Figure 8. Conditions on feedback synapses for effective learning.
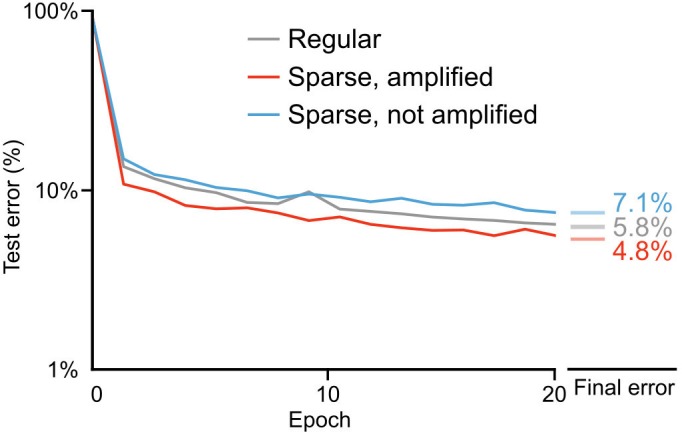
(A) Diagram of a one hidden layer network trained in B, with 80% of feedback weights set to zero. The remaining feedback weights were multiplied by five in order to maintain a similar overall magnitude of feedback signals. (B) Plot of test error across 60 epochs for our standard one hidden layer network (gray) and a network with sparse feedback weights (red). Sparse feedback weights resulted in improved learning performance compared to fully connected feedback weights. Right: Spreads (min – max) of the results of repeated weight tests () after 60 epochs for each of the networks. Percentages indicate mean final test errors for each network (two-tailed t-test, regular vs. sparse: , ). (C) Diagram of a one hidden layer network trained in D, with feedback weights that are symmetric to feedforward weights , and symmetric but with added noise. Noise added to feedback weights is drawn from a normal distribution with variance . (D) Plot of test error across 60 epochs of our standard one hidden layer network (gray), a network with symmetric weights (red), and a network with symmetric weights with added noise (blue). Symmetric weights result in improved learning performance compared to random feedback weights, but adding noise to symmetric weights results in impaired learning. Right: Spreads (min – max) of the results of repeated weight tests () after 60 epochs for each of the networks. Percentages indicate means (two-tailed t-test, random vs. symmetric: , ; random vs. symmetric with noise: , ; symmetric vs. symmetric with noise: , , Bonferroni correction for multiple comparisons).

Figure 8—figure supplement 1. Importance of weight magnitudes for learning with sparse weights.