

Abstract
Scientists routinely compare gene expression levels in cases versus controls in part to determine genes associated with a disease. Similarly, detecting case-control differences in co-expression among genes can be critical to understanding complex human diseases; however statistical methods have been limited by the high dimensional nature of this problem. In this paper, we construct a sparse-Leading-Eigenvalue-Driven (sLED) test for comparing two high-dimensional covariance matrices. By focusing on the spectrum of the differential matrix, sLED provides a novel perspective that accommodates what we assume to be common, namely sparse and weak signals in gene expression data, and it is closely related with Sparse Principal Component Analysis. We prove that sLED achieves full power asymptotically under mild assumptions, and simulation studies verify that it outperforms other existing procedures under many biologically plausible scenarios. Applying sLED to the largest gene-expression dataset obtained from post-mortem brain tissue from Schizophrenia patients and controls, we provide a novel list of genes implicated in Schizophrenia and reveal intriguing patterns in gene co-expression change for Schizophrenia subjects. We also illustrate that sLED can be generalized to compare other gene-gene “relationship” matrices that are of practical interest, such as the weighted adjacency matrices.
Keywords and phrases: Permutation test, high-dimensional data, covariance matrix, sparse principal component analysis
1. Introduction
High throughput technologies provide the capacity for measuring potentially interesting genetic features on the scale of tens of thousands. With the goal of understanding various complex human diseases, a widely used technique is gene differential expression analysis, which focuses on the marginal effect of each variant. Converging evidence has also revealed the importance of co-expression among genes, but analytical techniques are still underdeveloped. Improved methods in this domain will enhance our understanding of how complex disease affects the patterns of gene expression, shedding light on both the development of disease and its pathological consequences.
Schizophrenia (SCZ), a severe mental disorder with 0.7% lifetime risk (McGrath et al., 2008), is one of the complex human traits that has been known for decades to be highly heritable but whose genetic etiology and pathological consequences remain unclear. What has been repeatedly confirmed is that a large proportion of SCZ liability traces to polygenetic variation involving many hundreds of genes together, with each variant exerting a small impact (Purcell et al., 2014; International Schizophrenia Consortium et al., 2009). Despite the large expected number, only a small fraction of risk loci have been conclusively identified (Schizophrenia Working Group of the Psychiatric Genomics Consortium, 2014). This failure is due mainly to the limited signal strength of individual variants and under-powered mean-based association studies. Still, several biological processes, including synaptic mechanisms and glutamatergic neurotransmission, have been reported to be implicated in the risk for SCZ (Fromer et al., 2016). The observation that each genetic variant contributes only moderately to risk, and that each affected individual carries many risk variants, suggests that SCZ develops as a consequence of subtle alterations of both gene expression and co-expression, which requires development of statistical methods to describe the subtle, wide-spread co-expression differences.
Pioneering efforts have started in this direction. Very recently, the CommonMind Consortium (CMC) completed a large-scale RNA sequencing on dorsolateral prefrontal cortex from 279 control and 258 SCZ subjects, forming the largest brain gene expression data set on SCZ (Fromer et al., 2016). Analyses of these data by the CommonMind Consortium suggest that many genes show altered expression between case and control subjects, although the mean differences are small. By combining gene expression and co-expression patterns with results from genetic association studies, it appears that genetic association signals tend to cluster in certain sets of tightly co-expressed genes, so called co-expression modules (Zhang and Horvath, 2005). Still, the study of how gene co-expression patterns change from controls to SCZ subjects remains incomplete. Here, we address this problem using a hypothesis test that compares the gene-gene covariance matrices between control and SCZ samples, with integrated variable selection.
The problem of two-sample test for covariance matrices has been thoroughly studied in traditional multivariate analysis (Anderson et al., 1958), but becomes nontrivial once we enter the high-dimensional regime. Most of the previous high-dimensional covariance testing methods are motivated by either the L∞-type distance between matrices where all entries are considered (Schott, 2007; Li and Chen, 2012), or the L∞-type distance where only the largest deviation is utilized (Cai, Liu and Xia, 2013; Chang et al., 2016). These two strategies are designed for two extreme situations, respectively: when almost all genes exhibit some difference in co-expression patterns, or when there is one “leading” pair of genes whose co-expression pattern has an extraordinary deviation in two populations. However, the mechanism of SCZ is most likely to lie somewhere in between, where the difference may occur among hundreds of genes (compared to a total of ≈ 20,000 human genes), yet each deviation remains small. Some other existing approaches include using the trace of the covariance matrices (Srivastava and Yanagihara, 2010), using random matrix projections (Wu and Li, 2015), and using energy statistics to measure the distance between two populations (Székely and Rizzo, 2013). But none of these methods is designed for the scenario in which the signals are both sparse and weak.
In this paper, we propose a sparse-Leading-Eigenvalue-Driven (sLED) test. It provides a novel perspective for matrix comparisons by evaluating the spectrum of the differential matrix, defined as the difference between two covariance matrices. This provides greater power and insight for many biologically plausible models, including the situation where only a small cluster of genes has abnormalities in SCZ subjects, so that the differential matrix is supported on a small sub-block. The test statistic of sLED links naturally to the fruitful results in Sparse Principal Component Analysis (SPCA), which is widely used for unsupervised dimension reduction in the high-dimensional regime. Both theoretical and simulation results verify that sLED has superior power under sparse and weak signals. In addition, sLED can be generalized to compare other gene-gene “relationship” matrices, including the weighted adjacency matrices that are commonly used in gene clustering studies (Zhang and Horvath, 2005). Applying sLED to the CMC data sheds light on novel SCZ risk genes, and reveals intriguing patterns that are previously missed by the mean-based differential expression analysis.
For the rest of this paper, we motivate and propose sLED for testing two-sample covariance matrices in Section 2. We provide two algorithms to compute the test statistic, and establish theoretical guarantees on the asymptotic consistency. In Section 3, we conduct simulation studies and show that sLED has superior power to other existing two-sample covariance tests under many scenarios. In Section 4, we apply sLED to the CMC data. We detect a list of genes implicated in SCZ and reveal interesting patterns of gene co-expression changes. We also illustrate that sLED can be generalized to comparing weighted adjacency matrices. Section 5 concludes the paper and discusses the potential of applying sLED to other datasets. All proofs are included in the Supplement. An implementation of sLED is provided at https://github.com/lingxuez/sLED.
2. Methods
2.1. Background
Suppose and are independent p-dimensional random variables coming from two populations with potentially different covariance structures. Without loss of generality, both expectations are assumed to be zero, and let D = Σ2−Σ1 be the differential matrix. The goal is to test
| (2.1) |
This two-sample covariance testing problem has been well studied in the traditional “large n, small p” setting, where the likelihood ratio test (LRT) is commonly used. However, testing covariance matrices under the high-dimensional regime is a nontrivial problem. In particular, LRT is no longer well defined when p > min{n, m}. Even if p ≤ min {n, m}, LRT has been shown to perform poorly when p/min{n, m} → c ∈ (0, 1) Bai et al., 2009).
