Figure 2. Learning non-linear dynamics via FOLLOW: the van der Pol oscillator.
(A-C) Control input, output, and error are plotted versus time: before the start of learning; in the first 4 s and last 4 s of learning; and during testing without error feedback (demarcated by the vertical red lines). Weight updating and error current feedback were both turned on after the vertical red line on the left at the start of learning, and turned off after the vertical red line in the middle at the end of learning. (A) Second component of the input . (B) Second component of the learned dynamical variable (red) decoded from the network, and the reference (blue). After the feedback was turned on, the output tracked the reference. The output continued to track the reference approximately, even after the end of the learning phase, when feedback and learning were turned off. The output tracked the reference approximately, even with a very different input (Bii). With higher firing rates, the tracking without feedback improved (Figure 2—figure supplement 1). (C) Second component of the error between the reference and the output. (Cii) Trajectory in the phase plane for reference (red,magenta) and prediction (blue,cyan) during two different intervals as indicated by and in Bii. (D) Mean squared error per dimension averaged over 4 s blocks, on a log scale, during learning with feedback on. Learning rate was increased by a factor of 20 after 1,000 s to speed up learning (as seen by the sharp drop in error at 1000 s). (E) Histogram of firing rates of neurons in the recurrent network averaged over 0.25 s (interval marked in green in H) when output was fairly constant (mean across neurons was 12.4 Hz). (F) As in E, but averaged over 16 s (mean across neurons was 12.9 Hz). (G) Histogram of weights after learning. A few strong weights are out of bounds and not shown here. (H) Spike trains of 50 randomly-chosen neurons in the recurrent network (alternating colors for guidance of eye only). (I) Spike trains of H, reverse-sorted by first spike time after 0.5 s, with output component overlaid for timing comparison.

Figure 2—figure supplement 1. Learning van der Pol oscillator dynamics via FOLLOW with higher firing rates.

Figure 2—figure supplement 2. Learning linear dynamics via FOLLOW: 2D decaying oscillator.

Figure 2—figure supplement 3. Readout weights learn if recurrent weights are as is, but not if shuffled.
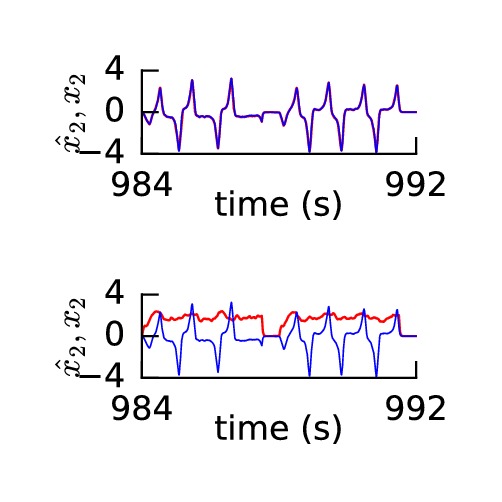
Figure 2—figure supplement 4. Learning non-linear feedforward transformation with linear recurrent dynamics via FOLLOW.

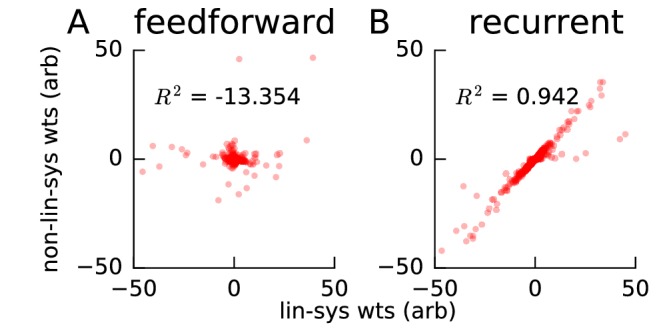
Figure 2—figure supplement 5. Feedforward weights are uncorrelated, while recurrent ones are correlated, when learning same recurrent dynamics but with different feedforward transforms.