
Figure 4.
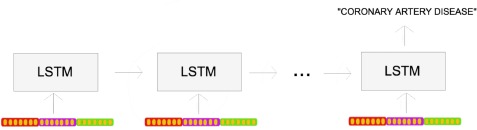
The many-to-one prediction task for the LSTM, in which a document representation is fed in at eachtimestep, and it makes a prediction (e.g. diagnosis) at the end of the sequence.
Official websites use .gov
A
.gov website belongs to an official
government organization in the United States.
Secure .gov websites use HTTPS
A lock (
) or https:// means you've safely
connected to the .gov website. Share sensitive
information only on official, secure websites.
The many-to-one prediction task for the LSTM, in which a document representation is fed in at eachtimestep, and it makes a prediction (e.g. diagnosis) at the end of the sequence.