

Abstract
Estimating individualized treatment rules is a central task for personalized medicine. [23] and [22] proposed outcome weighted learning to estimate individualized treatment rules directly through maximizing the expected outcome without modeling the response directly. In this paper, we extend the outcome weighted learning to right censored survival data without requiring either inverse probability of censoring weighting or semiparametric modeling of the censoring and failure times as done in [26]. To accomplish this, we take advantage of the tree based approach proposed in [28] to nonparametrically impute the survival time in two different ways. The first approach replaces the reward of each individual by the expected survival time, while in the second approach only the censored observations are imputed by their conditional expected failure times. We establish consistency and convergence rates for both estimators. In simulation studies, our estimators demonstrate improved performance compared to existing methods. We also illustrate the proposed method on a phase III clinical trial of non-small cell lung cancer.
Keywords and phrases: Individualized treatment rule, Nonparametric estimation, Right censored data, Excess value bound, Recursively imputed survival trees, Outcome weighted learning
1. Introduction
An individualized treatment regime provides a personalized treatment strategy for each patient in the population based on their individual characteristics. A significant amount of work has been devoted to estimating optimal treatment rules [17, 18, 22, 24, 23]. While each of these approaches has strengths and weaknesses, we highlight the approach in [23] because of its robustness to model misspecification (this is similarly true of the approach in [22]) combined with its ability to incorporate support vector machines through the recognition that optimizing the treatment rule can be recast as a weighted classification problem. This approach is commonly referred to as outcome weighted learning. In clinical trials, right censored survival data are frequently observed as primary outcomes. Adapting outcome weighted learning to the censored setting, [26] proposed two new approaches, inverse censoring weighted outcome weighted learning and doubly robust outcome weighted learning, both of which require semiparametric estimation of the conditional censoring probability given the patient characteristics and treatment choice. The doubly robust estimator additionally involves semiparametric estimation of the conditional failure time expectation but only requires that one of the two models, for either the failure time or censoring time, be correct. Potential drawbacks of these methods are that either or both models may be misspecified and inverse censoring weighting estimation can be unstable numerically [18, 28].
In this paper, we propose a nonparametric tree based approach for right censored outcome weighted learning which avoids both the inverse probability of censoring weighting and restrictive modeling assumptions for imputation through recursively imputed survival trees [28]. Since the true failure times T are only partially known, they cannot be used directly as weights in the outcome weighted learning [23] framework. However, recursively imputed survival trees [28] provide an alternative approach to weighting by using the conditional expectations of censored observations without requiring inverse weighting. Tree-based methods [4, 3] are a broad class of nonparametric estimators which have become some of the most popular machine learning tools. Its adaptation to the survival setting has also drawn a lot of interests in the literature [14, 9, 11], and it has also been used for interpretable prediction modeling in personalized medicine [12]. The recursively imputed survival tree approach [28] combines extremely randomized trees with a recursive imputation method, which has been shown to improve performance and reduce prediction error while avoiding estimation of inverse censoring weights without making parametric or semiparametric assumptions on the conditional probability distribution of the failure time. Numerical studies demonstrate that the proposed method outperforms existing alternatives in a variety of settings.
The proposed method uses these recursively imputed survival trees to impute the survival times nonparametrically in a manner suitable for implementation within outcome weighted learning. We verify this novel approach both theoretically and in numerical examples. As part of this, we also present for the first time consistency and rate results for tree-based survival models in a more general setting than the categorical predictors considered in [10].
The remainder of the article is organized as follows. In section 2, we present the mathematical framework for individualized treatment rules for right censored survival outcomes. In section 3 we establish consistency and an excess value bound for the estimated treatment rules. Extensive simulation studies are presented in Section 4. We also illustrate our method using a phase III clinical trial on non-small cell lung cancer in Section 5. The article concludes with a discussion of future work in Section 6. Some needed technical results are provided in the Appendix.
2. Methodology
2.1. Individualized treatment regime framework
Before characterizing the individualized treatment regime, we first introduce some general notation and introduce the value function, and then extend the notation and ideas to the censored data setting. Let be the observed patient-level covariate vector, where is a d dimensional vector space, and let A ∈ {−1, +1} be the binary treatment indicator. is the true survival time, however, we consider a truncated version at τ, i.e., , where the maximum follow-up time τ < ∞ is a common practical restriction in clinical studies. The goal in this framework is to maximize a reward R, which could represent any clinical outcome. Specifically, we wish to identify a treatment rule , which is a map from the patient-level covariate space to the treatment space {+1, −1} which maximizes the expected reward. In the survival outcome setting, we use R = T or log(T) as done in [26].
To achieve this maximization, we define the value function as
where I{·} is an indicator function, π(a; X) = pr(A = a|X) > M′ a.s. for some M′ > 0 and each a ∈ {+1, −1}. The function π is the propensity score and is known in a randomized trial setting, which we assume is the case for this paper, but needs to be estimated in a non-randomized, observational study setting. The individualized treatment regime we are most interested in is the optimal treatment rule which maximizes the value function, i.e.
| (1) |
After rewriting the value function as
it is easy to see that
Hence, the definition of is equivalent to . Instead of maximization the objective function in (1), the outcome weighted learning approach searches for the optimal decision rule by minimizing the weighted misclassification error, i.e.,
| (2) |
In an ideal situation, we would replace R with T or log(T). However, this is not possible under right censoring.
2.2. Value function under right censoring
Consider a censoring time C that is independent of T given (X, A). We then have the observed time Y = min(T, C), and the censoring indicator δ = I(T ≤ C). Assume that n independent and identically distributed copies, , are collected. Since T is not fully observed we seek for a sensible replacement which maintains as close as possible the same value function. We propose two approaches in the following, denoted as R1 and R2 respectively. The first approach is to obtain a nonparametric estimated conditional expectation . Letting R1 = E(T | X, A) and bringing the expectation of T inside, we have
| (3) |
Another approach is to replace only the censored observations conditioning on the observed data. It is interesting to observe that the conditional expectation of T, given Y and δ, can be written as
| (4) |
An important property that we used in the last equality is the conditional independence between T and C. With the information of Y = y given, and knowing that δ = 0, the conditional distribution of T is defined on (c, τ] with density function proportional to the original density of T. In other words, the conditional survival function of T is S(t|X, A)/S(c|X, A) for t > c, where S(·|X, A) is the conditional survival function of T. Hence, we can calculate the expectation of T accordingly. With the definition of R2, it is easy to see that the corresponding value function is equivalent to the left side of equation (3) by further taking expectations with respect to Y and δ. Note that the above arguments remain unchanged if we replace T, C and Y with log(T), log(C), and log(Y), respectively: this equivalence will be tacitly utilized throughout the paper, except when the distinction is needed.