Researchers have approached this problem in different ways. Here, we review two of the main strategies to motivate our test. The first one starts from rewriting (2.1) as
| (2.2) |
where ‖D‖F is the Frobenius norm of D. This strategy includes a test statistic based on an estimator of under normality assumptions (Schott, 2007), as well as a test under more general settings using a linear combination of three U-statistics, which is also motivated by (Li and Chen, 2012). These L2-based tests target a dense alternative, but usually suffer from loss of power when D has only a small number of non-zero entries.
On the other hand, Cai, Liu and Xia (2013) consider the sparse alternative, and rewrite (2.1) as
| (2.3) |
where ‖D‖∞ = maxi,j |Dij|. Then the test statistic is constructed using a normalized estimator of ‖D‖∞. Later, Chang et al. (2016) proposed a bootstrap procedure using the same test statistic but under weaker assumptions, and Cai and Zhang (2015) extended the idea to comparing two-sample correlation matrices. These L∞-norm based tests have been shown to enjoy superior power when the single-entry signal is strong, in the sense that maxi,j |Dij| is of order or larger.
In this paper, we focus on the unexplored but practically interesting regime where the signal is both sparse and weak, meaning that the difference may occur at only a small set of entries, while the magnitude tends to be small. We propose another perspective to construct the test statistic by looking at the singular value of D, which is especially suitable for this purpose. To illustrate the idea, consider a toy example where
| (2.4) |
for some ρ > 0 and integer s ≪ p. In other words, Σ2 and Σ1 differ by ρ in only an s × s sub-block. In this case, the L2-type tests are sub-optimal because they include errors from all entries; so are the L∞-type tests because they utilize only one single entry ρ. On the other hand, the largest singular value of D is sρ, which extracts stronger signals with much less noise and therefore has the potential to gain more power.
More formally, we rewrite the testing problem (2.1) to be
| (2.5) |
where σ1(·) denotes the largest singular value. Compared to (2.2) and (2.3), (2.5) provides a novel perspective to study the two-sample covariance testing problem based on the spectrum of the differential matrix D, and will be the starting point of constructing our test statistic.
Notation
For a vector , let be the Lq norm for q > 0, and ‖v‖0 be the number of non-zero elements. For a symmetric matrix , let Aij be the (i, j)-th element, ‖A‖q be the Lq norm of vectorized A, and tr(A) be the trace. In addition, we use λ1(A) ≥ ⋯ ≥ λp(A) to denote the eigenvalues of A. For two symmetric matrices , we write A⪰B when A−B real is positive semidefinite. Finally, for two sequences of numbers {xn} and {yn}, we write xn = O(yn) if |xn/yn| ≤ C for all n and some positive constant C, and xn = o(yn) if limn xn/yn = 0.
2.2. A two-sample covariance test: sLED
Starting from (2.5), note that
Therefore, a naive test statistic would be for some estimator . A simple estimator is the difference between the sample covariance matrices:
| (2.6) |
However, in the high-dimensional setting, is not necessarily a consistent estimator of λ1(D), and without extra assumptions, there is almost no hope of reliable recovery of the eigenvectors (Johnstone and Lu, 2009). A popular remedy for this curse of dimensionality in many high-dimensional methods is to add sparsity assumptions, such as imposing an L0 constraint on an optimization procedure. Note that for any symmetric matrix ,
Following the common strategy, we consider the constrained problem:
| (2.7) |
where R > 0 is some constant that controls the sparsity of the solution, and is usually referred to as the R-sparse leading eigenvalue of A. Then, naturally, we construct the following test statistic
| (2.8) |
and the sparse-Leading-Eigenvalue-Driven (sLED) test is obtained by thresholding TR at the proper level.
Problem (2.7) is closely related with Sparse Principal Component Analysis (SPCA). The only difference is that in SPCA, the input matrix A is usually the sample covariance matrix, but here, we use the differential matrix . Solving (2.7) directly is computationally intractable, but we will show in Section 2.3 that approximate solutions can be obtained.
Finally, because it is difficult to obtain the limiting distribution of TR, we use a permutation procedure. Specifically, for any α ∈ (0, 1), the α−level sLED test, denoted by , is conducted as follows:
Given samples Z = (X1, ⋯, Xn, Y1,·⋯, Ym), calculate the test statistic TR as in (2.8).
- Sample uniformly from Z without replacement to get , where N = n + m. Calculate the permutation differential matrix :
where , . That is, randomly permute the indices {1, ⋯, N}, treat the first n indices as from the first population and the·last m indices as from the second population.(2.9) - Compute the permutation test statistic
(2.10) - Repeat steps 2 – 3 for B times to get , then
and sLED rejects H0 if , i.e., .
Remark 1
We can also estimate the support of the R-sparse leading eigenvector of D, which provides a list of genes that are potentially involved in the disease. Without loss of generality, suppose , we define
| (2.11) |
where is the R-sparse leading eigenvector of in (2.7). Then the elements with large leverage will be the candidate genes that have altered covariance structure between the two populations.
2.3. Sparse principal component analysis
Many studies on Sparse Principal Component Analysis (SPCA) have provided various algorithms to approximate (2.7) when A is the sample covariance matrix. Most techniques utilize an L1 constraint to achieve both sparsity and computational efficiency. To name a few, Jolliffe, Trendafilov and Uddin (2003) form the SCoT-LASS problem by directly replacing the L0 constraint by L1 constraint; Zou, Hastie and Tibshirani (2006) analyze the problem from a penalized regression perspective; Witten, Tibshirani and Hastie (2009) and Shen and Huang (2008) use the framework of low rank matrix completion and approximation; d’Aspremont et al. (2007) and Vu et al. (2013) consider the convex relaxation of (2.7). Recent development of atomic norms also provides an alternative approach to deal with the L0 constrained problems (for example, see Oymak et al. (2015)). For the purpose of this paper, we give details of only the following two SPCA algorithms that can be directly generalized to approximate (2.7) with input matrix , the differential matrix.
Fantope projection and selection (FPS)
For a symmetric matrix , FPS (Vu et al., 2013) considers a convex optimization problem:
| (2.12) |
where ℱ1 = {H ∈ ℝp×p: symmetric, 0 ⪯ H ⪯ I, tr(H) = 1} is the 1-dimensional Fantope, which is the convex hull of all 1-dimensional projection matrices {vvT: ‖v‖2 = 1}. In addition, by the Cauchy-Schwarz inequality, if ‖v‖2=1, then ‖vvT‖1 ≤ ‖v‖0 Therefore, (2.12) is a convex (relaxation) of (2.7). Moreover, when the input matrix is , the problem is still convex, and the ADMM algorithm proposed in Vu et al. (2013) can be directly applied. This algorithm has guaranteed convergence, but requires iteratively performing SVD on a p×p matrix. Moreover, the calculation needs to be repeated B times in the permutation procedure, and becomes computationally demanding when p is on the order of a few thousands. Therefore, we present an alternative heuristic algorithm below, which is much more efficient and typically works well in practice.
