
Figure 1. Task structure and trial types.
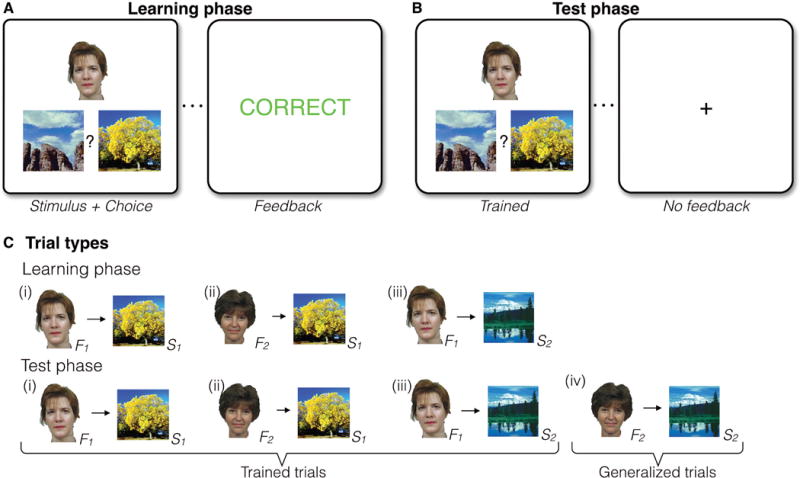
(A) In the Learning phase, participants learned a series of individual face-scene associations based on feedback (12 individual associations in total). A face-scene pair was presented on each trial, followed by performance-dependent feedback. (B) The Learning phase was followed by a Test phase, where participants received no feedback and were asked to respond to both previously experienced (Trained) trials and novel untrained face-scene association (Generalized) trials. (C) The Learning phase had three event types: Individual associations shared overlapping features such that two faces always were associated with a common scene (i and ii), and one of those faces was also associated with a second scene (iii). A scene that was the incorrect choice for one face was the correct choice for another face, such that simple stimulus-response learning strategies could not support learning. In the Test phase, novel associations (iv, Generalized trials) were presented intermixed with trials that tested knowledge for previously trained associations (Trained trials).