With our proposed two reward measures, the remaining challenge is to nonparametrically estimate the conditional expectations. To this end, we utilize the nonparametric tree based method proposed by [28]. It is worth noting that the conditional expectation of T defined in R2 shares the same logical underpinnings as the imputation step in [28]. However, the goal of the imputation step is to replace the censored observations with a randomly generated conditional failure time which utilizes the same condition survival distribution of T given T > C. We will provide details of the estimation procedure in the next section. To conclude this section, we provide the empirical versions of the value function using the two rewards R1 and R2, respectively, which we solve for the optimal decision by minimization:
| (5) |
| (6) |
2.3. Outcome weighted learning with survival trees
The recursively imputed survival trees method proposed by [28] is a powerful tool to estimate conditional survival functions for censored data. A brief outline of the algorithm is provided in the following. We refer interested readers to the original paper for details. To fit the model, we first generate extremely randomized survival trees for the training dataset. Secondly, we calculate conditional survival functions for each censored observation, which can be used for imputing the censored value to a random conditional failure time. Thirdly, we generate multiple copies of the imputed dataset, and one survival tree is fitted for each dataset. We repeat the last two steps recursively and the final nonparametric estimate of is obtained by averaging the trees from the last step.
Following [23], we next use support vector machines to solve for the optimal treatment rule. A decision function f(x) is learned by replacing in Equations (5) or (6) with ϕ{Aif(Xi)}, where ϕ(x) = (1 − x)+ is the hinge loss and x+ = max(x, 0). Furthermore, to avoid overfitting, a regularization term λn‖f‖2 is added to penalize the complexity of the estimated decision function f. Here, ‖f‖ is some norm of f, and λn is a tuning parameter. A high-level description of the proposed method is given in Algorithm 1 below. We consider both linear and nonlinear decision functions f when solving (7). For a linear decision function, f(x) = θ0 + θT x and we let ‖f‖ be the Euclidean norm of θ. For nonlinear decision functions, we employ a universal kernel function , such as the Gaussian kernel, which is continuous, symmetric and positive semidefinite. The optimization problem is then equivalent to a dual problem that maximizes
subject to 0 ≤ αi ≤ γWi/πi and , where Wi is the numerator in either (5) or (6) and πi is the respective denominator. Both settings can be efficiently solved by quadratic programming. For further details regarding solving weighted classification problems using support vector machines, we refer to [23, 26, 5].
Algorithm 1: Pseudo algorithm for the proposed method
Step 1. Use to fit recursively imputed survival trees. Obtain the estimation for reward R1 or the estimation for reward R2.
Step 2. Let the weights Wi be either or , depending on which of the two proposed approaches is used. Minimize the following weighted misclassification error:
| (7) |
Step 3. Output the estimated optimal treatment rule .
3. Theoretical results
3.1. Preliminaries
The risk function is defined as
where the reward R = R1 = E(T|X, A) for the first approach, or R = R2 = δY + (1 − δ)E(T|X, A, T > Y,Y) for the second one. We define ϕ-risk for both the true and the working model as, respectively, Rϕ(f) = E[Rϕ{Af(X)}/π(A; X)] and , where is the estimated value of R based on one of the two proposed methods. We also define the hinge loss function for the true and working models as Lϕ(f) = Rϕ{Af(X)}/π(A; X) and , respectively.
The proposed estimator , where is solved by one of the following optimization problems within some reproducible kernel Hilbert space :
or
3.2. Consistency of tree-based survival models
In this section, we provide the convergence bound of a simplified tree-based survival model, which is very close to the original algorithm in [28]. The purpose of this section and its main result, Theorem 1, is to demonstrate the existence of an accurate estimator of the underlying hazard function when tree-based methods are used. An earlier result developed in [10] considers only categorical feature variables. To the best of our knowledge, what we present below is the first consistency result for a tree-based survival model under general settings with restrictions only on the splitting rules, which is interesting in its own right.
For simplicity, we assume in this section that is the training sample, where Xi is independent uniformly distributed on [0, 1]d. The result can be easily generated to distributions with bounded support and density function bounded above and below. For any fixed x, our goal is to estimate the cumulative hazard function of failure time r(·, X, A) = ΛT (·|X, A); hereinafter, we write it as Λ(·|X, A).
A random forest is a collection of randomized regression trees , where m is the number of trees. The randomizing variable Θ is used to indicate how the successive cuts are performed when an individual tree is built. Hence the forest version of the survival tree model can be expressed as
Here, we consider a simplified scenario in which the selection of the coordinate is completely random and independent from the training data [1]. We only consider the consistency of a single tree and denote our tree estimator as . The result can be easily extended to the situation where m is finite.
A brief description of how each individual tree is constructed is provided in the appendix. Here we highlight some key assumptions and the main result. Our first assumption puts a lower bound on the probability of observing a failure at τ, and the second one assumes the smoothness of the hazard and cumulative hazard functions.
Assumption 1
For some M > 0, SY (τ|X, A) > M almost surely.
Assumption 2
For any fixed time point t and treatment decision A, the cumulative hazard function Λ(t | X, A) is L-Lipschitz continuous in terms of X, and the hazard function λ(t | X, A) is L′-Lipschitz continuous in terms of X, i.e., |Λ(t|X1, A) − Λ(t|X2, A)| ≤ L‖X1 − X2‖ and |λ(t|X1, A) − λ(t|X2, A) ≤ L′‖X1 − X2‖, respectively, where ‖·‖ is the Euclidean norm.
The following theorem provides the bound of the proposed tree based survival model for each X. Details of the proof are collected in the Appendix.