Penalized matrix decomposition (PMD)
For a general matrix , PMD (Witten, Tibshirani and Hastie, 2009) solves a rank-one matrix completion problem:
| (2.13) |
The solution for each one of u and v has a simple closed form after fixing the other one. This leads to a straightforward iterative algorithm, which has been implemented in the R package PMA. Moreover, if the solutions satisfy , then they are also the solutions to the following non-convex Constrained-PMD problem:
| (2.14) |
Note that the solutions of (2.14) always have ‖v‖2=1 which implies ,so (2.14) is also an approximation to (2.7). Now observe that when A ⪰ 0, as in the usual SPCA setting, the solutions of (2.13) automatically have by the Cauchy-Schwarz inequality. However, this is no longer true when A is not positive semidefinite, as when we deal with the differential matrix . To overcome this issue, we choose some constant d > 0 that is large enough such that A + dI ⪰ 0. Then the solutions of will satisfy , and it is easy to obtain by
| (2.15) |
2.4. Consistency
Finally, we show that sLED is asymptotically consistent. The validity of its size is guaranteed by the permutation procedure. Here, we prove that sLED also achieves full power asymptotically, under the following assumptions:
-
(A1)
(Balanced sample sizes) for some constants .
-
(A2)(Sub-gaussian tail) Let (Z1, ⋯, ZN) = (X1, ⋯, Xn, Y1, ⋯, Ym), then every Zk is sub-gaussian with parameter ν2, that is,
-
(A3)
(Dimensionality) (log p)3 = O(n).
-
(A4)(Signal strength) Under H1, for some constant C to be specified later,
Theorem 1 (Power of sLED)
Let TR be the test statistic as defined in (2.8), and be the permutation test statistic as defined in (2.10), where is approximated by the L1 constrained algorithms (2.12) or (2.14). Then under assumptions (A1)–(A3), for ∀δ > 0, there exists a constant C depending on , such that if assumption (A4) holds, and n, p are sufficiently large,
As a consequence, for any pre-specified level α ∈ (0, 1), pick δ = α/2, then
The proof of Theorem 1 contains two steps. First, Theorem 2 provides an upper bound of the entries in . Then Theorem 3 ensures that the permutation test statistic is controlled by , and the test statistic TR is lower-bounded in terms of the signal strength. We state Theorem 2 and Theorem 3 below, and the proof details are included in the Supplement.
Theorem 2 (Permutation differential matrix)
Under assumptions (A1)–(A3), let be the permutation differential matrix as defined in (2.9), then ∀δ > 0, there exist constants C, C1 depending on , such that if n, p are sufficiently large,
Theorem 3 (Test statistic)
For any symmetric matrix , let be a solution of the L1 constrained algorithms (2.12) or (2.14), then the following statements hold:
If for some ε > 0, then .
- If there is a matrix D such that for some ε > 0, then
Remark 2
Assumption (A4) does not require the leading eigenvector of D (or −D) to be sparse, only that the sparse signal be strong enough, which is a very mild requirement.
Remark 3
Theorems 1–3 suggest that sLED is as powerful as the maximum entry test by Cai, Liu and Xia (2013). Consider the toy example in (2.4) and L1 radius R = s. Assumption (A4) for the L1 constrained problem implies that sLED is powerful if , which is the same rate required for the maximal entry test. When the signal strength ρ is below the rate of , the maximal entry test has no power. A related result in sparse PCA due to Berthet and Rigollet (2013) implies that sLED is unlikely to be powerful in this case either.
2.5. Choosing sparsity parameter R
The tuning parameter R in (2.12) and (2.14) plays an important role in sLED test. If R is too large, the method uses little regularization and assumption (A4) is unlikely to hold. If R is too small, then the constraint is too strong to cover the signal in the differential matrix. The practical success of sLED requires an appropriate choice of R. We know that R provides a natural, but possibly loose, lower bound on the support size of the estimated sparse eigenvector. In general, one can use cross-validation to choose R, so that the estimated leading sparse singular vector maximizes its inner product with a differential matrix computed from a testing subsample.
In applications, one can often choose R with the aid of subject background knowledge and the context of subsequent analysis. For example, in the detection of Schizophrenia risk genes, we typically expect to report a certain proportion in a collection of genes for further investigation. Thus one can choose from a set of candidate values of R to match the desired number of discoveries. In this paper, following Witten, Tibshirani and Hastie (2009), we use algorithm (2.14) and choose the sparsity parameter R to be
| (2.16) |
then c2 provides a loose lower bound on the proportion of selected genes. We will illustrate in simulation studies (Section 3) and the CMC data application (Section 4) that sLED is stable with a reasonable range of c.
3. Simulations
In this section, we conduct simulation studies to compare the power of sLED with other existing methods: Schott (2007) use an estimator of the Frobenius norm (Sfrob); Li and Chen (2012) use a linear combination of three U-statistics which is also motivated by (Ustat); Cai, Liu and Xia (2013) use the maximal absolute entry of D (Max); Chang et al. (2016) use a multiplier bootstrap on the same test statistic (MBoot), and Wu and Li (2015) use random matrix projections (RProj). To obtain a fair comparison of empirical power, we use permutation to compute the p-values for all methods, except for MBoot, which already uses a bootstrap procedure. Here, we focus on comparing the empirical power in the rest of this section. The empirical sizes are reported in the supplement. The simulation results in this section can be reproduced using the code provided at https://github.com/lingxuez/sLED.
We consider four different covariance structures of Σ1 and Σ2 = Σ1 + D under the alternative hypothesis. Under each scenario i = 1, ⋯, 4, we first generate a base matrix Σ∗(i), and we enforce positive definiteness using Σ1 = Σ∗(i)+δIp and Σ1 = Σ∗(i)+D+δIp, where δ = |min{λmin(Σ∗(i)), λmin(Σ∗(i) + D)}| + 0.05. Now we specify the structures of {Σ∗(i)}i=1,…,4. Under each scenario, we let to be a diagonal matrix with diagonal elements being sampled from Unif(0.5, 2.5) independently. We denote ⌊x⌋ to be the largest integer that is smaller than or equal to x.
Noisy diagonal. Let , when i < j, and when i > j for symmetry, and we define Σ∗(1) = Λ1/2Δ(1)Λ1/2. This model is also considered in Cai, Liu and Xia (2013).
Block diagonal. Let K = ⌊p/10⌋ be the number of blocks, , when 10(k − 1) + 1 ≤ i ≠ j ≤ 10k for k 1, ⋯, K, and zero otherwise. We define Σ∗(2) = Λ1/2Δ(2)Λ1/2. This model is also considered in Cai, Liu and Xia (2013) and Chang et al. (2016).
Exponential decay. Let , and Σ∗(3) = Λ1/2Δ(3)Λ1/2. This model is also considered in Cai, Liu and Xia (2013) and Chang et al. (2016).
WGCNA. Finally, Σ∗(4) is computed based on the CMC data (Fromer et al., 2016) using the simulation tool provided by WGCNA (Zhang and Horvath, 2005). Specifically, we first compute the eigengene (i.e., the first principal component) of the M2c module for the 279 control samples. The M2c module will be the focus of Section 4, and more detailed discussion is provided there. We use the simulateDatExpr command in the WGCNA R package to simulate new expressions for p genes of the 279 samples. We set modProportions=(.8,.2), such that 80% of the p genes are simulated to be correlated with the M2c eigengene, and the other 20% genes are randomly generated. Default values are used for all other parameters. Finally, Σ∗(4) is set to be the sample covariance matrix.
