
Figure 1.
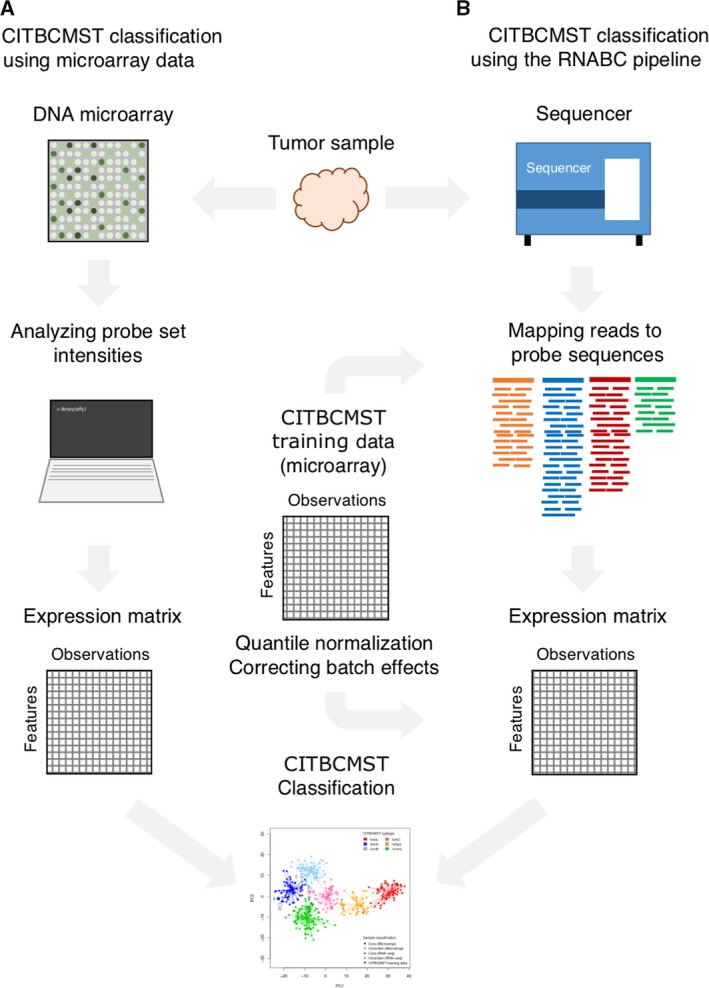
Pipelines for using CITBCMST classifier using (A) microarray data and (B) RNA‐Seq data with the RNABC pipeline. For microarray data, processed samples are submitted to the CITBCMST R package and the resulting subtype predictions are returned. In the RNABC pipeline, raw RNA‐Seq data are submitted, reads are mapped to probe target sequences using kallisto, read counts are quantile normalized and batch corrected using the CITBCMST training data (n = 355) as comparison, and classification is done on transformed counts.