

Abstract
In this paper, we present an efficient and robust algorithm for shape matching, registration, and detection. The task is to geometrically transform a source shape to fit a target shape. The measure of similarity is defined in terms of the amount of transformation required. The shapes are represented by sparse-point or continuous-contour representations depending on the form of the data. We formulate the problem as probabilistic inference using a generative model and the EM algorithm. But this algorithm has problems with initialization and computing the E-step. To address these problems, we define a discriminative model which makes use of shape features. This gives a hybrid algorithm which combines the generative and discriminative models. The resulting algorithm is very fast, due to the effectiveness of shape-features for solving correspondence requiring typically only four iterations. The convergence time of the algorithm is under a second. We demonstrate the effectiveness of the algorithm by testing it on standard datasets, such as MPEG7, for shape matching and by applying it to a range of matching, registration, and foreground/background segmentation problems.
Keywords: shape matching, registration, soft assign, EM, shape context
1 Introduction
Shape matching is a very important problem in computer vision. The work in this paper treats shape matching as finding the best geometrical transformation between two shapes in the spirit of Grenander’s pattern theory [12].
There is a big literature on the different varieties of shape representations, matching criteria, and algorithms that have been applied to this problem. This includes representations such as Fourier analysis [43], moments [14], scale space [24], and level sets [27]. Some representations, such as FORMS [44] or shock-edit [33], explicitly represent the shape in terms of parts. Other approaches using chamfer matching [35] formulate the problem to enable rapid search through different appearances of the shape. Alternative approaches include manifold learning and metric embedding [15] and hierarchical structures with associative graphs [28]. For more details of shape representations and matching algorithms see recent survey papers [19,39]. Our approach is mostly closely related to the probabilistic formulation using free energies developed by [8,30,21] and the work on shape context [4].
We formulate the problem in terms of probabilistic inference using a generative model. This formulation involves hidden variables which indicate the correspondence between points on the two shapes. This leads naturally to an EM algorithm based on the free energy formulation [26]. Unfortunately computational issues make performing the E-step impractical and also give problems for initialization. We solve these problems by introducing a discriminative model which uses shape features. These shape features are less ambiguous for matching than points, and hence we call them informative features. This leads to a hybrid algorithm which combines the generative and discriminative models. See Tu et al [36] for more discussion of the trade-off between generative and discriminative methods.
Our approach helps unify existing work by Chui and Rangarajan [8] and Belongie et al [4]. We use a probabilistic formulation similar to Chui and Rangarajan but combine this with the shape features described by Belongie et al. This leads to an algorithm that has fewer iterations and better initialization than Chui and Rangarajan, while being better at dealing with uncertainty than Belongie et al.
Our approach represents the shapes in terms of points, which are supplemented by shape feature for the discriminative models. We use two types of representations – sparse-point and continuous-contour. The continuous-contour representation leads to better shape features, since the arc-length is known, but this representation is not always practical to compute. These representations are adequate for this paper, but their lack of ability to represent shape parts makes them unsuitable for matching shapes when parts can be missing (unlike methods such as [44,33]).
The structure of this paper is as follows. Section (2) gives the generative formulation of the problem. In section (3), we motivate the discriminative approach. Section (4) describes how the algorithm combines the two methods. In section (5) we give examples on a range of datasets and problems.
2 The Generative Formulation
The task of shape matching is to match two shapes, X and Y, and to measure the similarity between them. We refer to X as the target shape and Y as the source shape. We define the similarity measure in terms of the transformation that takes the source shape into the target, see figure 6. In this paper we use two types of transformation: (i) a global affine transformation A and (ii) a smooth non-rigid transformation f.
Fig. 6.

The MPEG7 CE-Shape-1.
2.1 Shape Representation
We use two types of shape representation in this paper: (I) sparse-point, and (II) continuous-contour. The choice will depend on the form of the data. Shape matching will be easier if we have a continuous-contour representation because we are able to exploit knowledge of the arc-length to obtain shape features which are less ambiguous for matching, and hence more informative, see section (3.1). But it may only be possible to compute a sparse-point representation for the target shape (e.g. the target shape may be embedded in an image and an edge detector will usually not output all the points on its boundary).
-
For the sparse-point representation, we denote the target and source shape respectively by:
(1) -
For the continuous-contour representation, we denote the target and source shape respectively by:
where s and t are the normalized arc-length. In this case, each shape is represented by a 2D continuous-contour. By sampling points along the contour we can obtain a sparse-point representation X = {xi : i = 1, …, M}, and Y = {ya : a = 1, …, N}. But we can exploit the continuous-contour representation to compute additional features that depend on differentiable properties of the contour such as tangent angles.(2)
2.2 The Generative Model
Our generative model for shape matching defines a probability distribution for generating the target X from the source Y by means of a geometric transformation (A, f). There will be priors P(A), P(f) on the transformation which will be specified in section (2.3).
We also define binary-valued correspondence variables {Vai} such that Vai = 1 if point a on the source Y matches point i on the target X. These are treated as hidden variables. There is a prior P(V) which specifies correspondence constraints on the matching (e.g. to constrain that all points on the source Y must be matched).
The choice of the correspondence constraints, as specified in P(V) is very important. They must satisfy a trade-off between the modeling and computational requirements. Constraints that are ideal for modeling purposes can be computationally intractable. The prior P(V) will be given in section (2.5) and the trade-off discussed.
The full generative model is P(X, V, A, f|Y) = P(X|Y, V, A, f)P(A)P(f)P(V), where the priors are given in sections (2.3), (2.5). The distribution P(X|Y, V, A, f) is given by:
| (3) |
By using the priors P(A), P(f), P(V) and summing out the V’s, we obtain (this equation defines ET [A, f; X, Y]):
| (4) |
We define the optimal geometric transformation to be:
| (5) |
We define the similarity measure between shapes to be
| (6) |
This is the negative logarithm of probability of generating the target X from the source Y by the optimal transformation, with the normalization constant Ẑ removed. This similarity measure will also correspond to the minimum of the free energy, see equation (12) (again with the normalization constant removed).
