
Figure 3. Consistency of reward and frames of reference.
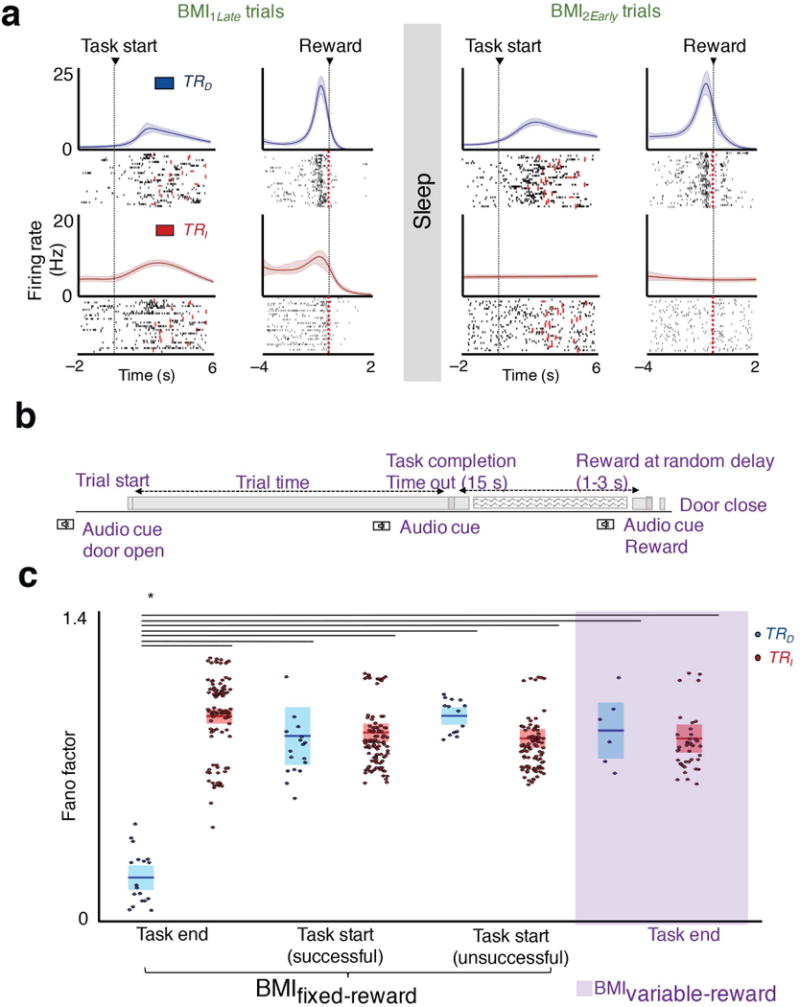
a, Neural firing centered to task start and task end/reward for the same session for regular BMI training (i.e. BMIfixed-reward). The lighter band is the jackknife error. b, Schematic of “variable-reward” BMI training. b, Schematic of variable-reward BMI trials. c, Average Fano factor of TRD and TRI neurons for the four sets of conditions, namely task-start (successful and unsuccessful trials are separately parsed) and task-end/reward frame in BMIfixed-reward, and task end in BMIvariable-reward (mean in solid line ± s.e.m. in box, task start and task end in BMIfixed-reward one-way ANOVA, F5,350 = 41.20, P < 10−32; task end in BMIfixed-reward and BMIvariable-reward one-way ANOVA, F3,166 = 83.86, P < 10−32, significant post hoc t tests, *P < 0.05).