We consider the following two types of differential matrix D:
Sparse block difference. Suppose D is supported on an s × s sub-block with s = ⌊0.1p⌋, and the non-zero entries are generated from Unif(d/2, 2d) independently. The signal level d is chosen to be where Σ∗ is the base matrix defined above.
Soft-sparse spiked difference. Let D be a rank-one matrix with D = dvvT, where v is a soft-sparse unit vector with ‖v‖2=1 and ║v║0 = ⌊0.2p⌋. The support of v is uniformly sampled from {1, ⋯, p} without replacement. Among the non-zero elements, ⌊0.1p⌋ are·sampled from N(1, 0.01), and the remaining ⌊0.2p⌋−⌊0.1p⌋ are sampled from N(0.1, 0.01). Finally, v is normalized to have unit L2 norm. The signal level d is set to be , where Σ∗ is the base matrix defined above. The differential matrix D under this scenario is moderately sparse, with ⌊0.1p⌋ features exerting larger signals.
Finally, the samples are generated by for i = 1, ⋯, n, and for l = 1, ⋯, m, where {Zi}i=1,n+m are independent p-dimensional random variables with i.i.d. coordinates Zij, j = 1, ⋯, p. We consider the following four distributions for Zij:
Standard Normal N(0, 1).
Centralized Gamma distribution with α = 4, β = 0.5 (i.e., the theoretical expectation αβ = 2 is subtracted from Γ(4, 0.5) samples). This distribution is also considered in Li and Chen (2012) and Cai, Liu and Xia (2013).
t-distribution with degrees of freedom 12. This distribution is also considered in Cai, Liu and Xia (2013) and Chang et al. (2016).
Centralized Negative Binomial distribution with mean μ = 2 and dispersion parameter ϕ = 2 (i.e., the theoretical expectation μ = 2 is subtracted from NB(2, 2) samples).
Note that when Zij ~ N(0, 1), X and Y are multinomial Gaussian random variables with covariance matrices Σ1 and Σ2. We also consider three non-Gaussian distributions to account for the heavy-tail scenario observed in many genetic data sets.
Here, the smoothing parameter for sLED is set to be , and 100 random projections are used for Rproj. For sLED, Max, Ustat, Sfrob, and Rproj, 100 permutations are used to obtain each p-value; for MBoot, 100 bootstrap repetitions are used. Table 1 summarizes the empirical power under different covariance structures and differential matrices when Zij’s are sampled from standard Normal and centralized Gamma distribution. We see that sLED is more powerful than many existing methods under most scenarios. The results using the other two distributions of Z have similar patterns, and due to space limitation we include them in the Supplement.
Table 1.
Empirical power in 100 repetitions, where n = m = 100, nominal level α = 0.05, and Zij’s are sampled from standard normal (top) and centralized Gamma (4, 0.5) (bottom). Under each scenario, the largest power is highlighted.
| D | Σ1 | Noisy diagonal | Block diagonal | Exp. decay | WGCNA | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
|||||||||||||
| p | 100 | 200 | 500 | 100 | 200 | 500 | 100 | 200 | 500 | 100 | 200 | 500 | |
| Gaussian | |||||||||||||
| Block | Max | 0.38 | 0.14 | 0.11 | 0.94 | 0.54 | 0.25 | 0.98 | 0.86 | 0.31 | 0.92 | 0.64 | 0.16 |
| MBoot | 0.39 | 0.18 | 0.13 | 0.94 | 0.54 | 0.31 | 0.98 | 0.88 | 0.30 | 0.89 | 0.63 | 0.20 | |
| Ustat | 0.71 | 0.66 | 0.74 | 0.98 | 0.96 | 0.95 | 1.00 | 1.00 | 0.99 | 0.76 | 0.78 | 0.85 | |
| Sfrob | 0.72 | 0.64 | 0.73 | 0.97 | 0.95 | 0.95 | 1.00 | 1.00 | 0.99 | 0.72 | 0.79 | 0.86 | |
| RProj | 0.09 | 0.13 | 0.09 | 0.13 | 0.16 | 0.14 | 0.24 | 0.16 | 0.09 | 0.20 | 0.17 | 0.06 | |
| sLED | 1.00 | 0.99 | 1.00 | 1.00 | 0.99 | 1.00 | 1.00 | 1.00 | 1.00 | 0.98 | 0.96 | 0.95 | |
|
| |||||||||||||
| Spiked | Max | 0.12 | 0.08 | 0.05 | 0.49 | 0.26 | 0.09 | 0.96 | 0.90 | 0.15 | 0.86 | 0.32 | 0.04 |
| MBoot | 0.12 | 0.08 | 0.05 | 0.51 | 0.29 | 0.11 | 0.98 | 0.90 | 0.17 | 0.79 | 0.31 | 0.07 | |
| Ustat | 0.20 | 0.11 | 0.13 | 0.76 | 0.44 | 0.06 | 1.00 | 0.95 | 0.60 | 0.30 | 0.10 | 0.04 | |
| Sfrob | 0.18 | 0.12 | 0.11 | 0.73 | 0.41 | 0.07 | 1.00 | 0.93 | 0.62 | 0.34 | 0.14 | 0.03 | |
| RProj | 0.10 | 0.08 | 0.02 | 0.32 | 0.08 | 0.12 | 0.30 | 0.20 | 0.09 | 0.61 | 0.24 | 0.13 | |
| sLED | 0.51 | 0.11 | 0.03 | 0.97 | 0.701 | 0.12 | 1.00 | 1.00 | 1.00 | 0.97 | 0.57 | 0.05 | |
|
| |||||||||||||
| Centralized Gamma | |||||||||||||
| Block | Max | 0.42 | 0.20 | 0.14 | 0.89 | 0.71 | 0.28 | 0.96 | 0.82 | 0.42 | 0.77 | 0.67 | 0.27 |
| MBoot | 0.42 | 0.14 | 0.10 | 0.86 | 0.58 | 0.20 | 0.95 | 0.77 | 0.33 | 0.72 | 0.63 | 0.25 | |
| Ustat | 0.57 | 0.59 | 0.70 | 0.92 | 0.94 | 0.97 | 0.99 | 0.98 | 0.98 | 0.53 | 0.82 | 0.86 | |
| Sfrob | 0.58 | 0.55 | 0.71 | 0.92 | 0.92 | 0.98 | 0.99 | 0.99 | 0.98 | 0.50 | 0.76 | 0.81 | |
| RProj | 0.11 | 0.10 | 0.09 | 0.24 | 0.17 | 0.16 | 0.41 | 0.15 | 0.14 | 0.21 | 0.07 | 0.14 | |
| sLED | 0.96 | 0.98 | 0.99 | 0.99 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 0.94 | 0.88 | 0.94 | |
|
| |||||||||||||
| Spiked | Max | 0.08 | 0.09 | 0.03 | 0.72 | 0.39 | 0.05 | 0.99 | 0.71 | 0.22 | 0.91 | 0.35 | 0.04 |
| MBoot | 0.10 | 0.07 | 0.02 | 0.74 | 0.36 | 0.09 | 0.99 | 0.71 | 0.16 | 0.88 | 0.35 | 0.04 | |
| Ustat | 0.32 | 0.08 | 0.11 | 0.78 | 0.41 | 0.07 | 1.00 | 0.94 | 0.70 | 0.33 | 0.08 | 0.05 | |
| Sfrob | 0.34 | 0.07 | 0.10 | 0.80 | 0.37 | 0.07 | 1.00 | 0.96 | 0.74 | 0.28 | 0.04 | 0.04 | |
| RProj | 0.12 | 0.06 | 0.07 | 0.32 | 0.12 | 0.06 | 0.36 | 0.14 | 0.10 | 0.63 | 0.22 | 0.10 | |
| sLED | 0.56 | 0.14 | 0.05 | 0.97 | 0.71 | 0.14 | 1.00 | 1.00 | 1.00 | 0.93 | 0.51 | 0.08 | |
Finally, we examine the sensitivity of sLED to the smoothing parameter. Recall that the smoothing parameter is set to be as explained in Section 2.5. Figure 1 visualizes the empirical power of sLED using c ∈ {0.10, 0.12, ⋯, 0.30} when D has sparse block difference and Zij’s are sampled from N(0, 1). It is clear that sLED remains powerful for a wide range of c. Similar patterns are observed under other scenarios, and we include these results in the Supplement.