2.3 The Geometric Prior
The geometric transformation consists of a global (affine) transformation A and a smooth non-rigid transformation f (which includes a translation term). The prior on the non-rigid transformation f will enforce it to be smooth, and will be given at the end of this section. The prior on the affine transformation A is defined based on its decomposition into rotation angle θ, scaling Sx, Sy, and shear k. It encourages equal scaling both directions and favors limited shear.
More precisely, we decompose the affine transformation as follows:
| (7) |
The prior on A is given by
| (8) |
where , Eshear(s) = b2k2, and Erot(θ) is constant (i.e. the prior on θ is the uniform distribution). In our experiments, we set b1 = 1.0 and b2 = 10.0.
The prior on the non-rigid transformation f is of form:
| (9) |
In this paper, we use the thin-plate-spline (TPS) kernel [5] where we impose that f is of form:
| (10) |
where are vector valued weights, x, y are the components of the vector y, U(x, y) = (x2 + y2) log(x2 + y2), t is translation, Σa wa = 0, and . Then we define Ef by:
| (11) |
We also considered an alternative energy function which encourages f to be small and smooth (Yuille and Grzywacz [41]). The small-and-smooth energy function usually gave similar results to the thin-plate-spline, but it required us to model the translation t separately. We will not discuss it further in this paper. Note that in our ECCV paper [37] our reported results were obtained using the TPS, but we erroneously stated that they were obtained using small-and-smooth.
2.4 The EM algorithm
We use the EM algorithm to estimate (A*, f*) = arg maxA,f P(X, A, f|Y), where the correspondence variables V are treated as hidden variables which are summed out.
It can be shown [26] that estimating (A*, f*) from P(X, A, f|Y) is equivalent to minimizing the EM free energy function:
| (12) |
where Q(V) is a distribution over the correspondence variables. The minimum of the free energy F(Q, A, f) is equal to minA,f {− log P(X, A, f|Y)}.
The EM algorithm consists of two steps: (I) The M-step minimizes F(Q, A, f) with respect to (A, f) with Q(V) fixed and will be given in detail in section (4).(II) The E-step minimizes F(Q, A, f) with respect to Q(V) keeping (A, f) fixed. The E-step at iteration t can be expressed analytically as:
| (13) |
Unfortunately there are two difficulties with using the EM algorithm in the current form. Firstly, it requires good initialization or it will get stuck in a local maximum of P(X, A, f|Y). Secondly, the E-step is very difficult to compute unless we put restrictions on the prior P(V) which are so strong that they may degrade the quality of the result, see section (2.5). These problems motivate us to introduce a discriminative model, see section (3).
2.5 The Correspondence Constraints and P(V)
The prior P(V) enforces constraints on the correspondences between points on the target and the source. This leads to a trade-off between modeling and computational requirements.
From the modeling perspective, we would prefer constraints which are two-sided between the target and source. These constraints would enforce that most target and source points are matched, and would be flexible enough to allow for missing points. But imposing two-sided constraints makes the E-step of the EM algorithm impractical, because it is impossible to compute the right-hand side of equation (13).
One strategy to deal with this problem is by using a mean field theory approximation together with two-sided constraints. This strategy was used by Chui and Rangarajan [8] and was very successful. We will describe it at the end of this section.
Another strategy is to impose one-sided constraints which ensure that all points on the sources are either matched to points on the target, or are unmatched (and pay a penalty). In theory, this would allow situations where a single point of the target is matched to many points on the source, while many other target points are unmatched. In practice, the nature of the geometric transformations can prevent these situations from happening (since they correspond to highly improbable, or impossible, geometric transformations).
In this paper, we choose to impose the one-sided constraint that each point a is either matched to a single point v(a), or it is unmatched and we set v(a) = 0. (equivalently v(a) = Σi Vaii, where Σi Vai = 1 or 0 for all a). Then we put a prior probability on V, , which penalizes missing points. This choice of prior has the major advantage that it is factorizable P(V) =∏a Pa(v(a)). It means that we can minimize the free energy (12) to solve for:
| (14) |
with .
This gives an analytic expression for the E-step of the EM algorithm – by replacing Q by Qt on the left hand side, and A, f by At−1, ft−1 on the right hand side of equation (14).
We can also use equation (14) to obtain a simple expression for the free energy which depends only on A, f. To do this, we first express:
| (15) |
Secondly, we substitute Q(V) from equation (14) into the free energy (12) to obtain:
| (16) |
Note that a simplification occurs because log , hence parts of the term Σb Qb(Vb) log Qb(Vb) cancels with some terms from ΣV Q(V)ET [A, f, V; X, Y].
This enables us to rapidly compute the free energy (except for the normalization term log Z̄ which we do not use in our shape similarity criterion).
This E-step in equation (14) is computationally simple, but it gives poor performance when applied to the generative model. The number of iterations required for convergence is large (e.g greater than 20) and the algorithm can get stuck in local minima of F(Q, A, f) and produce distorted matching. These errors can be traced to the use of point features for matching and their inherent ambiguity compounded by the use of one-sided constraints.
Our solution is to augment the generative model with a discriminative model, see section (3). The discriminative model uses shape features which are far less ambiguous for matching, and hence more informative, than point features. The use of shape features was developed by Belongie et al [4] who used them in conjunction with two-sided constraints requiring one to one correspondence (with some ability to tolerate unmatched points). Note that Belongie et al did not formulate their approach probabilistically.
