
Figure 3.
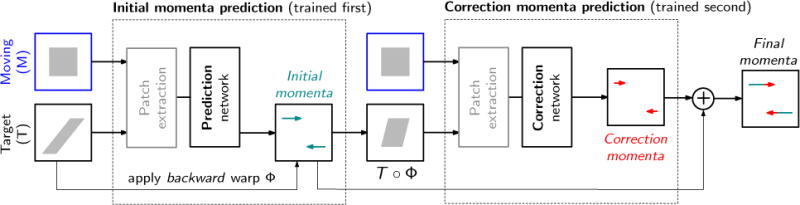
The full prediction + correction architecture for LDDMM momenta. First, a rough prediction of the initial momentum, mLP, is obtained by the prediction network (LP) based on the patches from the unaligned moving image, M and target image, T, respectively. The resulting deformation maps Φ−1 and Φ are computed by shooting. Φ is then applied to the target image to warp it to the space of the moving image. A second correction network is then applied to patches from the moving image M and the warped target image T ○ Φ to predict a correction of the initial momentum, mC in the space of the moving image, M. The final momentum is then simply the sum of the predicted momenta, m = mLP + mC, which parameterizes a geodesic between the moving image and the target image.