
Figure 2.
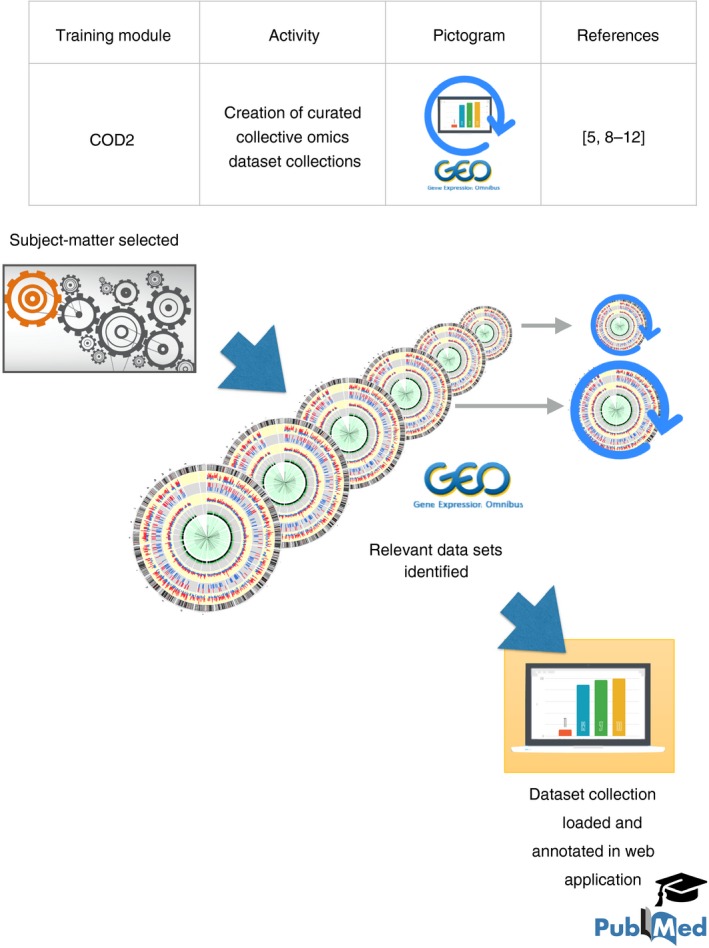
‘Collective Omics Data’ training module 2 (COD2). This activity focuses on the development of skills and demonstrable experience in identification, retrieval and management of collective omics data. Trainees select a subject matter in a first step. In a second step they identify and retrieve data sets from the > 90 000 that have been deposited in GEO. Next, the selected data sets are loaded on a data‐browsing application, such as GXB, which is referenced in the text. Data sets and samples are annotated and organized and this curated dataset compendium is made available publicly along with a peer‐reviewed data note describing the resource. A graphical element used in this figure was adapted from Akula et al.16 Licensed obtained from Springer Nature on May 16, 2018. License number 4350660730175.