Fig. 1.
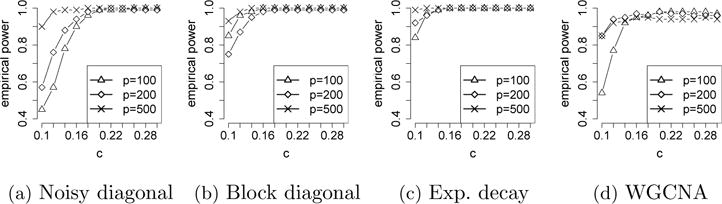
Empirical power of sLED in 100 repetitions using different smoothing parameters for c ∈ {0.10, ⋯, 0.30}, where D has sparse block difference and Zij’s are from sampled N(0, 1).
4. Application to Schizophrenia data
In this section, we apply sLED to the CommonMind Consortium (CMC) data, containing RNA-sequencing on 16,423 genes from 258 Schizophrenia (SCZ) subjects and 279 control samples (Fromer et al., 2016). The RNA-seq data has been carefully processed, including log-transformation and adjustment of various covariates using a weighted linear regression. The CMC group further cluster the genes into 35 genetic modules using the WGCNA tool (Zhang and Horvath, 2005), such that genes within each module tend to be closely connected and have related biological functionalities. Among these, the M2c module, containing 1,411 genes, is the only one that is enriched with genes exhibiting differential expression and with prior genetic associations with schizophrenia (SCZ). We direct readers to the original paper (Fromer et al., 2016) for more detailed description of the data processing and genetic module analysis. In the rest of this section, we apply sLED to investigate the co-expression differences between cases and controls in the M2c module, which is of the greatest scientific interest. We center and standardize the expression data, such that each gene has mean 0 and standard deviation 1 across samples. Therefore, the covariance test is applied to correlation matrices.
4.1. Testing co-expression differences
In this section, we use sLED to compare the correlation matrices among the 1,411 M2c-module genes between SCZ and control samples. The sparsity parameter in (2.14) is chosen to be , and as explained in Section 2.5, c2 provides a loose lower bound on the proportion of selected genes. Here, because the number of risk genes that carry the genetic signals is expected to be roughly in the range of 1%–10%, we choose c = 0.1. Applying sLED with 1,000 permutation repetitions, we obtain a p-value of 0.014, indicating a significant difference between SCZ and control samples.
We then identify the key genes that drive this difference according to their leverage, as defined in (2.11). Specifically, we order the leverage of all genes, such that , where larger leverage usually indicates stronger signals. Note that by construction, . Among the 1,411 genes, 113 genes have non-zero leverage, and we call them top genes. Moreover, we notice that the first 25 genes have already achieved a cumulative leverage of 0.999, so we refer to them as primary genes. The remaining 88 top genes account for the remaining 0.001 leverage and are referred to as secondary genes (see Figure 2a for the visualization of this cut-off in a scree plot). We show in Figure 2b how these 113 top genes form a clear block structure in the differential matrix . Notably, such a block structure cannot be revealed if ordered by the differentially expressed p-values (Figure 2c).
Fig. 2.
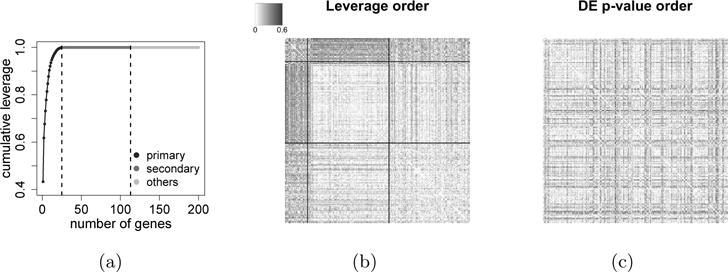
Visualization of 200 genes in the M2c module, including 25 primary genes that account for a total leverage of 0.999, 88 secondary genes that account for the remaining 0.001 leverage, and 87 randomly selected other genes that have zero leverage. (a) Scree plot of cumulative leverage. (b) Heatmap of where genes are ordered by leverage and a block structure is revealed. The two partitioning lines indicate the 25 primary genes and the 88 secondary genes. (c) Heatmap of where genes are ordered by p-values in differential expression analysis. Now the block structure is diluted.
Figure 2b reveals a significant decrease of gene co-expression (interactions) in cortical samples from SCZ subjects between the 25 primary genes and the 88 secondary genes. This pattern is more clearly illustrated in Figure 3, where two gene networks are constructed for these 113 top genes in control samples and SCZ samples separately (see Table 2 for gene names).
Fig. 3.
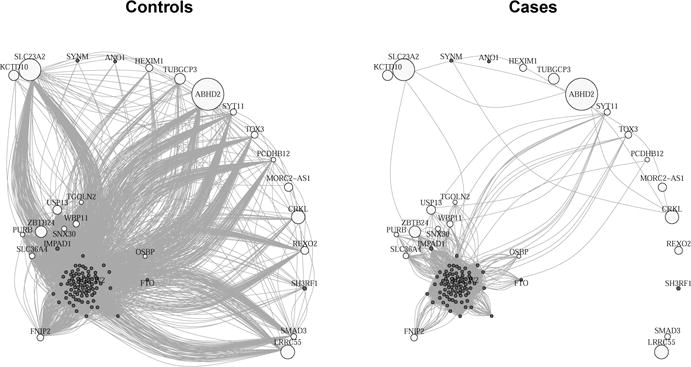
Gene networks constructed from control and SCZ samples, using top genes in the M2c module that have non-zero leverage. We exclude 6 genes that do not have annotated gene names, and show the remaining 22 primary genes (colored in white) and 85 secondary genes (colored in grey). The adjacency matrix is constructed by thresholding the absolute Pearson correlation |Rij| at 0.5. Larger node sizes represent larger leverage.
Table 2.
