
Figure 1.
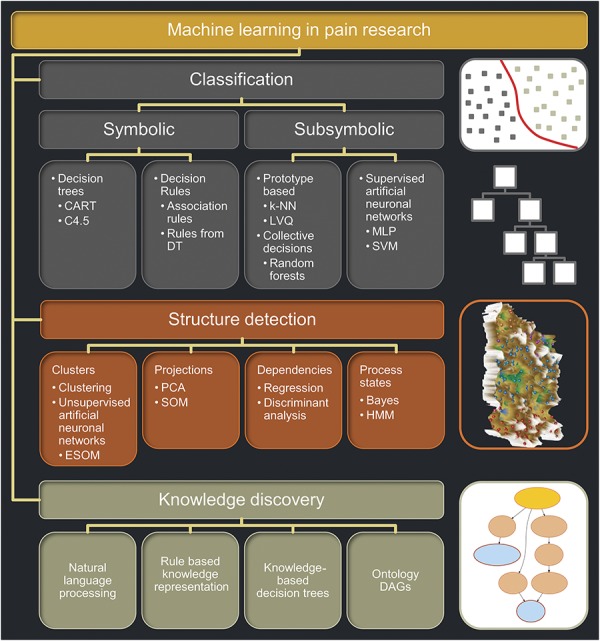
Overview and classification of machine learning methods, selected for their use in a pain research context. The figure structures machine learning for its main uses comprising (1) classification tasks used for example to obtain a clinical diagnosis, (2) data structure detection including the identification of clusters, and (3) knowledge discovery in experimental or clinical data or in large databases structured hierarchically such as ontologies. Short descriptions of key methods are provided in Box 1. The icons at the right of each main application field symbolize respective typical machine learning methods, that is, from top to bottom: (1) SVM where the grouping (classification) is obtained by placing a border (hyperplane) between classes (subsymbolic classifier), (2) a decision tree where the classification is obtained through hierarchical rules (symbolic classifier), (3) an emergent self-organizing maps as an unsupervised machine learning method able to find an interesting structure in high-dimensional data such as clusters. In this figure, the map was colored using a geographical analogy with brown (up to snow-covered) heights and green valleys, on which clusters can be separated (from Ref. 36). Finally, (4) a directed acyclic graph is drafted depicting the polyhierarchy of, for example, the functions of pain-relevant genes (from Ref. 69). CART, classification and regression tree; DAG, directed acyclic graph; DT, decision tree; ESOM, emergent self-organizing map; HMM, hidden Markov models; k-NN, k nearest neighbor; LVQ, learning vector quantization; MLP, multilayer perceptron; PCA, principal component analysis; SVM, support vector machine.