
Figure 2: Replay produce extended trajectories in forward and reverse directions.
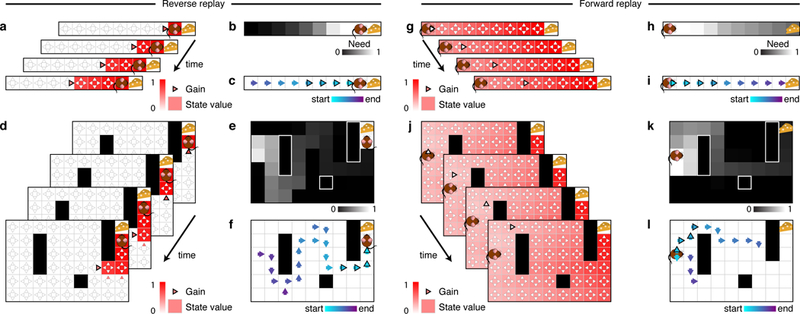
(a-f) Example of reverse replay. (g-l) Example of forward replay. (a,d) Gain term and state values. Notice that the gain term is specific for each action (triangles), and that it may change after each backup due to its dependence on the current state values. Replay of the last action executed before finding an unexpected reward often has a positive gain because the corresponding backup will cause the agent to more likely repeat that action in the future. Once this backup is executed, the value of the preceding state is updated and replaying actions leading to this updated state will have a positive gain. Repeated iterations of this procedure lead to a pattern of replay that extends in the reverse direction. The highlighted triangle indicates the action selected for value updating. (g,j) If gain differences are smaller than need differences, the need term dominates and sequences will tend to extend in the forward direction. (b,e,h,k) Need term. Notice that the need term is specific for each state and does not change after each backup due to being fully determined by the current state of the agent. The need term prioritizes backups near the agent and extends forwards through states the agent is expected to visit in the future. In the field, the need term is also responsible for sequences expanding in a depth-first manner as opposed to breadth-first. (c,f) Example reverse sequences obtained in the linear track (c) and open field (f). (i,l) Example forward sequences obtained in the linear track (i) and open field (l). Notice that forward sequences tend to follow agent’s previous behavior but may also find new paths towards the goal.