of network lifetime.
Figure 7b demonstrates that the transmission overhead in AggOR is a little smaller than those in AggOR-CP and EEUC schemes when the number of nodes is 80. As the number of nodes increases, the transmission overheads of HEER, EEUC and AggOR-CP are increasing faster than AggOR. AggOR has a smaller transmission overhead than AggOR-CP, EEUC and HEER by about 4%, 10% and 17% respectively in the scenario with 200 nodes. HEER always has the highest overheads among the compared schemes.
Because the maximum hops in multiple tests for HEER is not stable, we use median values rather than average values in Figure 7c. From the figure, AggOR-CP has the smallest and stable number of hops, while AggOR in some rare cases has more hops than others. This is because in our scenarios with , all the gathering nodes in AggOR-CP are the upper-level nodes, while there are some neighbor nodes as gathering nodes in AggOR, slightly increasing the number of hops in data transmission. As the number of nodes increases, the maximum hops of EEUC and HEER schemes are more unstable and larger than AggOR, especially HEER. When there are 200 nodes, the maximum hops in AggOR is smaller than EEUC and HEER by 12% and 25% respectively. The main reason is that member nodes send data to their gathering nodes by just one hop both in AggOR and AggOR-CP. By contrast, there exists multi-hop routing in clusters of EEUC, and in HEER the members transfer their data to cluster heads following Hamilton Paths, which increase hops to the sink and prolong the end-to-end delay.
As Figure 7d illustrates, in AggOR the ratio of information accuracy is the highest (around 88%) among those four schemes and very similar to AggOR-CP, which is higher than EEUC and HEER by 38% and 48% respectively. This is because aggregating lots of data into a small fixed amount of data and aggregating the same data for several times both affect the information accuracy. In HEER, the end node of Hamilton Path transmits its data to its neighbor which is closer to the cluster head, and the neighbor aggregates data into one packet of a constant size. This process continues until the data reaches the cluster head. Therefore, an original data may be aggregated for several times. In EEUC, the clusters aggregate all member data into one packet with fixed size, regardless of the specific redundancy ratios. By contrast, AggOR aggregates one data only once, and does not lose any information. Note that the ratio of information accuracy in AggOR is not 100% because of the redundant data.
In conclusion, AggOR scheme achieves an energy-efficient and quick data collection, while ensuring a high data accuracy. Moreover, AggOR has a greater advantage over other schemes when the network scale rises, because the efficiency of redundancy clearing within only one-hop forwarding is apparent in a large scale scenario.
5.3. Parameter Analysis
5.3.1. Sensor Density Analysis
We analyze the effects of node density on the performances of all the four schemes in the fixed m zone area. The numbers of nodes are 50, 100, 150 and 200, respectively. Accordingly, the sensor density ranges from 0.005 to 0.02 nodes per square meter. The results are illustrated in Figure 9.
Figure 9.

Results with different sensor densities. (a) network lifetime; (b) transmission overhead; (c) maximum hops to the sink; (d) information accuracy.
In Figure 9, a high density leads to short network lifetimes and large transmission overheads for all the schemes, while the maximum hops to sink and the information accuracy do not change a lot. Additionally, as the sensor density increases, AggOR scheme, which always presents a high data accuracy and short transmission route in the experiments, begins to show longer lifetime and better energy efficiency than EEUC and HEER. On the whole, AggOR performs the best among the compared schemes with different sensor densities, especially in high-density sensor networks.
5.3.2. Analysis of the Threshold of Overlapping Rate of Sensing Area
In order to show the impacts of the threshold of overlapping rate on the overall performances of AggOR and AggOR-CP, we conduct a series of experiments in Scenario SP with ranging from 0 to 1. Figure 10 shows the simulation results. The solid line, intermittent line and chain dotted line indicate the three scenarios with 120, 160 and 200 nodes, respectively. In Figure 10, the results are stable when or , because in our dense WSN, all the overlapping rates of sensing area between two nodes are larger than 0.4 and smaller than 0.8.
Figure 10.

Results with different . (a) network lifetime; (b) transmission overhead; (c) maximum hops to the sink.
