
Figure 3. A flow diagram illustrating the prediction framework.
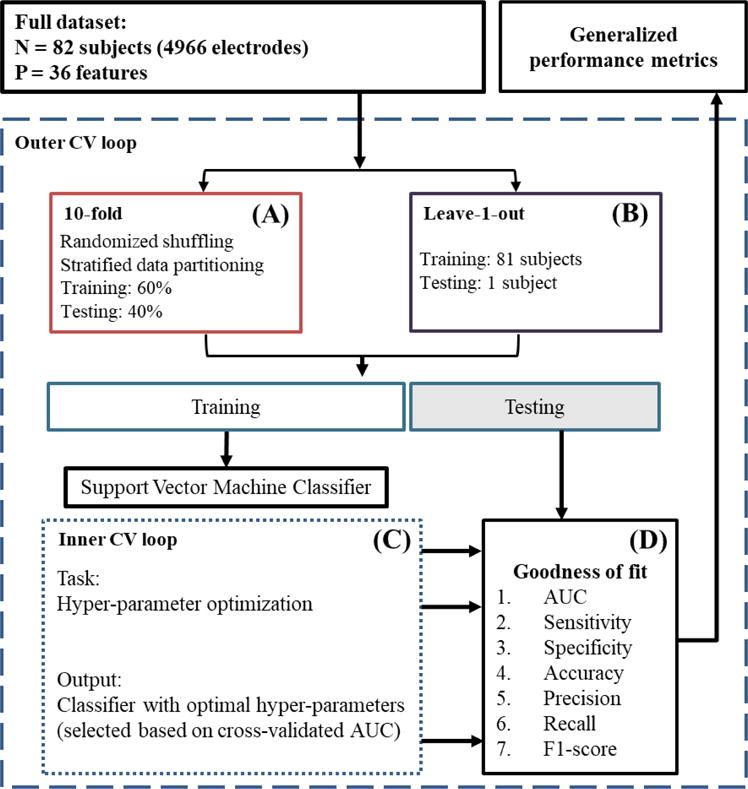
The input is the whole dataset, including the 36 features extracted from 82 subjects (4966 channels) and their gold-standard labels assigned by clinical epileptologists. (A) 10-fold cross-validation: first, the dataset is shuffled to randomize the order of channels in it. After randomization, the dataset is partitioned into two sets, a 60% training set and a 40% testing set, keeping the same proportion of NSOZ and SOZ channels in both sets. (C) Inner CV loop: A set of optimal hyper-parameters is selected for the SVM classifier based on a tenfold cross-validation within the training set. (D) Goodness-of-fit metrics: The classifier learned in the previous step is tested on the testing dataset, and measures of its performance are generated. This whole procedure is repeated 10 times (i.e., 10-fold CV) or 82 times (i.e., leave-1-out CV) to produce generalized performance metrics, eliminating any bias introduced by a specific split of training and testing sets.