An alternative by Chui and Rangarajan [8] makes use of the mean field approximation to the free energy [42,11]. They impose matching constraints , ∀i and , ∀a, where the indices a = 0 and i = 0 denote dummy points which can be used to allow for unmatched points (e.g. Va0 = 1 implies that point a is unmatched). The prior will add a penalty term to encourage most points to be matched.
A simplified version of Rangarajan and Chui’s mean field free energy is expressed in the form:
| (17) |
where Ef(f) is given by equation (11), f(ya) is given by equation (10), and the variable mai denotes Q(Vai = 1). By comparison to equation (12), we see that the mean field formulation approximates the entropy term ΣV Q(V) log Q(V) by . The last term is used to penalize unmatched points. The minimization of F({mai}, A, f) is done by imposing the two-sided correspondence constraints which transform into constraints on , ∀i and , ∀a.
While this approach can give very successful results [8], it does need good initialize conditions, and can require many iterations to converge (see section (5)). Rangarajan et al [30] have considered the alternative Bethe/Kikuchi free energy approximation. This appears to yield good results, but the convergence rate is slow.
3 The Discriminative Model
The generative model described above is an attractive way to formulate the problem. But it has three computational disadvantages: (i) the initialization, (ii) the one-sided correspondence constraints required to perform the E-step, (iii) the convergence rate. These problems arise because the ambiguity of point features for matching.
To address these concerns, we develop a complementary discriminative model. This model makes use of shape features which exploit the local and global context of the shape. These shape features are motivated by shape contexts [4] and are far less ambiguous for matching than the points used in the generative model. We therefore call them informative features. The shape features for the continuous-contour representation exploit knowledge of the arc-length, and so will be more informative than those for the sparse-point representation. As will be described in section (4), the shape features enable us to get good initialization and to obtain a practical E-step which gives rapid convergence (in combination with the M-step based on the generative model).
To formally specify the discriminative model, we define shape features on the target by φ(xi), and on the source by φ(Aya + f(ya)). This implies that the features on the source shape depend on the current estimates of the geometric transformation (A, f), which is initialized to be the identity. Intuitively, we are warping the source onto the target. We define a similarity measure between the shape features to be q(., .). The forms of φ and q(., .) will be defined in sections (3.1),(3.2) and will differ for the continuous-contour and sparse-point representations.
The discriminative model is given by PD(V, A, f|X, Y) = PD(V|X, Y, A, f)P(A)P(f), where the priors P(A), P(f) are defined as in section (2.3), and:
| (18) |
This equation expresses the correspondence variables in terms of the one-sided variables v(a). This has disadvantages, as described in section (2.5). But these disadvantages are far less severe for the discriminative model because the shape features are far less ambiguous for matching than the point features. Note that this does not include a term allowing for unmatched points (analogous to the λ term in equation (14)). We experimented with such a term, but it did not make any significant difference.
The free energy for the discriminative model is defined to be:
| (19) |
As before, the use of one-sided constraints means that we can factorize Q(V) and compute it as:
| (20) |
This gives the discriminative free energy:
| (21) |
We can also use equation (20) to calculate the E-step by setting the left-hand-side to be the distribution at time t with the right-hand-side evaluated at time t − 1.
The M-step is more difficult since it requires differentiating the features φ and the matching term q(., .) with respect to (A, f). The M-step will not be used in our complete algorithm.
This discriminative model has similarities to the shape features model [4]. The main difference is that the shape context model is not formulated in a probabilistic framework. Instead it requires that the source and target shapes have the same number of points and requires that each point has a unique match. This can be problematic when there are unequal numbers of points and can cause false matching. Our method is like softmax [8,42] and allows for uncertainty.
3.1 Shape features for the Continuous-Contour Representation
The local and global features for the continuous-contour representation are illustrated in figure (6).
The local features at a point x(si) with tangent angle ψi are defined as follows. Choose six points on the curve by
| (22) |
where ds is a small constant (ds = 0.01 in our experiments). The angles of these positions with respect to the point xi are (ψi + ωj, j = 1, …, 6). The local features are hl(xi) = (ωj, j = 1, …, 6).
The global features are selected in a similar way. We choose six points near x(si), with tangent angle ψi, to be
| (23) |
where Δs is a large constant (Δs = 0.1 in our experiments), with angles ψi + ψj : j = 1, …, 6. The global features are hg(xi) = (ψj, j = 1, …, 6). Observe that the features φ = (hl, hg) are invariant to rotations in the image plane.
These shape features are informative for matching. Figure (6)(b) plots sinusoids (sin(hl), sin(hg)) for two points on X and two points on Y. Observe the similarity between these features on the corresponding points.
The similarity measure between the two points is defined to be:
| (24) |
where Dangle(ωj(xi) − ωj(ya)) is the minimal angle from ωj(xi) to ωj(ya) (i.e. modulo 2π), and c1 is a normalization constant. The right panel in figure (6)(c) plots the vector qc(y) = [qc(φ(xi), φ(y)), i = 1..M] as a function of i for points ya and yb on Y respectively.
3.2 Shape Features for the Sparse-Point Representation
In this case, we also use local and global features. To obtain the local feature for point xi, we draw a circle with radius r (in our experiments r = 9.0 × r̄, where r̄ is the average distance between points) and collect all the points that fall within the circle. The angles of these points relative to xi are computed. The histogram of these angles is then used as the local feature, Hl. Observe that this representation is not invariant to rotation.
The global feature for the sparse points is computed by shape contexts [4] to give a histogram Hg (60 histogram bins are used in the experiments). The local and global features are represented together as φ = (Hl, Hg).