In Figure 10a, when , all gathering nodes are candidate parent nodes and almost no independent node exists. When increases to 0.5, the network lifetime prolongs a little, because the gathering areas are constructed efficiently with the larger overlapping sensing area as well as some neighbor nodes selected as gathering nodes. When continues to increase, less candidate parent nodes and more neighbor nodes are selected as the gathering nodes, which increases energy cost. Additionally, more independent nodes also limit the benefits of data aggregation. Therefore, with a medium value 0.5 of , AggOR reaches the longest network lifetime. Moreover, the network lifetime of AggOR is superior to that of AggOR-CP.
Figure 10b depicts that, when there are 120 or 200 nodes, the smallest transmission overhead appears in AggOR when is 0.5. It is obvious that the larger is, the higher transmission overhead there is due to less aggregation. In addition, transmission overhead in AggOR is smaller than AggOR-CP, and large scale leads to a bigger difference between them. It is consistent with our previous analysis that the neighbor nodes working as gathering nodes cost less energy for data transmission than independent nodes.
Data collection and aggregation by the gathering nodes cause a little delay apparently, and the neighbor nodes as the gathering nodes further increase the hops to the sink. When rises, the median value of maximum hops to the sink in AggOR is bigger than AggOR-CP, as shown in Figure 10c. However, the largest difference between them appears when is larger than 0.6 and the difference is one hop, which implies that there are no candidate parent nodes suitable to be gathering nodes for some node on the longest path to the sink.
5.3.3. Gathering Node Analysis
Considering that the number of gathering nodes indicates the efficiency of data aggregation, we analyze the number of gathering nodes and the number of independent nodes, in three scenarios, i.e., SP, SC and SS, with 160 nodes. The results are illustrated in Figure 11 and Figure 12.
Figure 11.

The numbers of gathering nodes in three scenarios. (a) Scenario SP; (b) Scenario SC; (c) Scenario SS.
Figure 12.

The numbers of independent nodes in three scenarios. (a) Scenario SP; (b) Scenario SC; (c) Scenario SS.
In different scenarios, the numbers of two kinds of nodes are similar with the same . Comparing the numbers of gathering nodes in AggOR and AggOR-CP in Figure 11, we get that when is smaller than 0.5, no neighbor nodes are selected as gathering nodes. In Figure 12, when increases from 0.5, AggOR-CP has more independent nodes than AggOR. When is larger than 0.8, the numbers of gathering nodes and the numbers of independent nodes both reach plateaus. Specifically, all nodes in AggOR-CP are independent nodes, while AggOR has some neighbor nodes selected as gathering nodes, and hence reduces the transmission overhead.
Figure 13 shows the sketch maps of three scenarios, i.e., SP, SC and SS, with 80 nodes in AggOR. The edges indicate the relationships between gathering nodes and member nodes. Due to the limited spaces, to avoid confusion caused by crossing lines, we do not show the data transmission paths from the gathering nodes to the sink. From the figure, we get that the gathering nodes are usually located near their member nodes, and most of them are closer to the sink than member nodes.
Figure 13.

Sketch maps of three scenarios. (a) Scenario SP; (b) Scenario SC; (c) Scenario SS.
Overall, the larger the sensor density is, the better AggOR performs. In a relatively dense network, a larger network scale leads to a greater advantage of AggOR over EEUC and HEER. Additionally, has a significant effect on the performance of AggOR, which peaks at in our experiments. In real scenarios, an appropriate can be obtained through sampling analysis during preliminary study. Furthermore, AggOR has a longer network lifetime and a smaller traffic overhead than AggOR-CP in the three scenarios with different sensor deployments and different locations of the sink.
6. Conclusions
Wireless sensor networks are deployed to support a variety of precise monitoring applications in smart factories, and require energy-efficient and no-entropy-loss data aggregation. In this paper, we propose a data aggregation scheme based on the overlapping rate of sensing area, named AggOR. In the transmission hierarchy diagram, some candidate parent nodes as well as appropriate neighbor nodes, whose overlapping rates of sensing area are not smaller than a preset threshold , may be selected as the candidate gathering nodes. It guarantees that the sensor data in a gathering area are extremely correlative, and there exist a large amount of redundant data to be cleaned. Member nodes transfer their data to gathering nodes through one hop, and only duplicated data are removed by aggregation, ensuring a short end-to-end delay and a high data accuracy. A large quantity of experiments on OPNET modeler show that AggOR has a better data accuracy and a shorter delay than compared schemes, while keeping similar network lifetime.