Annotated names of 22 primary genes and 85 secondary genes in the M2c module, listed in the descending order of leverage. The 6 underlined genes are also significant in the differential expression analysis
| Gene names | |
|---|---|
| Primary genes | ABHD2 SLC23A2 LRRC55 CRKL ZBTB24 TUBGCP3 KCTD10 USP13 MORC2-AS1 REXO2 HEXIM1 TOX3 FNIP2 WBP11 SYT11 SMAD3 SLC36A4 SNX30 PCDHB12 PURB TGOLN2 OSBP |
| Secondary genes | SH3RF1 IMPAD1 SYNM HECW2 ANO1 DNM3 STOX2 C1orf173 PPM1L DNAJC6 DLG2 LRRTM4 ANK3 EIF4G3 ANK2 ITSN1 SLIT2 LRRTM3 ATP8A2 CNTNAP2 CKAP5 GNPTAB USP32 USP9X ADAM23 SYNPO2 AKAP11 MAP1B KIAA1244 PPP1R12B SLC24A2 PTPRK SATB1 CAMTA1 MFSD6 KIAA1279 NTNG1 RYR2 RASAL2 PUM1 STAM ST8SIA3 ZKSCAN2 PBX1 ARHGAP24 RASA1 ANKRD17 MYCBP2 SLITRK1 BTRC MYH10 AKAP6 NRCAM MYO5A TRPC5 NRXN3 CACNA2D1 DNAJC16 GRIN2A KCNQ5 NETO1 FTO THRB NLGN1 HSPA12A BRAF OPRM1 KIAA1549L NOVA1 OPCML CEP170 DLGAP1 JPH1 LMO7 PCNX SYNJ1 RAPGEF2 NIPAL2 SYT1 UNC80 ATP8A1 SHROOM2 KCNJ6 SNAP91 WDR7 |
To shed light on the nature of the genes identified in the M2c module, we conduct a Gene Ontology (GO) enrichment analysis (Chen et al., 2013). The secondary gene list is most easily interpreted. It is highly enriched for genes directly involved in synaptic processes, both for GO Biological Process and Molecular Function. Two key molecular functions involve calcium channels/calcium ion transport and glutamate receptor activity. Under Biological Process, these themes are emphasized and synaptic organization emerges too. Synaptic function is a key feature that emerges from genetic findings for SCZ, including calcium channels/calcium ion transport and glutamate receptor activity (see Owen, Sawa and Mortensen (2016) for review).
For the primary genes, under GO Biological Process, “regulation of transforming growth factor beta2 (TGF-β2) production” is highly enriched. The top GO Molecular Function term is SMAD binding. The protein product of SMAD3 (one of the primary genes) modulates the impact of transcription factor TGF-β regarding its regulation of expression of a wide set of genes. TGF-β is important for many developmental processes, including the development and function of synapses (Diniz et al., 2012). Moreover, and notably, it has recently been shown that SMAD3 plays a crucial role in synaptogenesis and synaptic function via its modulation of how TGF-β regulates gene expression (Yu et al., 2014). It is possible that disturbed TGF-β signaling could explain co-expression patterns we observe in Figure 3, because this transcription factor will impact multiple genes. Another primary gene of interest is OSBP. Its protein product has recently been shown to regulate neural outgrowth and thus synaptic development (Gu et al., 2015). Thus perturbation of a set of genes could explain the pattern seen in Figure 3.
4.2. Robustness of the results
In this section, we illustrate that sLED remains powerful under perturbation of smoothing parameters and the boundaries of the M2c module. We first apply sLED with 1,000 permutations on the M2c module using c ∈ {0.10, 0.12, ⋯, 0 30}, (recall that ). Each experiment is repeated 10 times, and the average p-value and the standard deviation for each experiment are shown in Figure 4a. All of the average p-values are smaller than 0.02. Note that larger values of c typically lead to denser solutions, which may hinder interpretability in practice. We also examine the stability of the list of 25 primary genes. For each value of c, we record the ranks of these 25 primary genes when ordered by leverage, and their average ranks with the standard deviations are visualized in Figure 4b. It is clear that these 25 primary genes are consistently the leading ones in all experiments.
Fig. 4.
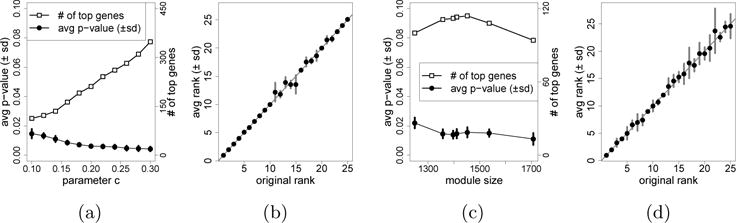
(a) sLED applied on the M2c module with c ∈ {0.10, ⋯, 0.30}. For each c we visualize the number of genes with non-zero leverage, as well as· the average and standard deviation of p-values in 10 repetitions, each using 1,000 permutations. (b) The average and standard deviation of ranks of the 25 primary genes when c ∈ {0.10, ⋯, 0.30}, where ranks are based on the descending order of leverage. (c) sLED applied on·7·modules using c = 0.1, including the original M2c module as well as 6 differently perturbed modules with sizes {1248, 1357, 1397, 1452, 1537, 1708}. For each (perturbed) module, we visualize the number of genes with non-zero leverage, as well as the average and standard deviation of p-values in 10 repetitions, each using 1,000 permutations. (d) The average and standard deviation of ranks of the 25 primary genes when sLED is applied on the 7 (perturbed) modules using c = 0.1, where ranks are based on the descending order of leverage.
Now we examine the robustness of sLED to perturbation of the module boundaries. Specifically, we perturb the M2c module by removing some genes that are less connected within the module, or including extra genes that are well-connected to the module. As suggested in Zhang and Horvath (2005), the selection of genes is based on their correlation with the eigengene (i.e., the first principal component) of the M2c module, calculated using the 279 control samples. By excluding the M2c genes with correlation smaller than {0.2, 0.3, 0.4}, we obtain three sub-modules with sizes {1397, 1357, 1248}, respectively. By including extra genes outside the M2c module with correlation larger than {0.75, 0.7, 0.65}, we obtain three sup-modules with sizes {1452, 1537, 1708}, respectively. We apply sLED with c = 0.1 and 1,000 permutations to these 6 perturbed modules. For each perturbed module, we examine the permutation p-values in 10 repetitions, as well as the ranks of the 25 primary genes when ordered by leverage. As shown in Figure 4c and Figure 4d, the results from sLED remain stable to such module perturbation.
4.3. Generalization to weighted adjacency matrices
Finally, we illustrate that sLED is not only applicable to testing differences in covariance matrices, but can also be applied to comparing general gene-gene “relationship” matrices. As an example, we consider the weighted adjacency matrix , defined as
| (4.1) |
where Rij is the Pearson correlation between gene i and gene j, and the constant β > 0 controls the density of the corresponding weighted gene network. The weighted adjacency matrix is widely used as a similarity measurement for gene clustering, and has been shown to yield genetic modules that are biologically more meaningful than using regular correlation matrices (Zhang and Horvath, 2005). Now the testing problem becomes
where . While classical two-sample covariance testing procedures are inapplicable under this setting, sLED can be easily generalized to incorporate this scenario. Let , then the same permutation procedure as described in Section 2.2 can be applied.
We explore the results of sLED for β ∈ {1, 3, 6.5, 9}, corresponding to four different choices of weighted adjacency matrices. We choose the same sparsity parameter c = 0.1 for sLED as in section 4.1, and with 1,000 permutations, the p-values are 0.020, 0.001, 0.002, and 0.006 for the 4 choices of β’s respectively. The latter three are significant at level 0.05 after a Bonferroni correction.
