
Fig. 1.
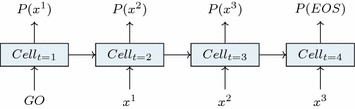
Learning the data. Depiction of maximum likelihood training of an RNN. are the target sequence tokens we are trying to learn by maximizing for each step
Official websites use .gov
A
.gov website belongs to an official
government organization in the United States.
Secure .gov websites use HTTPS
A lock (
) or https:// means you've safely
connected to the .gov website. Share sensitive
information only on official, secure websites.
Learning the data. Depiction of maximum likelihood training of an RNN. are the target sequence tokens we are trying to learn by maximizing for each step