
Figure 4.
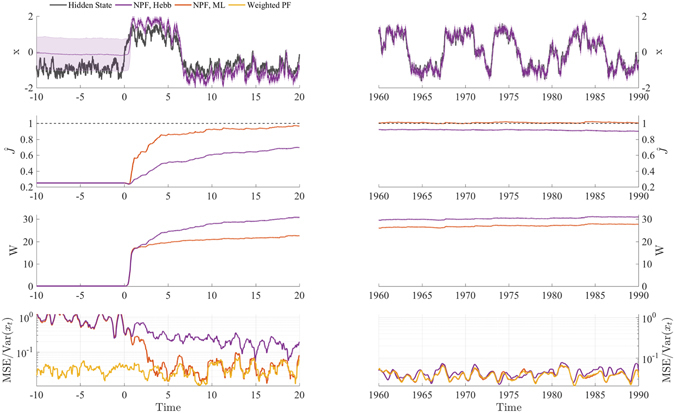
Model parameters are learned by a stochastic gradient ascent on the log likelihood. Simulations shown here correspond to the example model with only a visual cue, i.e. a generative model with Eqs (13) and (15). The generative weight J is learned online either by maximum likelihood (ML, Eq. 10) or the Hebbian learning rule (Hebb) in Eq. (11), which is a valid approximation for small sensory noise. The sensory gain W t is learned online simultaneously, using Eq. (12). As benchmark, we use a weighted PF with the true model parameters. For both parameters W t and J, learning starts at t = 0. As approaches the true value J = 1, the trajectory of the filtering neurons (purple) is able to follow that of the true hidden state (black), and the MSE of the NPF resembles that of the standard PF.