
FIGURE 2.
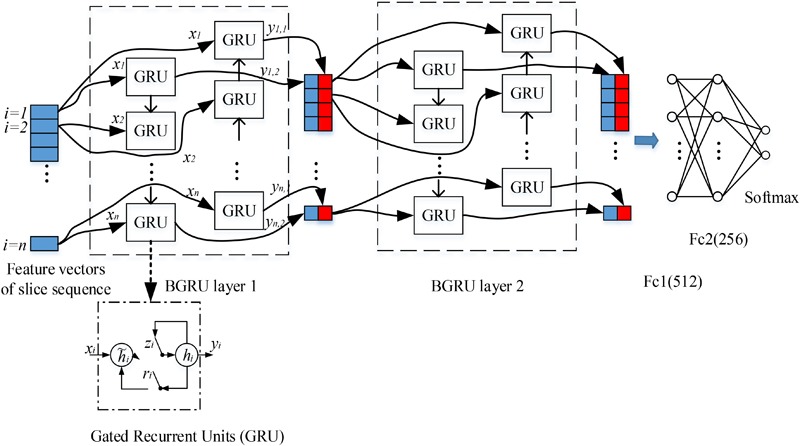
Our deep recurrent neural network (RNN) based on two stacked layers of bidirectional gated recurrent units (BGRU), where xi are the feature vectors generated from image slice i as the inputs of BGRU while yi1 and yi2 are the output feature vectors of GRU from two directions (the internal structure of GRU is shown in the bottom, where ri, zi, hi and hi are the reset gate, update gate, candidate hidden layer and output layer, respectively). On top of stacked BGRU layers, two fully connected layers and one softmax layer are appended for classification prediction.