
Fig. 1.
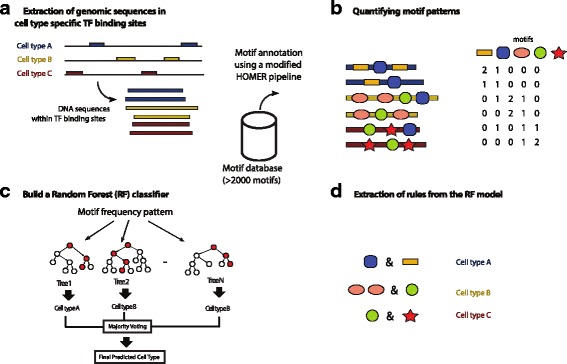
Our bioinformatics workflow for DNA motif annotation, Random Forest (RF) classifier training and motif grammar extraction. The workflow consists of four steps. a Step 1: extraction of the genomic sequences from the cell-type specific TF binding sites. b Step 2: annotation of these sequences using a large database of motifs. c Step 3: training of a RF classifier. d Step 4: Motif rule (grammar) extraction from the RF classifier