Theorem 1
Assume that Assumptions 1–2 and the construction of a tree-based survival model described in the Appendix. Further assume that kn → ∞ and n/kn → ∞ as n → ∞, where kn is a tuning parameter denoting the number of terminal nodes. For any b = nζ, where ζ > 0, we have for each X,
where r, u ∈ (0, 1), n ≥ 288b/M4, C is some universal constant, and
The ideal balance happens when . In this case, the optimal rate of the bound is close to . The following theorem proves consistency of the proposed tree based survival model. Details of the proof are collected in the Appendix.
Theorem 2
Assume that Assumptions 1–2 and the construction of a tree-based survival model described in the Appendix. Further assume that kn = nη, where 0 < η < 1. Then the estimator of the survival tree model is consistent. Moreover, for any b = nζ, where ζ > 0,
where r,u ∈ (0,1), n ≥ 288b/M4, C is some universal constant, and
3.3. Consistency and Excess Value Bound
Fisher consistency follows directly from Proposition 3.1 in [23], hence the proof is omitted. Here we restate the result as the following lemma. For the proposed method, we simply replace the reward R in Rϕ(f) with R1 or R2. Note that both versions are equivalent to the reward function Rϕ(f) = E[Tϕ{Af(X)}/π(A; X)]:
Lemma 1 (Proposition 3.1 in [23])
For any measurable function , if minimizes Rϕ(f), then .
Provided the Assumptions in Section 3.2 hold, the following lemma ensures the convergence of the estimated conditional expectations. The proof is given in Appendix.
Lemma 2
Based on Theorem 1, for each X the estimated conditional expectations converge in probability, i.e.,
for some constant C1, C2 (depending on L, L′, τ, M, d).
We will use the above lemmas to prove our main theorem based on the Gaussian kernel. Before we derive the convergence rate and excess value bound, we define the value function corresponding to the true and working model as V (f) = E(RI[A = sign{f(X)}]/π(A; X)) and , respectively. We further define the empirical L2–norm, , which also defines an ε-ball based on this norm. By Theorem 2.1 in [20], we restate the bound for covering numbers:
Lemma 3 (Theorem 2.1 in [20])
For any β > 0, 0 < v < 2, ε > 0 we have , where is the closed unit ball of , and d is the dimension of .
Lastly, for , we define the approximation error function
Then we have following theorem, the proof of which is given in Appendix.
Theorem 3
Based on Theorem 2 and assuming that the sequence λn > 0 satisfies λn → 0 and λn ln n → ∞, we have that
where f* maximize the true value function V, , and ρ > 0 for both methods; also, Mv is a constant depending on v, K is a sufficiently large positive constant, and C is a some large constant depending on d.
The rate consists of two parts. The first part is from the approximation error using . The second part controls the approximation error due to using the proposed tree-based method to estimate the conditional expectation.
4. Simulation studies
We perform simulation studies to compare the proposed method with existing alternatives, including the Cox proportional hazards model with covariate-treatment interactions, inverse censoring weighted outcome weighted learning, and doubly robust learning, both proposed in [26]. We use survival time on the log scale log(T) as outcome. We also present for comparison an “oracle” approach which uses the true failure time on the log scale log(T) as the weight in outcome weighted learning, although this would not be implementable in practice. However, this approach is a representation of the best possible performance under the outcome weighted learning framework.
We generate Xi’s independently from a uniform distribution. Treatments are generated from {+1, −1} with equal probabilities. We present four scenarios in this simulation study. The failure time T and censoring time C are generated differently in each scenario, including both linear and nonlinear decision rules. For each case, we learn the optimal treatment rule from a training dataset with sample size n = 200. A testing dataset with size 10000 is used to calculate the value function under the estimated rule. Each simulation is repeated 500 times.
Tuning parameters in the tree based methods need to be selected. We mostly use the default values. The number of variables considered at each split is the integer part of the square root of d as suggested by [11] and [7]. We set the total number of trees to be 50 as suggested by [28] and use one fold imputation. For the alternative approaches such as inverse censoring weighted outcome weighted learning and doubly robust learning, a Cox proportional hazards model with covariates (X, A, XA) is used to model T and C respectively. Note that when at least one of the two working models is correctly specified, the doubly robust method enjoys consistency. We implemented outcome weighted learning using a Matlab library for support vector machine [5]. Both linear and Gaussian kernels are considered for all methods except for the Cox model approach which could be directly inverted to obtain the decision rules. The parameter λn is chosen by ten-fold cross-validation.
4.1. Simulation settings
For all scenarios, we generate and C independently. The failure time . For all accelerated failure time models, ε is generated from a standard normal distribution. For all Cox proportional hazards models, the baseline hazard function λ0(t) = 2t. For all simulation results presented in this section, we consider setting the censoring rates to approximately 45% for all scenarios. We also perform a sensitivity analysis for different censoring rates (30% and 60%) for each scenario. These additional results are presented in the Appendix.
Scenario 1
Both and C are generated from the accelerated failure time model. τ = 2.5 and d = 10. The optimal decision function is linear. The value of the optimal treatment rule is approximately 0.031:
Scenario 2
is generated from a Cox model and C is generated from the accelerated failure time model. The optimal decision function is nonlinear. τ = 8 and d = 10. The value of the optimal treatment rule is approximately 0.181:
Scenario 3
is generated from an accelerated failure time model with tree structured effects. C is generated from a Cox model with nonlinear effects. τ = 8 and d = 5. The value of the optimal treatment rule is approximately 1.079:
Scenario 4
is is generated from an accelerated failure time model. C is generated from a Cox model. τ = 2 and d = 10. The value of the optimal treatment rule is approximately −0.389:
4.2. Simulation results
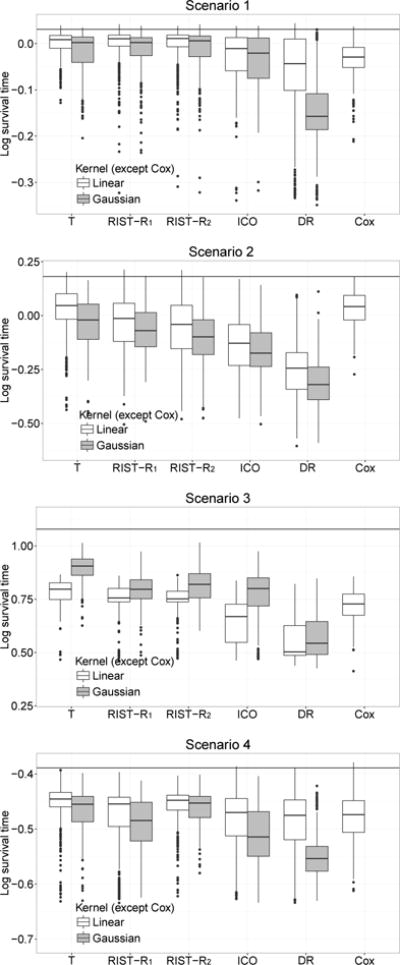
Figure 1 shows the boxplot of values based on the logarithm of T calculated from the test data. The mean and standard deviation of values are shown in Table 1. In scenario 1, since the model is not correctly specified for inverse probability of censoring outcome weighted learning, the doubly robust estimator, or Cox regression, our method performs better than all other competitors.
