
Figure 1. Illustration of several machine learning techniques commonly used to identify health outcomes from electronic health data.
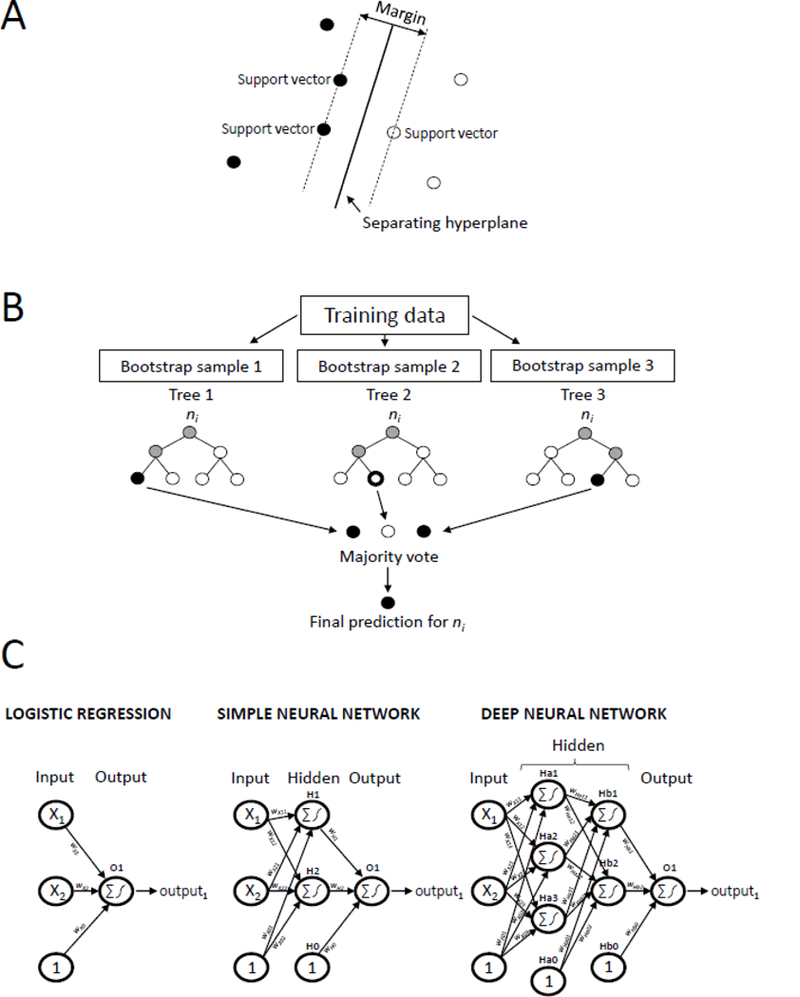
Panel A shows the architecture of a support vector machine, which classifies observations by finding the separating hyperplane with the largest margin between observations of different outcome classes on either side of it in the covariate space. Panel B shows the architecture of a random forest, which averages the predictions across a collection of decision trees, where each tree is trained on a bootstrap sample of the data. Panel C shows the similarities between the architectures of a logistic regression model (left), simple neural network (middle), and deep neural network (right). Nodes (represented by circles) are connected to subsequent nodes by a connection weight, w. Nodes in the input layer correspond to the variables presented to the model. Nodes with a ‘1’ represent bias terms. Nodes in the hidden and output layers take the weighted sum of its input nodes and pass this value through an activation function (eg, the logistic function) to produce its output. Logistic regression models do not contain any hidden layers, simple neural networks contain one hidden layer with any number of hidden nodes, while deep neural networks contain two or more hidden layers, each with any number of hidden nodes.