
Figure 4. Temporally sequenced cholinergic and dopaminergic modulation of STDP yields effective navigation toward changing reward locations.
(a) Learning of an initial reward location (trials 1–20; 1000 simulations in each trial) shows a modest improvement in learning when cholinergic depression is included in the model. (i) Example trajectories. The agent starts from the center of the open field (red dot) and learns the reward location (closed black circle) with (+ ACh; brown) and without (− ACh; green) cholinergic depression built into the model. Trials are coded from light to dark, according to their temporal order (early = light, late = dark). (ii) Color scheme. (iii) Reward discovery. The graph shows percent cumulative distribution of trials in which the reward location is discovered for the first time. (iv) Learning curve presented as a percentage of successful simulations over successive trials. (v) Average time to reward in each successful trial. Unsuccessful trials, in which the agent failed to find the reward, were excluded. (vi) Percentage of successful simulations in trial 5, under conditions with different magnitudes of dopaminergic effect (learning windows in the top-left corner). Decreasing the magnitude of dopaminergic potentiation significantly affects learning (p<0.001, two-sample Student’s t-test: Small vs. Medium and Small vs. Large). Under Medium and Large conditions, the agent performs similarly most likely due to a saturation effect (p>0.05, two-sample Student’s t-test: Medium vs. Large). (b) Learning of a displaced reward location is facilitated when cholinergic depression is included in the model. (i) Example trajectories (trials 21–40; 1000 simulations in each trial). The agent learns a novel reward location (closed circle; previously exploited reward = open circle). Trajectories presented as in ai. Comparison of control (– ACh) and test (+ ACh) simulations: (ii) visits to previous reward location (%); (iii) trial number at novel reward discovery; (iv) successful reward collection over successive trials (%); (v) average time to reward over trials. (vi) Percentage of visits to the old reward location in trial 25, under conditions with different magnitudes of cholinergic depression (learning windows in the top-right corner). Increasing the magnitude of acetylcholine effect yields faster unlearning (p<0.001, two-sample Student’s t-test: Small vs. Medium, Medium vs. Large and Small vs. Large). The graphs (biii-bv) are presented as in a. The shaded area (aiv-v and bii, biv-v) represents the 95% confidence interval of the sample mean.

Figure 4—figure supplement 1. Exploration following reward displacement.
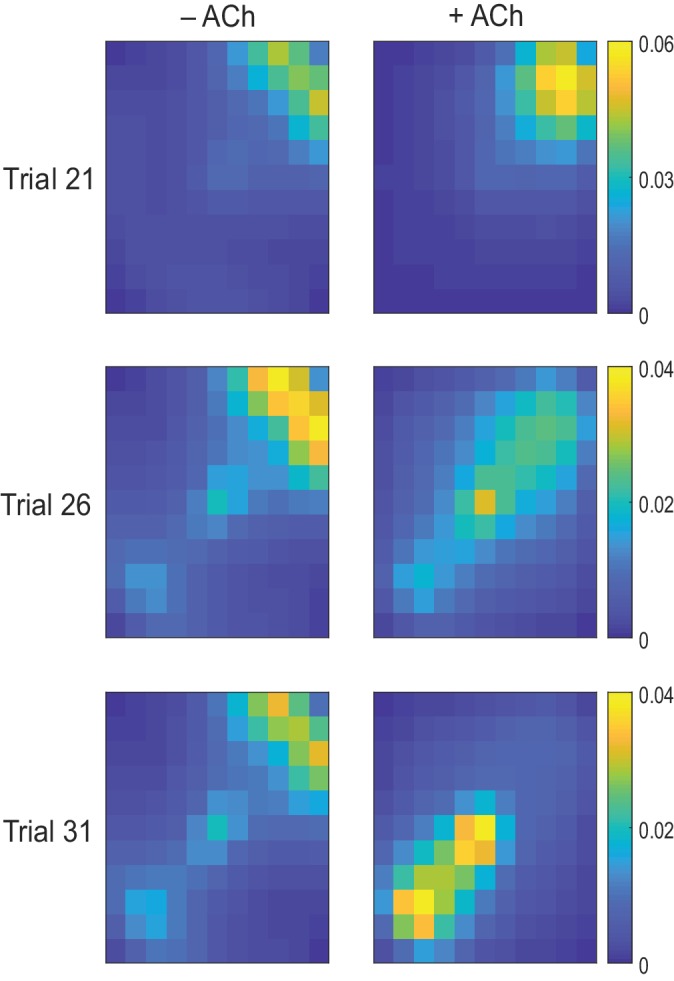
Figure 4—figure supplement 2. The magnitude of dopamine effect affects learning.

Figure 4—figure supplement 3. The magnitude of acetylcholine effect affects unlearning.

Figure 4—figure supplement 4. The integral of the asymmetric STDP learning window determines the performance of the agent.