Fig 1.
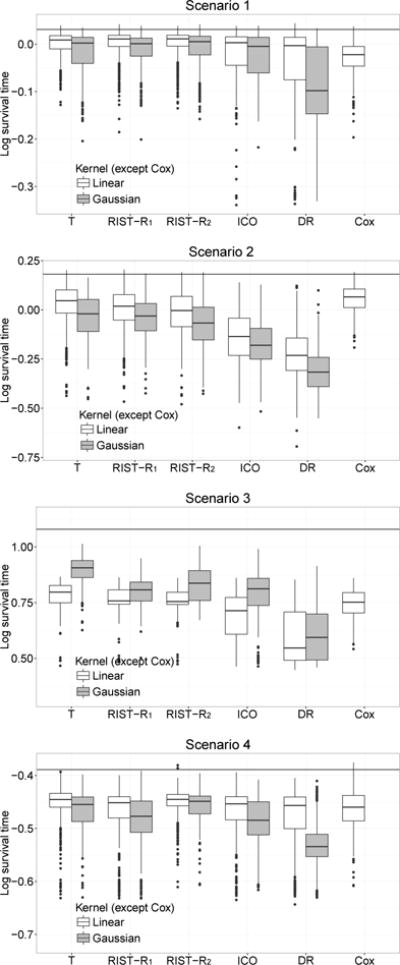
Boxplots of mean log survival time for different treatment regimes. Censoring rate: 45%. T: using true survival time as weight; RIST-R1 and RIST-R2: using the estimated R1 and R2 respectively as weights, while the conditional expectations are estimated using recursively imputed survival trees; ICO: inverse probability of censoring weighted learning; DR: doubly robust outcome weighted learning. The black horizontal line is the theoretical optimal value.
Table 1.
Simulation results: Mean (×103) and (sd) (×103). Censoring rate: 45%. For each scenario, the theoretical optimal value (×103) is 31, 181, 1079, and −389, respectively.
| kernel | T | RIST-R1 | RIST-R2 | ICO | DR | Cox | |
|---|---|---|---|---|---|---|---|
| 1 | Linear | 0 (26) | 0 (31) | 1 (30) | −20 (54) | −39 (76) | −29 (33) |
| Gaussian | −17 (44) | −11 (35) | −8 (36) | −25 (50) | −88 (79) | ||
| 2 | Linear | 22 (113) | −1 (112) | −24 (125) | −137 (131) | −232 (132) | 53 (69) |
| Gaussian | −39 (115) | −40 (103) | −72 (114) | −175 (120) | −311 (106) | ||
| 3 | Linear | 785 (52) | 766 (59) | 763 (51) | 683 (113) | 598 (120) | 745 (64) |
| Gaussian | 896 (61) | 803 (56) | 834 (71) | 785 (105) | 606 (115) | ||
| 4 | Linear | −453 (37) | −469 (47) | −451 (27) | −469 (48) | −481 (59) | −464 (36) |
| Gaussian | −465 (35) | −482 (44) | −457 (28) | −487 (45) | −531 (43) |
T: using true survival time as weight; RIST-R1 and RIST-R2: using the estimated R1 and R2 respectively as weights, while the conditional expectations are estimated using recursively imputed survival trees; ICO: inverse probability of censoring weighted learning; DR: doubly robust outcome weighted learning; Cox: Cox proportional hazards model using covariate-treatment interactions.
In scenario 2, we added some nonlinear terms into both the Cox and accelerated failure time models. The model assumptions for inverse censoring outcome weighted learning and the doubly robust estimator are not satisfied. Our estimated treatment rule performs much better than these two. Compared with inverse censoring outcome weighted learning and doubly robust learning, both our approaches improve more than 0.1 for the mean. Since the true model for the failure time is the Cox model, Cox regression performs better here. In this case, the Gaussian kernel performs less well than the linear kernel for most methods since the true model structure is linear and the Gaussian kernel is too flexible.
For scenario 3, which has a more complicated tree structure, the Gaussian kernel performs better than the linear kernel for all outcome weighted learning approaches. The performance of the Gaussian kernel is enhanced since it can better address the true nonlinear model structure. We can see that with either a linear or Gaussian kernel, our estimators perform better than Cox regression. Compared with doubly robust learning, our two approaches improve 0.2 for the mean.
In scenario 4, we see that when the model is correctly specified for inverse probability of censoring outcome weighted learning and doubly robust learning, the performances of both approaches are satisfactory while our methods seem to be only a little better. The performances of our first approach, inverse probability of censoring outcome weighted learning and Cox regression are all similar. Our second approach has the best treatment effect among all estimators. Note that our second approach appears to perform as well as the first, oracle approach. Also, our two proposed methods have smaller standard errors in scenarios 1 and 3. The standard error is similar for all outcome weighted learning approaches in scenario 2 and 4. Overall, our proposed methods have generally lower variances.
Compared with results of censoring rates (30% and 60%) in the Appendix, we can observed a consistently pattern that lower censoring rate leads to higher performances in terms of both mean value and variance. The relative performances between the proposed and the competing methods remain similar across different censoring rates.
