
Fig. 4.
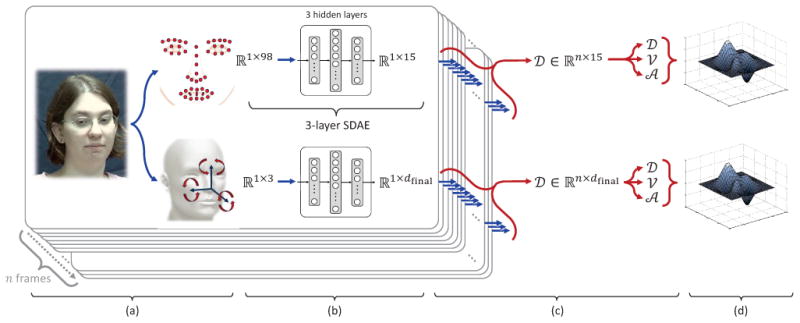
Overview of the proposed approach: (a) Tracking of facial landmarks and head pose, (b) per-frame encoding through Stacked Denoising Autoencoders, (c) extraction of per-frame dynamics (amplitude, velocity, and acceleration), and (d) per-video encoding through Improved Fisher Vector coding or Compact Dynamic Feature Set.