The feature similarity between two points xi and ya is measured by the χ2 distance on the histograms:
| (25) |
To show the effectiveness of these features, the left panel of figure (6)(c) plots the vector
| (26) |
as a function of i for a point ya on Y.
The features for the sparse-point representation are generally less informative than those for the continuous-contour representation. For example, the shape context features [4] and histogram similarity measures tend to have high entropy, see figure (6)(c).
4 The Full Algorithm
Our complete algorithm combines aspects of the generative and the discriminative models. We first use the discriminative model to help initialize the algorithm, see section (4.1). Then we use the M-step from the generative model and the E-step from the discriminative model.
Both steps are guaranteed to decrease the free energy of the corresponding model, but there is no guarantee that the M-step will decrease the free energy for the discriminative model – or that the E-step will decrease the free energy for the generative model. Nevertheless out computer simulations show that they always do, see section (4.4).
4.1 Initialization
We use the discriminative model for initialization. In this paper, we only initialize with respect to θ since the rest of the algorithm was fairly insensitive to other global parameters such as scaling.
In theory, the initialization should be done by marginalizing over the irrelevant variables. To estimate the full affine transformation A we should compute P(A|X, Y), and to estimate the angle θ we should compute P(θ|X, Y). But these computations are impractical for either the generative or discriminative models.
Instead we use an approximation PIn(θ|X, Y) motivated by the discriminative model,
| (27) |
where q(., .) = qc(., .) or qs(., .) depending on whether we use the continuous-contour or sparse-point representation. Here θ(a, i, X, Y) is the estimated angle if we match point i on X to point a on Y.
We evaluate the distribution PIn(θ|X, Y) using mean-shift clustering to obtain several modes. The peaks of this distribution gives estimates for the initial values of θinitial. In rare cases, the distribution will have several peaks. For example, suppose we are matching the equilateral triangles shown in figure (6). In this case PIn(θ|X, Y) will have three peaks, and we will have to consider initializations based on each peak.
To initialize the continuous-contour representation, we can exploit the rotational invariance of the features. This means that we only need to evaluate them for a small set of angles. But for the sparse-point representation, the features are not invariant to rotation.
In rare cases, we will require to sum over several modes. For example, three modes (θ*, ) are required when matching two equal lateral triangles, see figure (6).
4.2 The E Step: Approximating Q(V)
The features for the continuous-contour representation are altered after the initialization by incorporating the local tangent angle ψi at each point. This makes these features rotation dependent.
We also augment the similarity measure by including the scaled relative position of the point to the center of the shape. For a point xi on the target shape, this gives xi − x̄ where . We compute a similar measure ya − ȳ, with . The full similarity measure is defined to be:
| (28) |
where c1 = 0.7 and c2 = 0.8 in our implementation.
This gives a factorized probability model:
| (29) |
where
| (30) |
4.3 The M Step: Estimating A and f
The M-step corresponds to minimizing the following energy function with respect to (A, f):
| (31) |
where PD(i, a) = PD(va = i|ya, X, A, f).
Recall that we write . We re-express the energy as:
| (32) |
We take the derivatives of EM with respect to A, {wb}, t and set them to zero:
| (33) |
| (34) |
Here μ, ν, ρ are the spatial indices, the partial derivative of EA is evaluated at the previous state.
Equation (34) gives a set of linear equations in A, {wb}, t, which can be solved by complicated variant of the techniques described in [4].
4.4 Summary of the Algorithm
The algorithm proceeds as follows:
Given a target shape X and a source shape Y, it computes their shape features and estimates the rotation angle(s) θ0.
For each rotation angle θ0, rotate the shape Y by θ0 to Yθ0 Initialize the remaining transformations to be the identity.
Estimate the features for the rotated shape Yθ0. Use these to initialize Q(V) using the E-step of the discriminative model.
Calculate (A, f) by performing the M-step for the generative model (using a quadratic approximation).
Transform Y by (A, f), then repeat the last two stages for M iterations.
Compute the similarity measure P(X, A*, f*|Y) and keep the best (A*, f*), and compute the measure according to equation (6).
In practice, we found that M = 4 iterations was typically a sufficient number of iterations because of the effectiveness of the features (the shape context algorithm [4] uses M = 3). We needed M = 10 iterations for the experiments in section (5.3). The algorithm runs at 0.2 seconds for matching X and Y of around 100 points on PC with 2.0Ghz.
Figure (6) gives an example of the algorithm where the source shape Y in (d) is matched with the target shape X. Figure (6)(e) and (f) show the estimated transformation A* and f*.
Figure (6) shows the generative and discriminative free energies plotted for the example. Observe that both decrease monotonically.
5 Experiments
We tested our algorithm on standard shape matching datasets and for grey level image tasks such as registration, recognition, and foreground/background segmentation. We use the continuous-contour representation for examples 5.1.,5.2, and 5.4 and the sparse-point representation for the remainder.
5.1 MPEG7 Shape Database
We first tested our algorithm on the MPEG7 CE-Shape-1 [18] database. This database contains 70 types of objects each of which has 20 different silhouette images, giving a total of 1400 silhouettes. Since the input images are binarized, we can extract the contours and use the continuous-contour representation. Figure (6)(a) displays two images for each object type. The task is to do retrieval and the recognition rate is measured by the Bull’s eye criterion [18]. A single shape is presented as a query and the top 40 matches are obtained. This is repeated for every shape and the number of correct matches (out of a maximum total of 20) are obtained.
The recognition rates for different algorithms are given in table 6. On this dataset our algorithm outperforms the alternatives. The speed is in the same range as those of shape contexts [4] and curve edit distance [32].