5. Data Analysis
We apply the proposed method to a non-small-cell lung cancer randomized trial dataset described in [19]. 228 subjects with complete information are used in this analysis. Each treatment arm contains 114 subjects. The censoring rate is 29%. Here we use five covariates: performance status (119 subjects ranging from 90% to 100% and 109 subjects ranging from 70% to 80%), cancer stage (31 subjects in stage 3 and 197 subjects in stage 4), race (167 white, 54 black and 7 others), gender (143 male and 85 female), age (ranging from 31 to 82 with median 63). The length of study is τ = 104 weeks. We adopt the same tuning parameters used in the simulation study for this analysis. The value function is again calculated by using the logarithm of survival time log(T) (in weeks) as the reward.
We randomly divide the 228 patients into four equal proportions and use three parts as training data to estimate the optimal rule and calculate the empirical value based on the remaining part. We then permute the training and testing portions and average the four results. This procedure is then repeated 100 times and averaged to obtain the mean and standard deviation. To calculate the testing data performance, we consider two different measurements, both are calculated based on the formula for the testing samples, where two versions of Ri’s are used. We first consider the procedure proposed in [26], where R is defined as
Here, and are estimated from the Cox model for simplicity. We also consider a more direct clinical measurement without the double robustness correction, which can be interpreted in a similar way as the expected survival time or the restricted mean survival time [6, 16, 21]. To be specific, we consider a restricted mean (log) survival time truncated at τ defined as δT + (1 − δ)E(T), and use this as a plug-in quantity of R in the testing performance calculation. To estimate this quantity, we use a recursively imputed survival trees (RIST) method to produce the expected survival time E(T). The results are presented in Tables 2 and 3 and Figures 2 and 3.
Table 2.
Analysis of non-small-cell lung cancer data: Mean (standard deviation) of value function
| kernel | RIST-R1 | RIST-R2 | ICO | DR | Cox |
|---|---|---|---|---|---|
| Linear | 3.641 (0.144) | 3.641 (0.138) | 3.633 (0.158) | 3.590 (0.174) | 3.582 (0.158) |
| Gaussian | 3.611 (0.215) | 3.615 (0.220) | 3.302 (0.221) | 3.470 (0.233) |
RIST-R1 and RIST-R2: using the estimated R1 and R2 respectively as weights, while the conditional expectations are estimated using recursively imputed survival trees; ICO: inverse probability of censoring weighted learning; DR: doubly robust outcome weighted learning; Cox: Cox proportional hazards model using covariate-treatment interactions.
Table 3.
Analysis of non-small-cell lung cancer data: Mean (standard deviation) of a clinical measure
| kernel | RIST-R1 | RIST-R2 | ICO | DR | Cox |
|---|---|---|---|---|---|
| Linear | 3.603 (0.040) | 3.606 (0.037) | 3.598 (0.037) | 3.601 (0.042) | 3.646 (0.039) |
| Gaussian | 3.511 (0.064) | 3.514 (0.068) | 3.451 (0.062) | 3.456 (0.052) |
RIST-R1 and RIST-R2: using the estimated R1 and R2 respectively as weights, while the conditional expectations are estimated using recursively imputed survival trees; ICO: inverse probability of censoring weighted learning; DR: doubly robust outcome weighted learning; Cox: Cox proportional hazards model using covariate-treatment interactions.
Fig 2.
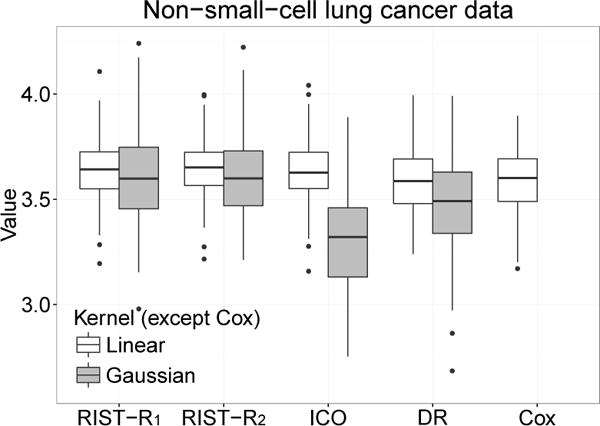
Boxplots of cross-validated value of survival weeks on the log scale. RIST-R1 and RIST-R2: using the estimated R1 and R2 respectively as weights, while the conditional expectations are estimated using recursively imputed survival trees; ICO: inverse probability of censoring weighted learning; DR: doubly robust outcome weighted learning.
Fig 3.
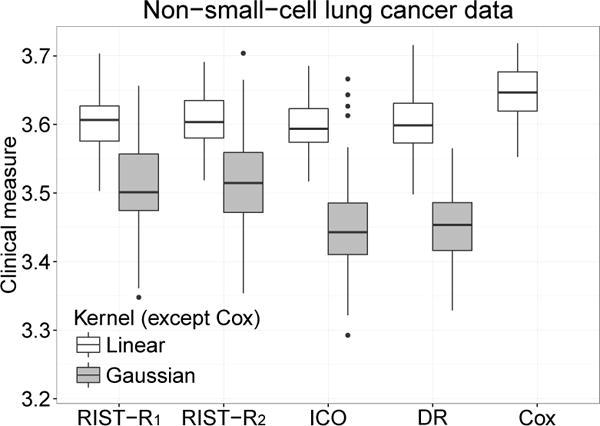
Boxplots of cross-validated value of survival weeks on the log scale. RIST-R1 and RIST-R2: using the estimated R1 and R2 respectively as weights, while the conditional expectations are estimated using recursively imputed survival trees; ICO: inverse probability of censoring weighted learning; DR: doubly robust outcome weighted learning.
The value function results are presented in Table 2 and Figure 2. Both proposed methods have higher values than the compared methods. Note that for the Gaussian kernel, our two new approaches are still better than Cox regression, however, inverse probability of censoring outcome weighted learning and doubly robust learning are not much different from Cox regression. The standard error is comparable among all four methods using the linear kernel. For the Gaussian kernel, the standard errors of the proposed methods and inverse probability of censoring weighted learning are similar. The standard error for the doubly robust method is slightly worse in this instance. Overall, the proposed methods seem to perform best.
The restricted log mean results are presented in Table 3 and Figure 3. Note for the linear kernel, the median of the proposed methods are higher than 3.6 and median of both inverse probability of censoring outcome weighted learning and doubly robust learning are lower. For the Gaussian kernel, the proposed methods are much better than inverse probability of censoring outcome weighted learning and doubly robust learning. Interestingly, under this measure, the performance of Cox regression is the best. A possible reason is that the true underlying model may not deviate much from the proportional hazard model, making the Cox model a better choice. This is also reflected by the fact that the results look similar to the simulation Scenario 2 plot, where the Cox model performs the best. Another possible reason is that the pseudo-outcome estimated from RIST may not be completely accurate and favors the Cox model in this particular dataset.
