
Fig. 3.
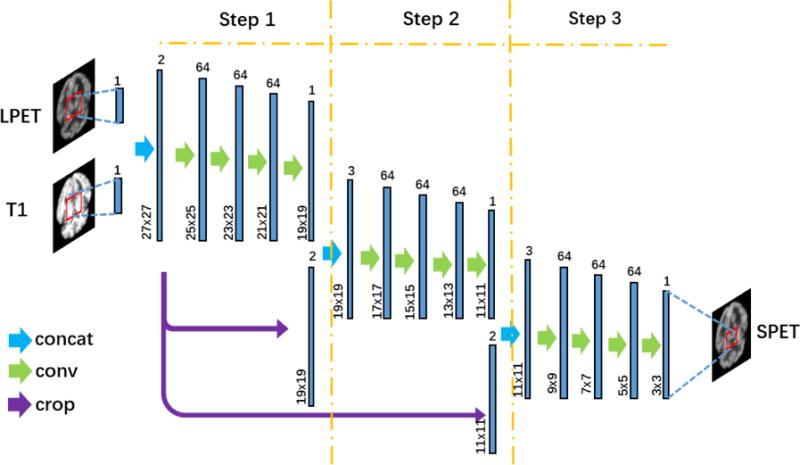
Illustration of the deep auto-context CNN architecture. ‘Concat’ represents concatenation operation that concatenates individual feature maps. ‘Conv’ represents the convolutional operation. ‘Crop’ represents the crop operation that keeps the sizes of different feature maps consistent. In Step 1, the inputs of the basic four-layer CNN are LPET and T1 images. In Step 2 and Step 3, the tentatively estimated SPET image from the last step is also included as an additional input.