Interestingly, we find our results to be closely related to the connectivity of genes in the M2c module, where the connectivity of gene i is defined as
Figure 5 compares the gene connectivities between control and SCZ samples, where the top genes with non-zero leverage detected by sLED are highlighted. It is clear that the connectivity of genes is typically higher in control samples. Furthermore, as β increases, the differences on highly connected genes are enlarged, and consistently, the top genes detected by sLED also concentrate more and more on these “hub” genes that are densely connected. These genes would have been missed by the covariance matrix test, but are now revealed using weighted adjacency matrices. A Gene Ontology (GO) enrichment analysis (Chen et al., 2013) highlights a different, although related, set of biological processes when β = 9 versus β = 1 (Table 3).
Fig. 5.
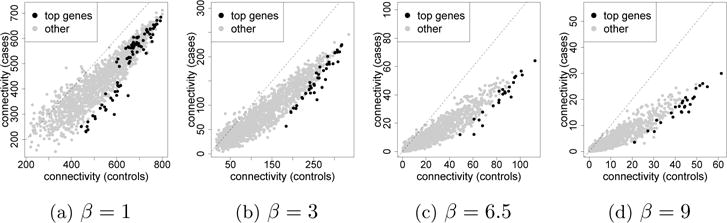
Connectivity in the M2c module for control and SCZ samples using weighted adjacency matrices with different β’s. The top genes detected by sLED with non-zero leverage are highlighted in black, and the auxiliary line y = x is shown in each plot.
Table 3.
Top 5 terms in Gene Ontology (GO) enrichment analysis on the top genes using weighted adjacency matrices with β ∈ {1, 9}. The adjusted p-values are reported in parentheses.
| β = 1 | β = 9 | |
|---|---|---|
| 1 | Positive regulation of cell development (4.4e-05) | Synaptic transmission (5.6e-06) |
| 2 | Axon extension (4.6e-04) | Energy reserve metabolic process (6.5e-06) |
| 3 | Regulation of cell morphogenesis involved in differentiation (1.7e-04) | Divalent metal ion transport (4.1e-05) |
| 4 | Neuron projection extension (7.0e-04) | Divalent inorganic cation transport (4.5e-05) |
| 5 | Positive regulation of nervous system development (6.5e-04) | Calcium ion transport (2.8e-05) |
5. Conclusion and discussion
In this paper, we propose sLED, a permutation test for two-sample covariance matrices under the high dimensional regime, which meets the need to understand the changes of gene interactions in complex human diseases. We prove that sLED achieves full power asymptotically; and in many biologically plausible settings, we verify by simulation studies that sLED outperforms many other existing methods. We apply sLED to a recently produced gene expression data set on Schizophrenia, and provide a list of 113 genes that show altered co-expression when brain samples from cases are compared to that from controls. We also reveal an interesting pattern of gene correlation change that has not been previously detected. The biological basis for this pattern is unclear. As more gene expression data become available, it will be interesting to validate these findings in an independent data set.
sLED can be applied to many other data sets for which signals are both sparse and weak. The performance is theoretically guaranteed for sub-Gaussian distributions, but we observe in simulation studies that sLED remains powerful when data has heavier tails. In terms of running time, on the 1,411 genes considered in this paper, sLED with 1,000 permutations takes 40 minutes using a single core on a computer equipped with an AMD Opteron(tm) Processor 6320 @ 2.8 GHz. When dealing with larger datasets, it is straightforward to parallelize the permutation procedure and further reduce the computation time.
Finally, we illustrate that sLED can be applied to a more general class of differential matrices between other gene-gene relationship matrices that are of practical interest. We show an example of comparing two weighted adjacency matrices and how this reveals novel insight on Schizophrenia. Although we have only stated the consistency results for testing covariance matrices, similar theoretical guarantee may be established for other relationship matrices as long as similar error bounds as in theorem 2 hold. This is a first step towards testing general high-dimensional matrices, and we leave a more thorough exploration in this direction to future work.
Supplementary Material
Acknowledgments
We thank the editors and anonymous reviewers for their constructive comments. This work was supported by the Simons Foundation (SFARI 124827), R37MH057881 (Bernie Devlin and Kathryn Roeder), R0109900 (Kathryn Roeder), and National Science Foundation DMS-1407771 (Jing Lei). Data were generated as part of the CommonMind Consortium supported by funding from Takeda Pharmaceuticals Company Limited, F. Hoffman-La Roche Ltd and NIH grants R01MH085542, R01MH093725, P50MH066392, P50MH080405, R01MH097276, RO1-MH-075916, P50M096891, P50MH084053S1, R37MH057881 and R37MH057881S1, HHSN271201300031C, AG02219, AG05138 and MH06692. Brain tissue for the study was obtained from the following brain bank collections: the Mount Sinai NIH Brain and Tissue Repository, the University of Pennsylvania Alzheimers Disease Core Center, the University of Pittsburgh NeuroBioBank and Brain and Tissue Repositories and the NIMH Human Brain Collection Core. CMC Leadership: Pamela Sklar, Joseph Buxbaum (Icahn School of Medicine at Mount Sinai), Bernie Devlin, David Lewis (University of Pittsburgh), Raquel Gur, Chang-Gyu Hahn (University of Pennsylvania), Keisuke Hirai, Hiroyoshi Toyoshiba (Takeda Pharmaceuticals Company Limited), Enrico Domenici, Laurent Essioux (F. Hoffman-La Roche Ltd), Lara Mangravite, Mette Peters (Sage Bionetworks), Thomas Lehner, Barbara Lipska (NIMH).
Footnotes
SUPPLEMENTARY MATERIAL
Supplemental document for “Testing High Dimensional Covariance Matrices, with Application to Detecting Schizophrenia Risk Genes”. This supplement provides additional simulation results as well as proofs for the theorems.