6. Discussion
We proposed a new method that redefines the reward function in a censored survival setting. The method works by replacing the censored observations (or all observations) by an estimated conditional expectation of the failure time. In practice, the failure time (or logarithm of the failure time) is commonly used in defining the reward function R, however, this choice could more flexible. For example, we may be interested in searching for a treatment rule that maximizes the median survival time or a certain quantile. Under our framework, this is achievable by replacing the censored observations with a suitable estimate of the quantile. This part of the work is currently under investigation.
The proposed methods may be improved or extended in multiple ways. The estimated treatment rule may be affected by the shift of the outcome. A potential extension is to combine our methods with residual weighted learning [27], which has been shown to reduce the total variation of the weights and improve stability. Trials with multiple treatment arms occur frequently. Thus a potential extension of our method is in the direction of multicategory classification [2, 15]. It is also interesting to extend our method to dynamic treatment regimes where a sequence of decision rules [17, 24, 13, 25] need to be learned in a censored survival outcome setting [8].
Acknowledgments
This research is supported in part by U.S. National Science Foundation grant DMS-1407732 and by U.S. National Institutes of Health grant P01 CA142538. We thank Yinqi Zhao for helpful conversations and suggestions. We thank the editor, associated editor, and reviewers for helpful comments which led to an improved manuscript.
Appendix
A simplified tree-based survival model used in Theorem 1
We consider a simplified version of a tree-based survival model. Starting from the root node [0, 1]d, at each internal node, we randomly chose the j-th feature of X to split the node, while the splitting point is always at the midpoint of the range of the chosen feature. We repeat splitting ⌈log2 kn⌉ times, where kn is a deterministic parameter which we can control. Hence, each individual tree has exactly terminal nodes, which is approximately kn. In practice, we always chose kn to go to infinity as n goes to infinity.
After we build an individual tree, let be the rectangular cell of the random partition. We treat observations inside each leaf node as a group of homogeneous subjects and compute the Nelson-Aalen estimator for each leaf node Bi. Hence, our estimator is essentially
Proof of Theorem 1
Proof
Since we always assume that the treatment variable A is important, and A has only two categories, we force a split on A at the root node. This is equivalent to fitting trees for A = 1 and A = −1 separately. In a balanced design, the problem reduces to estimating or with sample size n/2. Without the risk of ambiguities, the following results are developed for with sample size n, where the results can be applied to either A = 1 or −1. Our proof utilizes two facts from [1]:
Fact 1 Let Knj{Bi} be the number of times the j-th coordinate (j = 1, …, d) is split on to reach the terminal node Bi, . Conditionally on X, Knj{Bi} is Binomial(⌈log2kn⌉, 1/d). Moreover, .
Fact 2 Let Nn(Bi) be the number of data points falling in the cell Bi, . Conditionally on Θ, Nn(Bi) follows .
The following lemma, for later reference, provides the deterministic limit of the Nelson-Aalen estimator in the independent non-identically distributed case. The proof can be found in an unpublished technical report by Mai Zhou at the University of Kentucky.
Lemma 4
Suppose we have two sets of non-negative random variables: T1, T2, …, Tn which are survival times, independent but non-identically distributed with continuous distribution F1(t), F2(t), …, Fn(t); C1, C2, …, Cn which are censoring times, independent but non-identically distributed with continuous distribution G1(t), G2(t), …, Gn(t). We also assume the and are independent. The Nelson-Aalen estimator of data Yi = min(Ti, Ci), δi = I(Ti ≤ Ci) is . Provided Assumption 1, for b = nζ, where ζ > 0,
| (8) |
Now we start the proof of Theorem 1. Let the limit of the Nelson-Aalen estimator inside the cell Bi, be
For any t < τ, in order to bound the , we define
Then can be decomposed as
| (9) |
We start with the first term in Equation (9). From Fact 2, we know the number of observations in each terminal node is . By the Chernoff bound, with probability larger than , in one terminal node we have at least observations for some 0 < u < 1.
Combining Equation (8), with probability larger than , the following equation holds:
| (10) |
| (11) |
Before we bound the second term in Equation (9). We first show the bound for the difference between the true cumulative hazard function and aggregated estimator inside the cell Bi, , i.e. |I {X ∈ Bi}{Λ*(t| Bi) − Λ(t|X)}.
From Fact 1, we know the number of times the terminal node Bi is split on the j-th coordinate (j = 1, ⋯, d) Knj{Bi} is Binomial(⌈log2kn⌉, 1/d). By the Chernoff bound, for some 0 < r < 1. So with probability , every dimension of Bi is less than . So with probability larger than , for arbitrary i, , we have
So for all the observations Xj inside the same cell as X, by Assumption 2, we have
where fX(·) and FX(·) denote the true density function and distribution function at X, respectively. Then Λ*(t | Bi) has the upper bound and lower bound
respectively, where
Hence, |I{X ∈ Bi}{Λ*(t | Bi) − Λ(t | X)}| has the bound
where C is some constant depending on L and L′. We then bound the second term of Equation (9) as follows:
| (12) |
Combining Equation (10) and (12), For each X, we have
where
This completes the proof. □
Proof of Theorem 2
Proof
Based on Theorem 1, we now only need to establish the bound of under the event with small probability wn. Noticing that is simply the Nelson-Aalen estimator of the cumulative hazard function with at most n terms, for any t < τ we have
which implies that
Combining this with Theorem 1 completes the proof. □
Proof of Lemma 2
Proof
Our survival function estimator is . From Theorem 1, we know that for any t < τ,
It is then easy to see that for R1,
with probability larger than 1 − wn. And for reward R2, we have
Note that we can bound the distance between and S(Y|X, A) with probability no less than 1 − wn, which is further bounded above by
for some constant C2 with probability larger than 1 − 2wn. □
Proof of Theorem 3
Proof
We restate the value function corresponding to the true and working model as
respectively. Then we have
| (13) |
We start with the first term in Equation (13). From Lemma 1, we know that , where .