However, the specific relation between and network density still requires further study. In addition, considering the occurrence of multiple events at the same time [27], how to optimize multi-event data collection by analyzing overlapping sensing area is another research topic for the future.
Acknowledgments
We gratefully acknowledge the support from the National Natural Science Foundation of China (61502320, 61373161 & 61572060), Science & Technology Project of Beijing Municipal Commission of Education in China (KM201410028015), Youth Backbone Project of Beijing Outstanding Talent Training Project (2014000020124G133), 973 Program (2013CB035503), CERNET Innovation Project (NGII20151004, NGII20160316), Beijing Advanced Innovation Center for Imaging Technology, Cultivation Object of Young Yanjing Scholar of Capital Normal University and Science Foundation of Shenzhen City in China (JCYJ20160419152942010).
Author Contributions
X.T. conceived and designed the study; H.X. performed the experiments and wrote the paper; W.C. and J.N. supervised the research; S.W. revised the paper.
Conflicts of Interest
The authors declare no conflict of interest.
References
- 1.Yang J., Zhou J., Lv Z., Wei W., Song H. A real-time monitoring system of industry carbon monoxide based on wireless sensor networks. Sensors. 2015;15:29535–29546. doi: 10.3390/s151129535. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Tang X., Pu J., Gao Y., Xiong Z., Weng Y. Energy-efficient multicast routing scheme for wireless sensor networks. Trans. Emerg. Telecommun. Technol. 2014;25:965–980. doi: 10.1002/ett.2661. [DOI] [Google Scholar]
- 3.Jeschke S., Brecher C., Song H., Rawat D. Industrial Internet of Things: Cyber Manufacturing Systems. Springer; Berlin, Germany: 2017. [Google Scholar]
- 4.Shu L., Mukherjee M., Hu L., Bergmann N., Zhu C. Geographic Routing in Duty-cycled Industrial Wireless Sensor Networks with Radio Irregularity. IEEE Access. 2016;4:9043–9052. doi: 10.1109/ACCESS.2016.2638441. [DOI] [Google Scholar]
- 5.Shu L., Wang L., Niu J., Zhu C., Mukherjee M. Releasing network isolation problem in group-based industrial wireless sensor networks. IEEE Syst. J. 2015;1:1–11. doi: 10.1109/JSYST.2015.2475276. [DOI] [Google Scholar]
- 6.Kumar A., Baksh R., Thakur R.K., Singh A.P. Data aggregation in wireless sensor networks. Int. J. Sci. Res. 2014;3:249–251. [Google Scholar]
- 7.Singh S.P., Sharma S.C. A survey on cluster based routing protocols in wireless sensor networks. Comput. Sci. 2015;45:687–695. doi: 10.1016/j.procs.2015.03.133. [DOI] [Google Scholar]
- 8.Zeb A., Islam A.K.M.M., Zareei M., Mamoon I.A., Mansoor N., Baharun S., Katayama Y., Komaki S. Cluster analysis in wireless sensor networks: The ambit of performance metrics and schemes taxonomy. Int. J. Distrib. Sens. Netw. 2016;12:4979142. doi: 10.1177/155014774979142. [DOI] [Google Scholar]
- 9.Fasolo E., Rossi M., Widmer J., Zorzi M. In-network aggregation techniques for wireless sensor networks: A survey. IEEE Wirel. Commun. 2007;14:70–87. doi: 10.1109/MWC.2007.358967. [DOI] [Google Scholar]
- 10.Madden S., Franklin M.J., Hellerstein J.M., Hong W. TAG: A tiny aggregation service for ad-hoc sensor networks. ACM SIGOPS Oper. Syst. Rev. 2002;36:131–146. doi: 10.1145/844128.844142. [DOI] [Google Scholar]
- 11.Deligiannakis A., Kotidis Y., Stoumpos V., Delis A. Building efficient aggregation trees for sensor network event-monitoring queries. Int. Conf. GeoSens. Netw. 2009;5659:63–76. [Google Scholar]