References
- Anderson TW, Anderson TW, Anderson TW, Anderson TW. An introduction to multivariate statistical analysis. Vol. 2. Wiley; New York: 1958. [Google Scholar]
- Bai Z, Jiang D, Yao JF, Zheng S. Corrections to LRT on large-dimensional covariance matrix by RMT. The Annals of Statistics. 2009:3822–3840. [Google Scholar]
- Berthet Q, Rigollet P. Optimal detection of sparse principal components in high dimension. The Annals of Statistics. 2013;41:1780–1815. [Google Scholar]
- Cai T, Liu W, Xia Y. Two-sample covariance matrix testing and support recovery in high-dimensional and sparse settings. Journal of the American Statistical Association. 2013;108:265–277. [Google Scholar]
- Cai TT, Zhang A. Inference on High-dimensional Differential Correlation Matrix. Journal of Multivariate Analysis. 2015;142:107–126. doi: 10.1016/j.jmva.2015.08.019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chang J, Zhou W, Zhou WX, Wang L. Comparing Large Covariance Matrices under Weak Conditions on the Dependence Structure and its Application to Gene Clustering. arXiv preprint arXiv. 2016 doi: 10.1111/biom.12552. 1505.04493v3. [DOI] [PubMed] [Google Scholar]
- Chen EY, Tan CM, Kou Y, Duan Q, Wang Z, Meirelles GV, Clark NR, Ma’ayan A. Enrichr: interactive and collaborative HTML5 gene list enrichment analysis tool. BMC Bioinformatics. 2013;14:128. doi: 10.1186/1471-2105-14-128. [DOI] [PMC free article] [PubMed] [Google Scholar]
- International Schizophrenia Consortium. Purcell SM, Wray NR, Stone JL, Visscher PM, O’Donovan MC, Sullivan PF, Sklar P. Common polygenic variation contributes to risk of schizophrenia and bipolar disorder. Nature. 2009;460:748–52. doi: 10.1038/nature08185. [DOI] [PMC free article] [PubMed] [Google Scholar]
- d’Aspremont A, El Ghaoui L, Jordan MI, Lanckriet GR. A direct formulation for sparse PCA using semidefinite programming. SIAM review. 2007;49:434–448. [Google Scholar]
- Diniz LP, Almeida JC, Tortelli V, Vargas Lopes C, Setti-Perdigão P, Stipursky J, Kahn SA, Romão LF, de Miranda J, Alves-Leon SV, de Souza JM, Castro NG, Panizzutti R, Gomes FCA. Astrocyte-induced synaptogenesis is mediated by transforming growth factor signaling through modulation of D-serine levels in cerebral cortex neurons. J Biol Chem. 2012;287:41432–45. doi: 10.1074/jbc.M112.380824. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fromer M, Roussos P, Sieberts SK, Johnson JS, Kavanagh DH, Perumal TM, Ruderfer DM, Oh EC, Topol A, Shah HR, Klei LL, Kramer R, Pinto D, Gümüs ZH, Cicek AE, Dang KK, Browne A, Lu C, Xie L, Readhead B, Stahl EA, Xiao J, Parvizi M, Hamamsy T, Fullard JF, Wang YC, Mahajan MC, Derry JMJ, Dudley JT, Hemby SE, Logsdon BA, Talbot K, Raj T, Bennett DA, De Jager PL, Zhu J, Zhang B, Sullivan PF, Chess A, Purcell SM, Shinobu LA, Mangravite LM, Toyoshiba H, Gur RE, Hahn CG, Lewis DA, Haroutunian V, Peters MA, Lipska BK, Buxbaum JD, Schadt EE, Hirai K, Roeder K, Brennand KJ, Katsanis N, Domenici E, Devlin B, Sklar P. Gene expression elucidates functional impact of polygenic risk for schizophrenia. Nat Neurosci. 2016;19:1442–1453. doi: 10.1038/nn.4399. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gu X, Li A, Liu S, Lin L, Xu S, Zhang P, Li S, Li X, Tian B, Zhu X, Wang X. MicroRNA124 Regulated Neurite Elongation by Targeting OSBP. Mol Neurobiol. 2015 doi: 10.1007/s12035-015-9540-4. [DOI] [PubMed] [Google Scholar]
- Johnstone IM, Lu AY. On consistency and sparsity for principal components analysis in high dimensions. Journal of the American Statistical Association. 2009;104:682–693. doi: 10.1198/jasa.2009.0121. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Jolliffe IT, Trendafilov NT, Uddin M. A modified principal component technique based on the LASSO. Journal of computational and Graphical Statistics. 2003;12:531–547. [Google Scholar]
- Lei J, Vu VQ. Sparsistency and agnostic inference in sparse PCA. The Annals of Statistics. 2015;43:299–322. [Google Scholar]
- Li J, Chen SX. Two sample tests for high-dimensional covariance matrices. The Annals of Statistics. 2012;40:908–940. [Google Scholar]
- McGrath J, Saha S, Chant D, Welham J. Schizophrenia: a concise overview of incidence, prevalence, and mortality. Epidemiol Rev. 2008;30:67–76. doi: 10.1093/epirev/mxn001. [DOI] [PubMed] [Google Scholar]
- Schizophrenia Working Group of the Psychiatric Genomics Consortium. Biological insights from 108 schizophrenia-associated genetic loci. Nature. 2014;511:421–7. doi: 10.1038/nature13595. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Owen MJ, Sawa A, Mortensen PB. Schizophrenia. Lancet. 2016 doi: 10.1016/S0140-6736(15)01121-6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Oymak S, Jalali A, Fazel M, Eldar YC, Hassibi B. Simultaneously Structured Models with Application to Sparse and Low-rank Matrices. IEEE Transactions on Information Theory. 2015;61:2886–2908. [Google Scholar]
- Purcell SM, Moran JL, Fromer M, Ruderfer D, Solovieff N, Roussos P, O’Dushlaine C, Chambert K, Bergen SE, Kähler A, Duncan L, Stahl E, Genovese G, Fernández E, Collins MO, Komiyama NH, Choudhary JS, Magnusson PKE, Banks E, Shakir K, Garimella K, Fennell T, DePristo M, Grant SGN, Haggarty SJ, Gabriel S, Scolnick EM, Lander ES, Hultman CM, Sullivan PF, McCarroll SA, Sklar P. A polygenic burden of rare disruptive mutations in schizophrenia. Nature. 2014;506:185–90. doi: 10.1038/nature12975. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Schott JR. A test for the equality of covariance matrices when the dimension is large relative to the sample sizes. Computational Statistics & Data Analysis. 2007;51:6535–6542. [Google Scholar]
- Shen H, Huang JZ. Sparse principal component analysis via regularized low rank matrix approximation. Journal of multivariate analysis. 2008;99:1015–1034. [Google Scholar]
- Srivastava MS, Yanagihara H. Testing the equality of several covariance matrices with fewer observations than the dimension. Journal of Multivariate Analysis. 2010;101:1319–1329. [Google Scholar]
- Székely GJ, Rizzo ML. Energy statistics: A class of statistics based on distances. Journal of Statistical Planning and Inference. 2013;143:1249–1272. [Google Scholar]
- Vu VQ, Cho J, Lei J, Rohe K. Fantope projection and selection: A near-optimal convex relaxation of sparse PCA. Advances in Neural Information Processing Systems. 2013;26:2670–2678. [Google Scholar]
- Witten DM, Tibshirani R, Hastie T. A penalized matrix decomposition, with applications to sparse principal components and canonical correlation analysis. Biostatistics. 2009;10:515–534. doi: 10.1093/biostatistics/kxp008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wu TL, Li P. Tests for High-Dimensional Covariance Matrices Using Random Matrix Projection. arXiv preprint arXiv. 2015 1511.01611. [Google Scholar]
- Yu CY, Gui W, He HY, Wang XS, Zuo J, Huang L, Zhou N, Wang K, Wang Y. Neuronal and astroglial TGF-Smad3 signaling pathways differentially regulate dendrite growth and synaptogenesis. Neuromolecular Med. 2014;16:457–72. doi: 10.1007/s12017-014-8293-y. [DOI] [PubMed] [Google Scholar]
- Zhang B, Horvath S. A general framework for weighted gene co-expression network analysis. Statistical applications in genetics and molecular biology. 2005;4 doi: 10.2202/1544-6115.1128. Article17. [DOI] [PubMed] [Google Scholar]
- Zou H, Hastie T, Tibshirani R. Sparse principal component analysis. Journal of computational and graphical statistics. 2006;15:265–286. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.