5.2 The Kimia Data Set
We then tested the identical algorithm (i.e. continuous-contour representation and with the same algorithm parameters) on the Kimia data set of 99 shapes [33]. These are shown in figure (6)(a). For each shape, the 10 best matches are picked (since there are 10 other images in the same category). Table 6 shows the numbers of correct matches. Our method performs similarly to Shock Edit [33] for the top 7 matches, but is worse for the remainder. Shape context performs worse than either algorithm on this task. Figure (6)(b) shows the 15 top matches for some shapes.
The reason that our algorithm does worse than Shock Edit on the last three examples is because the geometric deformations involve the presence or absence of parts, see figure (6). Our model does not take these types of geometric transformation into account. Dealing with them requires a more sophisticated shape representation.
5.3 Chui and Rangarajan Data Set
We tested our algorithm on data supplied by Chui and Rangarajan [8]. This data includes noise points in the target shape. We use the sparse-point representation since we do not have a closed contour for each shape.
The algorithm runs for 10 steps for this dataset and results are given in figure 6. The quality of our results are similar to those reported in [8]. But our algorithm runs an estimated 20 times fewer iteration steps.
5.4 Text Image Matching
The algorithm was also tested on real images of text in which binarization was performed by the method described in [7], followed by boundary extraction. This enabled us to perform shape matching using the continuous-contour representation. Several examples are shown in figure 6. Similar results can be obtained by matching the model to edges in the image.
5.5 Foreground/background Segmentation
Our next example is a foreground/background segmentation task. The input is a grey level image with a horse in the foreground. In this case, binarization and edge detection techniques are unable to estimate the boundary of the horse. Instead we use a novel boundary detector named Boosted Edge Learning (BEL) [10] which is learnt from training data and makes use of local image context. BEL is applied to all points on the Canny edge map of the image. The output of BEL is a probability map which gives the probability that each pixel is on the edge of the horse. We sample from this probability map to obtain 300 points which we use as the sparse-point representation of the target shape.
The source shape is represented by 300 points randomly sampled from the silhouette of a horse. Figure 6 shows an example on horse data [6].
5.6 Application to medical image registration
Finally we applied our algorithm to the task of registering medical images. This is an important practical task which has been addressed by a variety of methods [23] including mutual information [22,29,40].
In this example, we used SIFT [20] to detect interest-points which we use as sparse-point representations for the target and source shapes. Then we applied our shape matching algorithm. The SIFT features are invariant to rotation and scaling, so we do not need to recalculate them as the algorithm proceeds.
Figure 6 shows the registration process using our shape matching method. Figure 6 shows more results of registration between different modalities of images, such as Computed Tomography (CT) versus Magnetic Resonance Imaging (MRI), Proton Density (PD) versus MRI, and we see that the registered results are very good.
Previous authors have applied SIFT to medical image registration [25,38]. But these papers used SIFT features and the shape context model [4] and so did not take uncertainty into account.
6 Conclusion
In this paper, we presented an efficient algorithm for shape matching, recognition, and registration. We defined a generative and discriminative models and discussed their relationships to softassign [8] and shape contexts [4]. We used an EM algorithm for inference by exploiting properties of both models. A key element is the use of informative shape features to guide the algorithm to rapid and correct solutions. We illustrated our approach on datasets of binary and real images, and gave comparison to other methods. Our algorithm runs at speeds which are either comparable to other algorithms or considerably faster.
Our work is currently limited by the types of representations we used and the transformations we allow. For example, it would give poor results for shape composed of parts that can deform independently (e.g. human figures). For such objects, we would need representations based on symmetry axes such as skeletons [32] and parts [44].
Fig. 1.
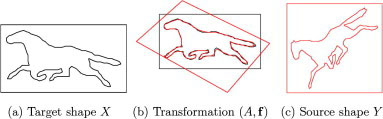
An example of shape matching where a source shape Y is matched with a target shape X by a geometric transformation (A, f).
Fig. 2.
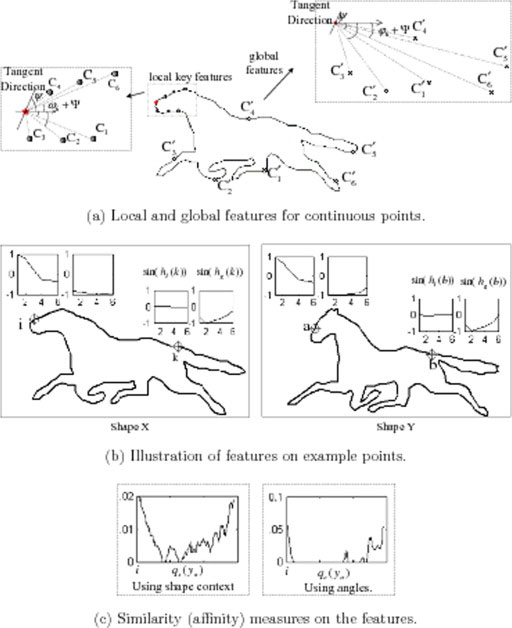
The features and the similarity measure. Panel (a) illustrates how the local and global features are measured for the complete-contour representation. The left window shows the angles computed at the local neighboring points which are used to compute the local shape features. The right window shows the angles computed in larger neighborhoods to compute the global features. Panel (b) displays the features of two points in shape X and Y. As angles have periodic property, we show the a angle vectors by their sinusoid values. As we can see, the corresponding points i on X and a on Y, and k on X and b on Y have similar features. The left and right figure in panel (c) plot the similarities between point a on Y with respect to all points in X using the shape context (on sparse points) feature and angle features (on complete-contour) respectively. As we can see similarities by features defined in this paper for connected points have lower entropy than these given by shape contexts. They are less ambiguous and more informative.
Fig. 3.

The distribution p(θ|X, Y), shown in (f), has three modes for a target shape X, shown in (a), and a source shape Y, shown in (b). The three possible values for θ are shown in (c), (d), and (e).
