
Fig. 2.
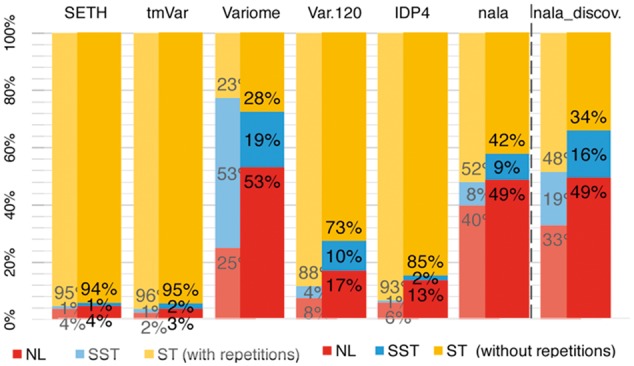
Natural language (NL) mutation mentions important. What type of mutation mentions dominates annotated corpora that somehow sample the literature: standard (ST, e.g. E6V), semi-standard (SST), or natural language (NL)? Grayed out bars indicate counts with repetitions, full bars unique mentions (e.g. E6V occurring twice in the same paper, is counted twice for the grayed out values and only once per paper for the others). The Variome, Variome120, IDP4 and nala_discoveries corpora assembled different representations of NL mentions. The dashed line separates corpora with papers describing well-known, well-indexed genes and proteins (left of dashed line: SETH, tmVar, Variome, Variome120, IDP4 and nala_known) and articles describing more recent discoveries that still have to be indexed in databases (right of dashed line: nala_discoveries) (Color version of this figure is available at Bioinformatics online.)