
Figure 2.
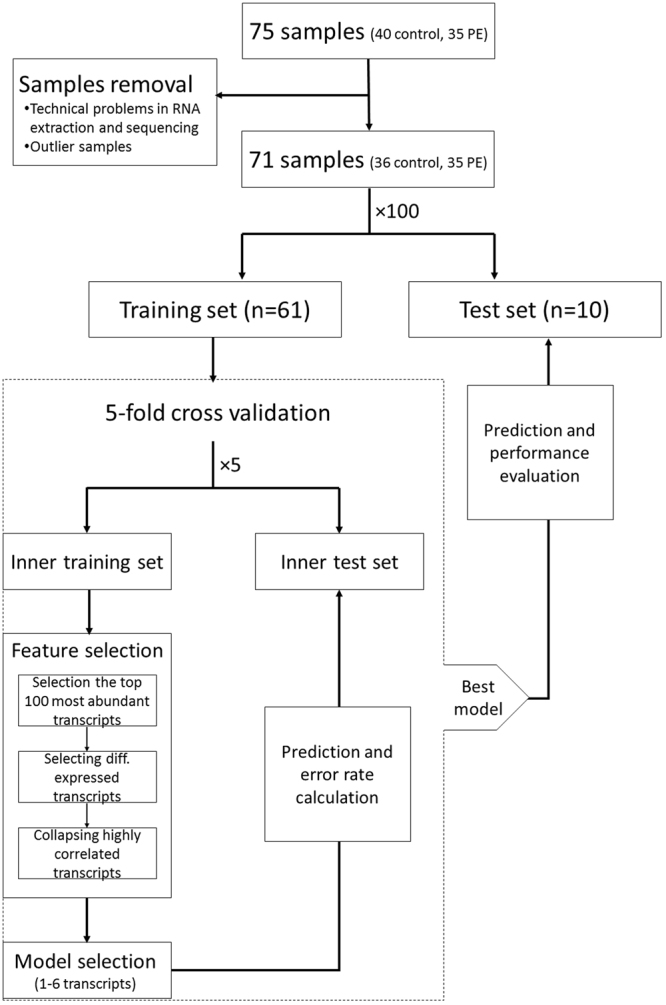
Schematic diagram of the workflow for PE/control samples classification. Data is randomly divided into a training set and a test set. 5-fold cross validation procedure is used on the training set to obtain a logistic regression model that best classifies training-set samples, and then it is tested on the blind test set. This process is repeated a 100 times, each time with a random partition to training and test set, in order to increase the stability and generalization of the results, and to estimate the goodness of the procedure on a new blind data set. The classification accuracy in the blind test set and related statistics are calculated in each of the iterations, and are summarized for overall evaluation of the pipeline.