
Figure 2.
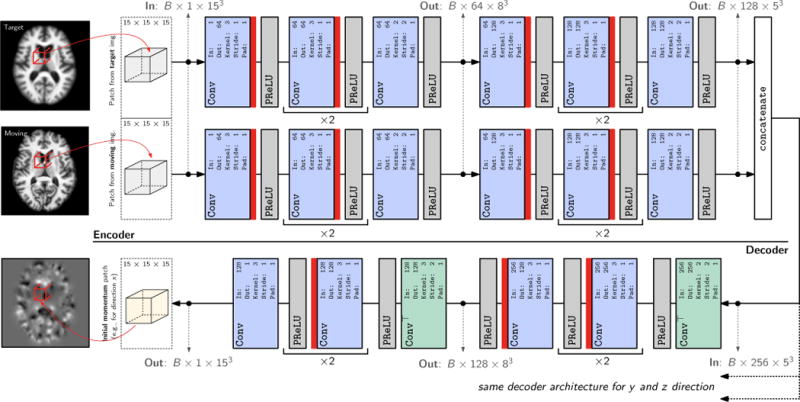
3D (probabilistic) network architecture. The network takes two 3D patches from the moving and target image as the input, and outputs 3 3D initial momentum patches (one for each of the x,y and z dimensions respectively; for readability, only one decoder branch is shown in the figure). In case of the deterministic network, see Sec. 2.2.1, the dropout layers, illustrated by
 , are removed.
Conv: 3D convolution layer.
ConvT: 3D transposed convolution layer. Parameters for the
Conv and
ConvT layers:
In: input channel.
Out: output channel.
Kernel: 3D filter kernel size in each dimension.
Stride: stride for the 3D convolution.
Pad: zero-padding added to the boundaries of the input patch. Note that in this illustration B denotes the batch size.
, are removed.
Conv: 3D convolution layer.
ConvT: 3D transposed convolution layer. Parameters for the
Conv and
ConvT layers:
In: input channel.
Out: output channel.
Kernel: 3D filter kernel size in each dimension.
Stride: stride for the 3D convolution.
Pad: zero-padding added to the boundaries of the input patch. Note that in this illustration B denotes the batch size.