
Figure 1.
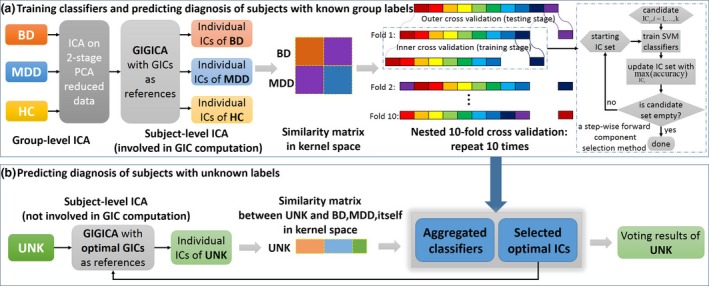
Flowchart of method. (a) Training classifiers and predicting diagnosis of subjects with known group labels. The training stage is composed of four parts as mentioned. Group independent component analysis (ICA) is computed on temporally concatenated fMRI data of bipolar disorder (BD) patients, major depressive disorder (MDD) patients, and healthy controls (HCs) resulting in individual subject maps computed by GIG‐ICA 17. Note that the UNK subjects were not involved in the computation of the group‐level ICA. For each cross‐validation loop, similarity matrices for BD, MDD were computed and classified via a kernel support vector machine (SVM) from the hold‐out data using 10‐fold cross‐validation. Namely, inner loop (dotted line frame) generated 9 SVM models, and a whole nested 10‐fold cross‐validation generated 90 SVM models. After repeating 10 times, 900 SVM classifiers were generated for the majority voting in prediction. (b) Predicting diagnosis of subjects with unknown labels. Following group ICA and individual subject map calculation, a similarity matrix between the UNK and the BD and MDD individuals was computed. Diagnosis of the UNK group was based on a majority voting mechanism using an ensemble classifier with a hypothesis supposing each UNK individual were either BD or MDD due to total blind diagnosis prediction of our binary classification method. [Colour figure can be viewed at wileyonlinelibrary.com]