Fig. 4.
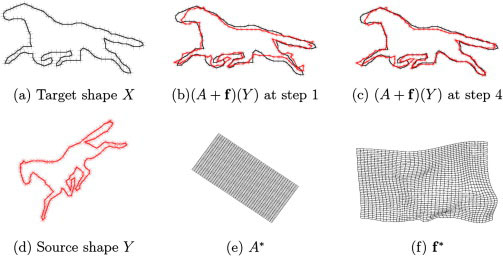
The dynamics of the algorithm for the horse example.
Fig. 5.
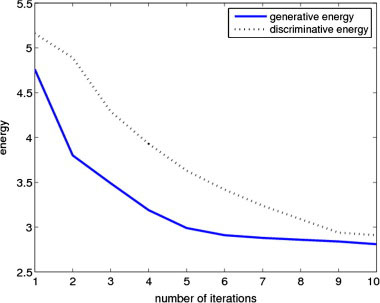
Illustration of the decrease of generative free energy and discriminative free energy by our algorithm. We see that both the free energies consistently decrease w.r.t. time.
Fig. 7.

The Kimia data set of 99 shapes and some matching results.
Fig. 8.
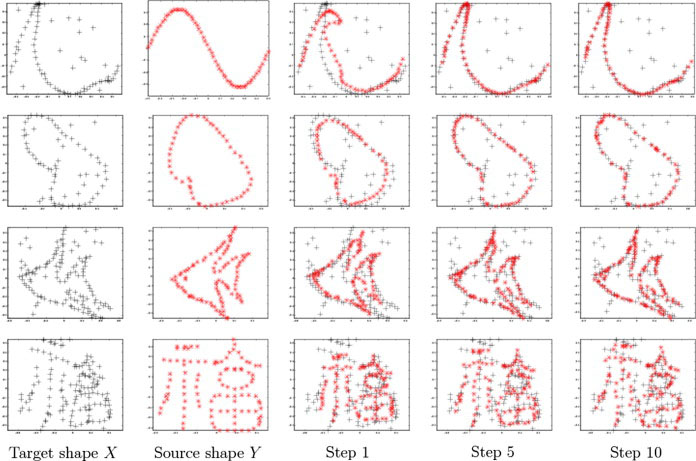
Some results on the Chui and Rangarajan data set.
Fig. 9.

Results on some text images. (c) and (i) display the matching. We purposely superimpose two shapes extracted from different images together and make a new input. Our algorithm is robust in this case.
Fig. 10.

Foreground/background segmentation; (a) input image; (b) the probability map of BEL; (c) the product of BEL map and the canny edge map; (d) sampled points according to the probability (c) ; (e) the template; (f) (i) the result after the first, the third, the 7th and 10th iteration; (j) the segmented foregound according to the matching result.
Fig. 11.
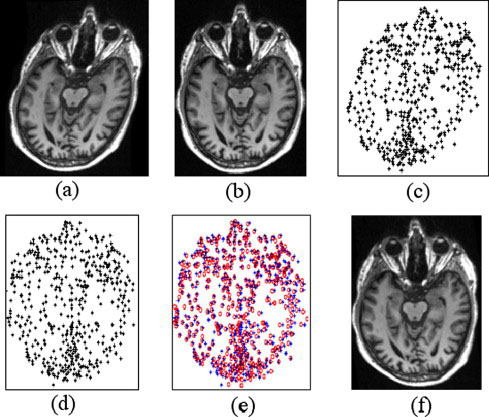
Medical image registration: (a) the unregistered image; (b) the template image; (c) (d) the SIFT key points for the unregistered and template images; (e) the matching result; (f) the registered image.
Fig. 12.
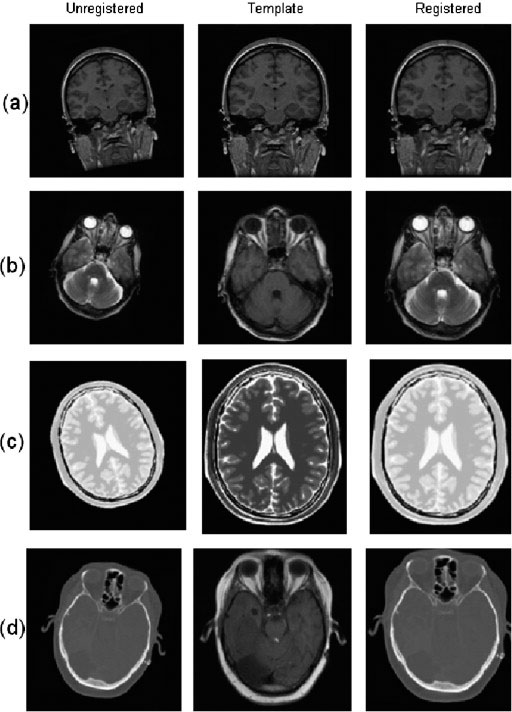
Examples of registration result: (a) MRI registration; (b) registration an unregistered T2 image to a T1 image; (c) registration an unregistered CT image to an MR image; (d) registration an unregistered PD image to a T2 image.
Table 1.
The retrieval rates of different algorithms for the MPEG7 CE-Shape-1. The results by the other algorithms are taken from Sebastian et al. [32].
Table 2.
The number of matched shapes by the different algorithms. The results by the other algorithms are due to Sebastian et al. [33].
| Algorithm | Top 1 | Top 2 | Top 3 | Top 4 | Top 5 | Top 6 | Top 7 | Top 8 | Top 9 | Top 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| Shock Edit | 99 | 99 | 99 | 98 | 98 | 97 | 96 | 95 | 93 | 82 |
| Our Method | 99 | 97 | 99 | 98 | 96 | 96 | 94 | 83 | 75 | 48 |
| Shape Contexts | 97 | 91 | 88 | 85 | 84 | 77 | 75 | 66 | 56 | 37 |
Acknowledgments
This project was done when Zhuowen Tu was a post-doc at UCLA supported by NIH (NEI) grant 1R01EY013875. We thank Dr. David Lowe for sharing the SIFT source code online. We thank comments from anonymous reviewers for improving the clarity of the paper.