- 12.Zhang Y., Pu J., Liu X., Chen Z. An adaptive spanning tree-based data collection scheme in wireless sensor networks. Int. J. Distrib. Sens. Netw. 2015;2015:637387. doi: 10.1155/2015/637387. [DOI] [Google Scholar]
- 13.Manjhi A., Nath S., Gibbons P.B. Tributaries and deltas: Efficient and robust aggregation in sensor network stream; Proceedings of the 2005 ACM SIGMOD International Conference on Management of Data; Baltimore, MD, USA. 14–16 June 2005; pp. 287–298. [Google Scholar]
- 14.Shukla K.V. Research on energy efficient routing protocol LEACH for wireless sensor networks. Int. J. Eng. 2013;2:1–5. [Google Scholar]
- 15.Younis O., Fahmy S. HEED: A hybrid, energy-efficient, distributed clustering approach for Ad hoc sensor networks. IEEE Trans. Mob. Comput. 2004;3:660–669. doi: 10.1109/TMC.2004.41. [DOI] [Google Scholar]
- 16.Li C., Ye M., Chen G., Wu J. An energy-efficient unequal clustering mechanism for wireless sensor networks; Proceedings of the 2005 IEEE International Conference on Mobile Adhoc and Sensor Systems Conference (MASS); Washington, DC, USA. 7 November 2005; pp. 597–604. [Google Scholar]
- 17.Sabet M., Naji H.R. A decentralized energy efficient hierarchical cluster-based routing algorithm for wireless sensor networks. AEU Int. J. Electron. Commun. 2015;69:790–799. doi: 10.1016/j.aeue.2015.01.002. [DOI] [Google Scholar]
- 18.Leu J.S., Chiang T.H., Yu M.C., Su K.W. Energy efficient clustering scheme for prolonging the lifetime of wireless sensor network with isolated nodes. IEEE Commun. Lett. 2015;19:259–262. doi: 10.1109/LCOMM.2014.2379715. [DOI] [Google Scholar]
- 19.Yi D., Yang H. HEER-A delay-aware and energy efficient routing protocol for wireless sensor networks. Comput. Netw. 2016;104:155–173. doi: 10.1016/j.comnet.2016.04.022. [DOI] [Google Scholar]
- 20.Villas L.A., Boukerche A., de Oliveira H.A.B.F., de Araujo R.B., Loureiro A.A.F. A special correlation aware algorithm to perform efficient data collection in wireless sensor networks. Ad Hoc Netw. 2011;12:10–30. [Google Scholar]
- 21.Villas L.A., Boukerche A., Ramos H.S. DRINA: A lightweight and reliable routing approach for in-network aggregation in wireless sensor networks. IEEE Trans. Comput. 2013;64:676–689. doi: 10.1109/TC.2012.31. [DOI] [Google Scholar]
- 22.Gherbi C., Aliouat Z., Benmohammed M. An adaptive cluster approach to dynamic load balancing and energy efficiency in wireless sensor networks. Energy. 2016;114:647–662. doi: 10.1016/j.energy.2016.08.012. [DOI] [Google Scholar]
- 23.Pu J., Gu Y., Zhang Y., Chen J., Xiong Z. A Hole-Tolerant Redundancy Scheme for Wireless Sensor Networks. Int. J. Distrib. Sens. Netw. 2012;2012:184–195. doi: 10.1155/2012/320108. [DOI] [Google Scholar]
- 24.Imon S.K.A., Khan A., Francesco M.D., Das S.K. Energy-efficient randomized switching for maximizing lifetime in tree-based wireless sensor networks. IEEE ACM Trans. Netw. 2015;23:1401–1415. doi: 10.1109/TNET.2014.2331178. [DOI] [Google Scholar]
- 25.Xiang M., Wang P., Luo Z. Node classification method based on integrative support degree in WSN. Comput. Eng. 2010;36:97–99. [Google Scholar]
- 26.George T., Trevor C. Simulation tools for multilayer fault restoration. IEEE Commun. Mag. 2009;47:128–134. [Google Scholar]
- 27.Dong M., Ota K., Liu A. RMER: Reliable and Energy-Efficient Data Collection for Large-Scale Wireless Sensor Networks. IEEE Internet Things J. 2016;3:511–519. doi: 10.1109/JIOT.2016.2517405. [DOI] [Google Scholar]