Let , then
| (14) |
By the definition of a(λ), we have
and by Theorem 3.2 in [23], we further have
Combined with (14),
Since
and the estimated value function is bounded by τ, we know that . Furthermore, since
we have . Combining with Lemma 2, (I) and (II) are bounded by for both R1 and R2, where C1 is some constant. Following the results in [26], (III) is bounded by with probability larger than 1 − 2e−ρ, where Mv is a constant depending on v and K is a sufficiently large positive constant. Finally, combining (I), (II) and (III), we have
| (15) |
where .
For the second part in Equation (13),
if R = R1. For R = R2, we have
By Lemma 2,
| (16) |
where C2 is some constant. Now, combining (15) and (16) we have
where
This completes the proof. □
Additional simulation results for different censoring rates
We summarize the additional simulation results in this section. For each simulation scenario considered in Section 4, we alter the first constant term in the censoring distribution to achieve 30% (Table 4 and Figure 4), and 60% (Table 5 and Figure 5) censoring rates.
Table 4.
Simulation results: Mean (×103) and (sd) (×103). Censoring rate: 30%. For each scenario, the theoretical optimal value (×103) is 31, 181, 1079, and −389, respectively.
| kernel | T | RIST-R1 | RIST-R2 | ICO | DR | Cox | |
|---|---|---|---|---|---|---|---|
| 1 | Linear | 0 (26) | 1 (31) | 2 (28) | −10 (40) | −20 (63) | −26 (33) |
| Gaussian | −17 (44) | −10 (34) | −7 (37) | −18 (45) | −48 (65) | ||
| 2 | Linear | 22 (113) | 17 (105) | −14 (126) | −110 (136) | −193 (133) | 65 (63) |
| Gaussian | −39 (115) | −25 (101) | −62 (113) | −164 (119) | −285 (112) | ||
| 3 | Linear | 785 (52) | 768 (53) | 771 (52) | 737 (95) | 667 (124) | 763 (61) |
| Gaussian | 896 (61) | 810 (54) | 854 (69) | 817 (124) | 679 (123) | ||
| 4 | Linear | −453 (37) | −465 (46) | −448 (27) | −461 (42) | −471 (54) | −457 (32) |
| Gaussian | −465 (35) | −477 (42) | −456 (27) | −474 (41) | −505 (48) |
T: using true survival time as weight; RIST-R1 and RIST-R2: using the estimated R1 and R2 respectively as weights, while the conditional expectations are estimated using recursively imputed survival trees; ICO: inverse probability of censoring weighted learning; DR: doubly robust outcome weighted learning; Cox: Cox proportional hazards model using covariate-treatment interactions.
Fig 4.
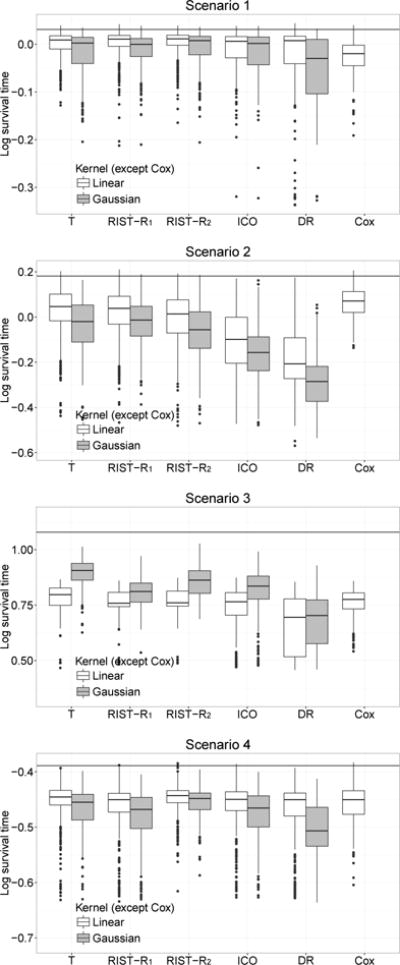
Boxplots of mean log survival time for different treatment regimes. Censoring rate: 30%. T: using true survival time as weight; RIST-R1 and RIST-R2: using the estimated R1 and R2 respectively as weights, while the conditional expectations are estimated using recursively imputed survival trees; ICO: inverse probability of censoring weighted learning; DR: doubly robust outcome weighted learning. The black horizontal line is the theoretical optimal value.
Table 5.
Simulation results: Mean (×103) and (sd) (×103). Censoring rate: 60%. For each scenario, the theoretical optimal value (×103) is 31, 181, 1079, and −389, respectively.
| kernel | T | RIST-R1 | RIST-R2 | ICO | DR | Cox | |
|---|---|---|---|---|---|---|---|
| 1 | Linear | 0 (26) | −2 (39) | −5 (43) | −29 (57) | −64 (92) | −34 (36) |
| Gaussian | −17 (44) | −12 (40) | −12 (45) | −35 (55) | −144 (78) | ||
| 2 | Linear | 22 (113) | −36 (123) | −61 (135) | −138 (133) | −248 (129) | 31 (79) |
| Gaussian | −39 (115) | −69 (108) | −102 (115) | −165 (117) | −313 (101) | ||
| 3 | Linear | 785 (52) | 753 (77) | 748 (69) | 646 (104) | 556 (94) | 721 (70) |
| Gaussian | 896 (61) | 796 (63) | 819 (67) | 775 (106) | 573 (93) | ||
| 4 | Linear | −453 (37) | −478 (55) | −458 (33) | −486 (55) | −492 (59) | −480 (43) |
| Gaussian | −465 (35) | −492 (48) | −461 (29) | −513 (53) | −551 (38) |
T: using true survival time as weight; RIST-R1 and RIST-R2: using the estimated R1 and R2 respectively as weights, while the conditional expectations are estimated using recursively imputed survival trees; ICO: inverse probability of censoring weighted learning; DR: doubly robust outcome weighted learning; Cox: Cox proportional hazards model using covariate-treatment interactions.
Fig 5.
Boxplots of mean log survival time for different treatment regimes. Censoring rate: 60%. T: using true survival time as weight; RIST-R1 and RIST-R2: using the estimated R1 and R2 respectively as weights, while the conditional expectations are estimated using recursively imputed survival trees; ICO: inverse probability of censoring weighted learning; DR: doubly robust outcome weighted learning. The black horizontal line is the theoretical optimal value.