Footnotes
Publisher's Disclaimer: This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customers we are providing this early version of the manuscript. The manuscript will undergo copyediting, typesetting, and review of the resulting proof before it is published in its final citable form. Please note that during the production process errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal pertain.
Contributor Information
Zhuowen Tu, Lab of Neuro Imaging (LONI), Department of Neurology, UCLA, 635 Charles E. Young Drive South, Los Angeles, CA 90095, USA.
Songfeng Zheng, Department of Statistics, UCLA, 8125 Math Sciences Bldg, Los Angeles, CA 90095, USA.
Alan Yuille, Department of Statistics, UCLA, 8967 Math Sciences Bldg, Los Angeles, CA 90095, USA.
References
- 1.Abbasi S, Mokhtarian F. Robustness of Shape Similarity Retrieval under Affine Transformation. Proc. of Challenge of Image Retrieval; Newcastle upon Tyne, UK. Feb. 1999. [Google Scholar]
- 2.Ballard DH. Generalizing the Hough Transform to Detect Arbitrary Shapes. Pattern Recognition. 1981;13(2):714–725. [Google Scholar]
- 3.Basri R, Costa L, Geiger D, Jacobs D. Determining The Similarity of Deformable Shapes. Vision Research. 1998;38(15):2365–2385. doi: 10.1016/s0042-6989(98)00043-1. [DOI] [PubMed] [Google Scholar]
- 4.Belongie S, Malik J, Puzicha J. Shape Matching and Object Recognition Using Shape Contexts. IEEE Trans on Pattern Analysis and Machine Intelligence. 2002 Apr;24(24):509–522. doi: 10.1109/TPAMI.2005.220. [DOI] [PubMed] [Google Scholar]
- 5.Bookstein FL. Principal Warps: Thin-Plate Splines and the Decomposition of Deformations. IEEE Trans on Pattern Analysis and Machine Intelligence. 1989;11(6):567–585. [Google Scholar]
- 6.Borenstein E, Sharon E, Ullman S. Combining top-down and bottom-up segmentation. Proc IEEE workshop on Perc Org in Com Vis. 2004 Jun;4:46–53. [Google Scholar]
- 7.Chen X, Yuille AL. AdaBoost Learning for Detecting and Reading Text in City Scenes. Proc. IEEE Conf. Computer Vision and Pattern Recognition; Washington, DC. June 2004.pp. 366–373. [Google Scholar]
- 8.Chui H, Rangarajan A. A New Point Matching Algorithm for Non-rigid Registration. Computer Vision and Image Understanding. 2003 Feb;89:114–141. [Google Scholar]
- 9.Dempster AP, Laird NM, Rubin DB. Maximum-likelihood from Incomplete Data via the Em Algorithm. J Royal Statist Soc, Ser B. 1977;39 [Google Scholar]
- 10.Dollár P, Tu Z, Belongie S. Supervised learning of edges and object boundaries. Proc. IEEE Conf. Computer Vision and Pattern Recognition; New York. June 2006.pp. 1964–1971. [Google Scholar]
- 11.Geiger D, Yuille AL. A common framework for image segmentation. Int’l Journal of Computer Vision. 1991 Aug;6(3):227–243. [Google Scholar]
- 12.Grenander U. General Pattern Theory: A Mathematical Study of Regular Structures. Oxford: 1994. [Google Scholar]
- 13.Helstrom CW. Approximate Evaluation of Detection Probabilities in Radar And Optical Communications. IEEE Trans Aerosp Electron Syst. 2003 July 1;14:630–640. [Google Scholar]
- 14.Hu MK. Visual Pattern Recognition by Moment Invariants. IEEE Trans Inform Theory. 1962;8:179–187. [Google Scholar]
- 15.Keselman Y, Shokoufandeh A, Demirci M, Dickinson S. Many-to-Many Graph Matching via Metric Embedding. Proc. IEEE Conf. Computer Vision and Pattern Recognition; Madison, WI. 2003. pp. 850–857. [Google Scholar]
- 16.Klassen E, Srivastava A, Mio W, Joshi SH. Analysis of Planar Shapes Using Geodesic Paths on Shape Spaces. IEEE Trans on Pattern Analysis and Machine Intelligence. 2004 Mar;26(3):372–383. doi: 10.1109/TPAMI.2004.1262333. [DOI] [PubMed] [Google Scholar]
- 17.Kumar MP, Torr PHS, Zisserman A. OBJCUT. Proc IEEE Conf Computer Vision and Pattern Recognition. 2005;1:18–25. [Google Scholar]
- 18.Latechi LJ, Lakamper R, Eckhardt U. Shape Descriptors for Non-rigid Shapes with a Single Closed Contour. Proc IEEE Conf Computer Vision and Pattern Recognition. 2000 Jun;1:424–429. [Google Scholar]
- 19.Loncaric S. A Survey of Shape Analysis Techniques. Pattern Recognition. 1998 Aug;31(8):983–1001. [Google Scholar]
- 20.Lowe DG. Distinctive Image Features From Scale-invariant Keypoints. Int’l Journal of Computer Vision. 2004;60(2):91–110. [Google Scholar]
- 21.Luo B, Hancock ER. A Unified Framework for Alignment and Correspondence. Computer Vision and Image Understanding. 2003 Oct;92(1):26–55. [Google Scholar]
