
Fig. 2.
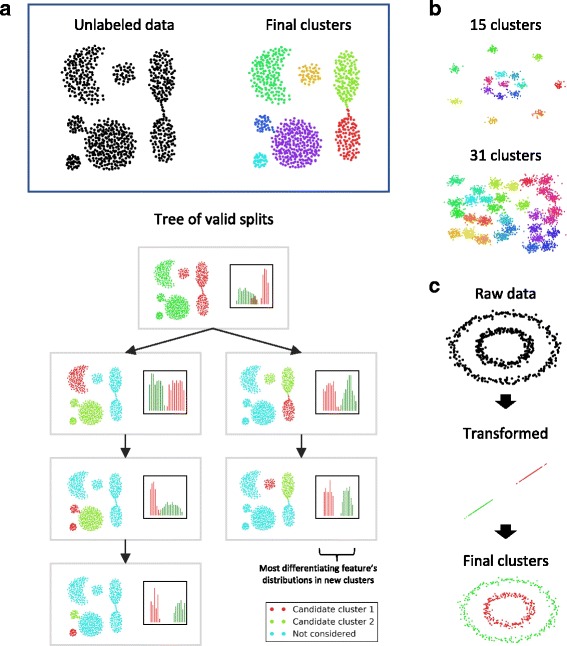
Synthetic Datasets. a The DendroSplit approach is applied to a synthetic 2-dimensional dataset where pairwise distances are equal to the Euclidean distances between points. The dendrogram splitting process can be visualized using a tree, and each box in the tree represents a step in the algorithm where a larger cluster is partitioned into the red and green clusters. For each of the two features (dimensions), the split is evaluated based on the distributions of that feature within the candidate clusters. Teal points are “background” points and not considered for a given step. b DendroSplit is evaluated on two other 2-dimensional synthetic datasets and recovers the correct number of clusters both times. Euclidean distance is used. c We note that DendroSplit cannot overcome poor preprocessing and distance metric selection. Directly computing Euclidean distances for the points in the concentric circle dataset would yield poor performance, but using Euclidean distance after some preprocessing (e.g. mapping each point to its distance from the center) yields the correct results. For the examples shown here, the merge thresholds are 10, and the split thresholds are 40 for (a) and 30 for (b, c)