Contributor Information
Yifan Cui, Department of Statistics and Operations Research, University of North Carolina at Chapel Hill, Chapel Hill, NC 27599, USA.
Ruoqing Zhu, Department of Statistics, University of Illinois at Urbana-Champaign, Champaign, IL 61820, USA.
Michael Kosorok, Department of Biostatistics and Department of Statistics and Operations Research, University of North Carolina at Chapel Hill, Chapel Hill, NC 27599, USA.
References
- 1.Biau G. Analysis of a random forests model. Journal of Machine Learning Research. 2012;13:1063–1095. [Google Scholar]
- 2.Bredensteiner EJ, Bennett KP. Computational Optimization. Springer; 1999. Multicategory classification by support vector machines; pp. 53–79. [Google Scholar]
- 3.Breiman L. Random forests. Machine learning. 2001;45:5–32. [Google Scholar]
- 4.Breiman L, Friedman J, Stone CJ, Olshen RA. Classification and regression trees. CRC press; 1984. [Google Scholar]
- 5.Chang CC, Lin CJ. Libsvm: a library for support vector machines. ACM Transactions on Intelligent Systems and Technology (TIST) 2011;2:27. [Google Scholar]
- 6.Geng Y, Zhang HH, Lu W. On optimal treatment regimes selection for mean survival time. Statistics in medicine. 2015;34:1169–1184. doi: 10.1002/sim.6397. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Geurts P, Ernst D, Wehenkel L. Extremely randomized trees. Machine learning. 2006;63:3–42. [Google Scholar]
- 8.Goldberg Y, Kosorok MR. Q-learning with censored data. Annals of statistics. 2012;40:529. doi: 10.1214/12-AOS968. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Hothorn T, Lausen B, Benner A, Radespiel-Tröger M. Bagging survival trees. Statistics in medicine. 2004;23:77–91. doi: 10.1002/sim.1593. [DOI] [PubMed] [Google Scholar]
- 10.Ishwaran H, Kogalur UB. Consistency of random survival forests. Statistics & probability letters. 2010;80:1056–1064. doi: 10.1016/j.spl.2010.02.020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Ishwaran H, Kogalur UB, Blackstone EH, Lauer MS. Random survival forests. The annals of applied statistics. 2008:841–860. [Google Scholar]
- 12.Laber E, Zhao Y. Tree-based methods for individualized treatment regimes. Biometrika. 2015;102:501–514. doi: 10.1093/biomet/asv028. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Laber EB, Lizotte DJ, Qian M, Pelham WE, Murphy SA. Dynamic treatment regimes: Technical challenges and applications. Electronic journal of statistics. 2014;8:1225. doi: 10.1214/14-ejs920. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.LeBlanc M, Crowley J. Relative risk trees for censored survival data. Biometrics. 1992:411–425. [PubMed] [Google Scholar]
- 15.Lee Y, Lin Y, Wahba G. Multicategory support vector machines: Theory and application to the classification of microarray data and satellite radiance data. Journal of the American Statistical Association. 2004;99:67–81. [Google Scholar]
- 16.Ma J, Hobbs BP, Stingo FC. Statistical methods for establishing personalized treatment rules in oncology. BioMed research international. 2015:2015. doi: 10.1155/2015/670691. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Murphy SA. Optimal dynamic treatment regimes. Journal of the Royal Statistical Society: Series B (Statistical Methodology) 2003;65:331–355. [Google Scholar]
- 18.Qian M, Murphy SA. Performance guarantees for individualized treatment rules. Annals of statistics. 2011;39:1180. doi: 10.1214/10-AOS864. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Socinski MA, Schell MJ, Peterman A, Bakri K, Yates S, Gitten R, Unger P, Lee J, Lee JH, Tynan M, et al. Phase iii trial comparing a defined duration of therapy versus continuous therapy followed by second-line therapy in advanced-stage iiib/iv non–small-cell lung cancer. Journal of Clinical Oncology. 2002;20:1335–1343. doi: 10.1200/JCO.2002.20.5.1335. [DOI] [PubMed] [Google Scholar]
- 20.Steinwart I, Scovel C. Fast rates for support vector machines using gaussian kernels. The Annals of Statistics. 2007:575–607. [Google Scholar]
- 21.Tian L, Zhao L, Wei L. Predicting the restricted mean event time with the subject’s baseline covariates in survival analysis. Biostatistics. 2014;15:222–233. doi: 10.1093/biostatistics/kxt050. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Zhang B, Tsiatis AA, Laber EB, Davidian M. A robust method for estimating optimal treatment regimes. Biometrics. 2012;68:1010–1018. doi: 10.1111/j.1541-0420.2012.01763.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Zhao Y, Zeng D, Rush AJ, Kosorok MR. Estimating individualized treatment rules using outcome weighted learning. Journal of the American Statistical Association. 2012;107:1106–1118. doi: 10.1080/01621459.2012.695674. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Zhao Y, Zeng D, Socinski MA, Kosorok MR. Reinforcement learning strategies for clinical trials in nonsmall cell lung cancer. Biometrics. 2011;67:1422–1433. doi: 10.1111/j.1541-0420.2011.01572.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Zhao YQ, Zeng D, Laber EB, Kosorok MR. New statistical learning methods for estimating optimal dynamic treatment regimes. Journal of the American Statistical Association. 2015;110:583–598. doi: 10.1080/01621459.2014.937488. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Zhao YQ, Zeng D, Laber EB, Song R, Yuan M, Kosorok MR. Doubly robust learning for estimating individualized treatment with censored data. Biometrika. 2015;102:151–168. doi: 10.1093/biomet/asu050. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Zhou X, Mayer-Hamblett N, Khan U, Kosorok MR. Residual weighted learning for estimating individualized treatment rules. Journal of the American Statistical Association. 2015:00–00. doi: 10.1080/01621459.2015.1093947. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Zhu R, Kosorok MR. Recursively imputed survival trees. Journal of the American Statistical Association. 2012;107:331–340. doi: 10.1080/01621459.2011.637468. [DOI] [PMC free article] [PubMed] [Google Scholar]