- 22.Maes F, Collignon A, Vandermeulen D, Marchal G, Suetens P. Multimodality Image Registration by Maximization of Mutual Information. IEEE Trans on Medical Imaging. 1997 Feb;16(2):187–198. doi: 10.1109/42.563664. [DOI] [PubMed] [Google Scholar]
- 23.Maintz JB, Viergever MA. A Survey of Medical Image Registration. Medical Image Analysis. 1998;2(1):1–36. doi: 10.1016/s1361-8415(01)80026-8. [DOI] [PubMed] [Google Scholar]
- 24.Mokhtarian F, Mackworth AK. A Theory of Multiscale, Curvature-Based Shape Representation for Planar Curves. IEEE Trans on Pattern Analysis and Machine Intelligence. 1992 Aug;14(8):789–805. doi: 10.1109/tpami.1986.4767750. [DOI] [PubMed] [Google Scholar]
- 25.Moradi M, Abolmaesoumi P, Mousavi P. Deformable Registration Using Scale Space Keypoints. Medical Imaging 2006: Image Processing Proceedings of the SPIE. 2006;6144:791–798. [Google Scholar]
- 26.Neal R, Hinton GE. Learning in Graphical Models. MIT Press; 1998. A View Of The Em Algorithm That Justifies Incremental, Sparse, And Other Variants; pp. 355–368. [Google Scholar]
- 27.Paragios N, Rousson M, Ramesh V. Matching Distance Functions: A Shape-to-Area Variational Approach for Global-to-Local Registration. Proc of European Conference on Computer Vision. 2002;2:775–788. [Google Scholar]
- 28.Pelillo M, Siddiqi K, Zucker SW. ”Matching Hierarchical Structures Using Association Graphs. IEEE Trans on Pattern Analysis and Machine Intelligence. 1999 Nov;21(11):1105–1119. [Google Scholar]
- 29.Pluim JP, Maintz JBA, Viergever MA. Mutual-information-based Registration of Medical Images: A Survey. IEEE Trans on Medical Imaging. 2003 Aug;22(8):986–1004. doi: 10.1109/TMI.2003.815867. [DOI] [PubMed] [Google Scholar]
- 30.Rangarajan A, Coughlan JM, Yuille AL. A Bayesian Network for Relational Shape Matching. Proc of Int’l Conf on Computer Vision. 2003;1:671–678. Nice France. [Google Scholar]
- 31.Ren X, Fowlkes C, Malik J. Proc of Advances in Neural Information Processing Systems 18. MIT Press; 2005. Cue Integration in Figure/Ground Labeling; pp. 1121–1128. [PubMed] [Google Scholar]
- 32.Sebastian TB, Klein PN, Kimia BB. On Aligning Curves. IEEE Trans on Pattern Analysis and Machine Intelligence. 2003;25(1):116–125. doi: 10.1109/TPAMI.2004.1273924. [DOI] [PubMed] [Google Scholar]
- 33.Sebastian TB, Klein PN, Kimia BB. Recognition of Shapes by Editing their Shock Graphs. IEEE Trans on Pattern Analysis and Machine Intelligence. 2004 May;26(5):550–571. doi: 10.1109/TPAMI.2004.1273924. [DOI] [PubMed] [Google Scholar]
- 34.Sharon E, Mumford D. 2D-Shape Analysis using Conformal Mapping. Proc IEEE Conf Computer Vision and Pattern Recognition. 2004 Jun;2:350–357. [Google Scholar]
- 35.Thayananthan A, Stenger B, Torr PHS, Cipolla R. Shape Context and Chamfer Matching in Cluttered Scenes. Proc IEEE Conf Computer Vision and Pattern Recognition. 2003;1:127–133. [Google Scholar]
- 36.Tu Z, Chen X, Yuille A, Zhu SC. Image Parsing: Unifying Segmentation, Detection and Recognition. Int’l Journal of Computer Vision. 2005 Jul;63(2):113–140. [Google Scholar]
- 37.Tu Z, Yuille A. Shape Matching and Recognition–Using Generative Models and Informative Features. Proc of European Conference on Computer Vision. 2004;III:195–209. [Google Scholar]
- 38.Urschler M, Bauer J, Ditt H, Bischof H. SIFT and Shape Context for Feature-Based Nonlinear Registration of Thoracic CT Images. International ECCV Workshop on Computer Vision Approaches to Medical Image Analysis; Graz, Austria. 2006. pp. 73–84. [Google Scholar]
- 39.Veltkamp RC, Hagedoorn M. Technical Report UU-CS-1999–27. Utrecht; 1999. State of the Art in Shape Matching. [Google Scholar]
- 40.Wells WM, III, Viola P, Atsumi H, Nakajima S, Kikinis R. Multi-modal Volume Registration by Maximization of Mutual Information. Medical Image Analysis. 1996;1(1):35–52. doi: 10.1016/s1361-8415(01)80004-9. [DOI] [PubMed] [Google Scholar]
- 41.Yuille AL, Grzywacz NM. A Computational Theory for the Perception of Coherent Visual Motion. Nature. 1988;333(6168):71–74. doi: 10.1038/333071a0. [DOI] [PubMed] [Google Scholar]
- 42.Yuille AL. Generalized Deformable Models, Statistical Physics, and Matching Problems. Neural Computation. 1990;2(1):1–24. [Google Scholar]
- 43.Zahn CT, Roskies RZ. Fourier Descriptors for Plane Closed Curves. IEEE Trans on Computers. 1972 Mar;C-21(3):269–281. [Google Scholar]
- 44.Zhu SC, Yuille AL. FORMS: A Flexible Object Recognition and Modeling System. Int’l Journal of Computer Vision. 1996;20(3):187–212. [Google Scholar]